Docker系列——Grafana+Prometheus+Node-exporter微信推送
Posted 温一壶清酒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Docker系列——Grafana+Prometheus+Node-exporter微信推送相关的知识,希望对你有一定的参考价值。
在之前博文中,已经成功的实现了邮件推送。目前主流的办公终端,就是企业微信、钉钉、飞书。今天来分享下微信推送,我们具体来看。
企业微信
在配置企业微信推送时,需要有微信企业,具体如何注册、使用,另外百度就好,在这里就不多说了。
添加机器人
登录企业微信管理后台,获取配置项基础信息。
- 创建应用
点击应用管理>应用>创建应用,如下所示:

填写对应信息,配置应该logo、名称、以及应用的可见范围,如下所示:

- 获取AgentId和Secret
应用创建成功后,可以查看应用详情,如下所示:

我们从图中可以看到,有AgentId,AgentId先复制保存下,后续会用到;还有Secret,获取Secret,点击查看后,Secret是发送到企业微信中的,自己到微信终端中查看即可。
- 获取corp_id
在我的企业中查看,有个企业id字段,以xx开头。
- 获取部门id
在通讯录中查看,查看部门信息,如下所示:

配置文件
基础信息拿到后,可能会有疑问,拿这些基础信息有什么用。不要急,接下来的配置就需要,我们来细看。
在之前原有的邮件配置基础上,再来进一步修改,添加 wechat_configs 内容,如下所示:
global:
resolve_timeout: 5m
smtp_from: \'{{ template "email.from" . }}\'
smtp_smarthost: \'smtp.qq.com:465\'
smtp_auth_username: \'{{ template "email.from" . }}\'
smtp_auth_password: \'\'
smtp_hello: \'qq.com\'
smtp_require_tls: false
wechat_api_url: \'https://qyapi.weixin.qq.com/cgi-bin/\'
wechat_api_secret: \'\'
wechat_api_corp_id: \'\'
templates:
- \'/etc/alertmanager/*.tmpl\'
route:
group_by: [\'alertname\']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: \'email\'
receivers:
- name: \'email\'
email_configs:
- to: \'{{ template "email.to" . }}\'
html: \'{{ template "email.html" . }}\'
send_resolved: true
headers: { Subject: "{{ .CommonAnnotations.summary }}" }
wechat_configs:
- send_resolved: true
to_party: \'8\'
to_user: \'@all\'
agent_id: \'\'
corp_id: \'\'
api_secret: \'\'
api_url: \'https://qyapi.weixin.qq.com/cgi-bin/\'
参数解析:
- to_party 部门id
- agent_id 应用id
- api_secret 应用Secret
- corp_id 企业id
- api_url 企业微信固定写法
- to_user 接收人
配置后,需要重启alter manager服务,使配置生效。
消息推送
配置好后,我们来触发个条件,而使消息推送,来验证下配置是否有效。
触发条件一样,将node服务停止,使其触发,具体可查看上一篇博文,有详细介绍。Docker系列——Grafana+Prometheus+Node-exporter服务器告警中心(二)
服务停止后,通过 Prometheus 消息中心推送消息,如下所示:

消息内容多,模板不精简,但收到消息,说明配置是没问题的,功能已实现。
引用模板
在之前修改过邮件模板,在这里,我们也修改下微信推送的模板,使其简明扼要一些。
创建模板文件,同样在 alertmanager 目录下,使用命令vim wecaht.tmpl,添加如下内容:
{{ define "wechat.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
@警报
实例: {{ .Labels.instance }}
信息: {{ .Annotations.summary }}
详情: {{ .Annotations.description }}
时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
@恢复
实例: {{ .Labels.instance }}
信息: {{ .Annotations.summary }}
时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
{{- end }}
由于之前出现过日期问题,所以这里就先加上,避免再出现日期那样的错误了,不能一直往里跳。
配置好模板后,需要在altermanager配置文件中引用该模板,wechat_configs中增加如下内容,引用模板:
message: \'{{ template "wechat.html" . }}\'
如果模板跟altermanager配置文件不在同一个目录下,则需要挂载,由于我配置在一个目录下,就不需要重新挂载了,只需要重启服务即可,使其生效。
再次停用node服务,查看消息推送,告警消息如下所示:

恢复消息如下所示:

引用了模板后,内容是不是要精简很多。
内存监控
一直关注我的朋友,可能会吐槽了,怎么老是拿node服务来写demo,能不能来个实际案例。我想着也是,学了就要用起来。服务器中有很多指标都可以监控,比如:内存、CPU、I/O、网络等。今天来个内存监控,具体来看。
其实监控不难,通过两篇博文,也已知道是怎么回事了,主要是配置规则而已。那规则怎么配置呢,来看如下内容:
groups:
- name: hostStatsAlert
rules:
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
- alert: node-up
expr: up{job="linux"} == 0
for: 15s
labels:
severity: page
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s!"
description: "{{ $labels.instance }} 检测到异常停止!请重点关注!!!"
上述示例 hostMemUsageAlert 规则,添加到/prometheus/rules目录下的规则中,并重启Prometheus服务,使配置生效。
重启后,通过Prometheus服务查看规则,如下所示:

注意:规则配置内存使用率超过85%则会出发警报,如果大家的服务器内存够大,目前使用率不高,但又想检测下规则是否能正常触发,将85降低即可。
我这里配置的85,我们来看下最终效果图,如下所示:
告警信息

恢复信息
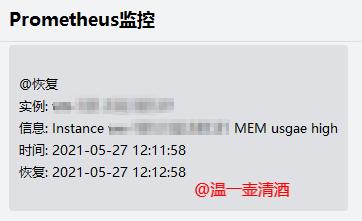
内存监控,按上述步骤就实现了,是不是就是一个规则的事情,其他指标监控也同理。
好了,今天分享就到这了,下期再会。
以上是关于Docker系列——Grafana+Prometheus+Node-exporter微信推送的主要内容,如果未能解决你的问题,请参考以下文章