阿里云弹性计算研发团队如何从0到1自建SRE体系
Posted 弹性计算百晓生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云弹性计算研发团队如何从0到1自建SRE体系相关的知识,希望对你有一定的参考价值。
SRE 最早在十多年前 Google 提出并应用,近几年随着 DevOps 的发展,SRE 开始被大家熟知。而在国内,非常多的 SRE 部门与传统运维部门职责类似,本质来说负责的是互联网服务背后的技术运维工作。构建区别于传统运维的 SRE、如何在业务研发团队落地SRE,是许多企业都在攻克的难题。
本届全球运维大会 GOPS 上,阿里云弹性计算团队技术专家杨泽强以《大型研发团队SRE 探索与实践》为题,分享了在 SRE 体系建设上的思考和落地实践。
本文为演讲内容整理,将从以下三部分进行介绍:
-
阿里云弹性计算(ECS)自建 SRE 体系的原因;
-
ECS 建设 SRE 体系的探索与实践;
-
以弹性计算 SRE 体系建设的四年经验为例分享对 SRE 未来的看法。
为什么ECS要自建SRE体系?
ECS 团队之所以会单独建 SRE,与产品业务特性以及组织层面上的背景有关。
下图展示了 ECS 的业务特点:
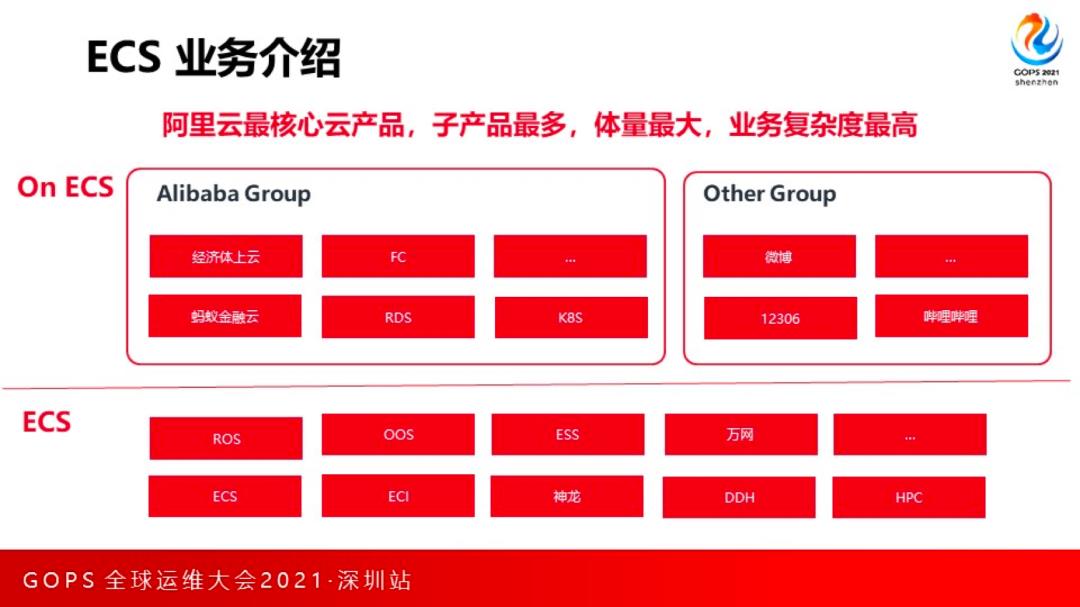
首先,从产品业务来看,ECS 是阿里云最大最核心的云产品。ECS 作为阿里巴巴经济体的以及其它部署在 ECS 上的云产品的底座,也支撑了国内外非常多的业务。阿里云全球份额排名第三,其中 ECS 的贡献毫无悬念是排名第一的,ECS 作为基础设施底座,稳定性要求特别高。
其次,由于阿里内部的经济体上云和整个云计算普及,ECS 对外的 OpenAPI 调用量每年都出现数倍增长,这意味着系统的容量每年都会面临新的挑战。
而与此同时,阿里云弹性计算启动了去 PE 的组织调整,即业务团队没有专职的运维工程师以及系统工程师,这将意味着运维类的事情、系统架构规划与横向产品需要有团队来承接。
ECS 建设 SRE 体系的探索与实践
从 2018 年刚开始建设至今,在一路的摸索中,ECS 的 SRE 体系建设借鉴了 Google 和Netflix 的做法,并结合团队和业务的特性,最终 SRE 体系可以简单概况为下图的五个层次:

-
打基础。阿里云的文化主张里有一句话是“基础不牢,地动山摇”。在团队里具体的事情就是全链路稳定性治理体系以及性能容量工程,也是重要的基础。
-
定标准。这在一个大型研发团队里非常重要, ECS团队主要从软件的生命完整生命周期来看,从设计->编码->CR->测试->部署->运维->下线,各个环节定义了标准。通过定期的技术培训和定期运营,先在意识上给大家普及,同时会通过小团队的试运行来看效果,如果符合预期就想办法自动化掉。
-
建平台。通过建设自动化平台来不断释放SRE的人肉工作。
-
做赋能。业务团队的SRE除了做好横向的基础组件和自动化平台外,还要做很多推广和协助业务研发的事情;同时SRE每天都要处理非常多的预警响应,线上问题排障以及故障响应,如何把SRE的价值最大化,我觉得最核心的是赋能。
-
建团队。最后我将以弹性计算为例介绍一下SRE团队的职责,文化理念以及如何成为一名合格的SRE。
打基础
基础框架建设与性能调优
弹性计算的核心业务都是 Java 技术栈,还有少部分 golang 和 python,本质上是一个Java 研发大型分布式系统。在内部为了支撑业务规模和尽可能的抽象整合,我们自研了一系列基础框架给业务同学使用,包括轻量bpm框架、幂等框架、缓存框架、数据清理框架等,其中每个框架的抽象和设计我们都考虑了规模化容量的支撑以及小型化的输出,以工作流框架为例,我们支持了每天数亿工作流的创建运行,框架调度开销做到了5ms级别。
除了基础框架,在性能优化上针对 JVM 进行了一系列调优,比如针对IO密集型的应用开启了wisp协程,以及针对每个核心应用JVM进行调优,减少STW的时间。
另外,从服务性能角度,数据层,我们对全网超过100ms的慢SQL进行了调优;应用层,我们针对核心链路提供了多级缓存方案,可以保障最热的数据可以从内存里最快的返回;业务层,我们通过提供批量API以及异步化改造。
全链路稳定性治理
上图罗列了几个比较典型的点,比如预警治理,普遍问题是预警量太大了,信噪比又不高,预警能提供的信息非常有限,对于排查排障帮助比较局限。
早年间,我们也面临同样的问题,分享预警治理的两个真实故事:
-
一个核心应用的数据库在晚上down了,但预警配置的通知渠道是email和旺旺,并且接收人不是当前应用owner,导致owner在发现故障问题的时候花了非常长时间定位到是数据库问题。
-
之前发生了一起全链路连锁反应的故障,故障发生的起因是其中某一个业务导致的,当时我们花了两个小时来定位和恢复问题,在事后复盘才发现故障开始前5分钟,已经有相关报警,但该报警接收同学的预警量太大,漏掉了重要预警。
所以,稳定性治理很重要的一部分就是预警治理,主要治理的方法就是监控分层、统一预警配置平台、统一预警优化配置策略,比如预警的接收人、通知方式等。
数据库稳定性治理
数据库是应用的命脉,发生在数据库上的故障往往非常致命。不论是数据的准确性或者数据的可用性受损,给业务带来的灾难通常是毁灭性的。
两个难题:慢SQL和大表
当在使用mysql做数据存储的时候,最高频遇到的场景就是慢SQL和大表这两个难题。慢SQL会导致业务变慢甚至产生全链路的连锁反应导致雪崩,而大表问题和慢SQL通常也分不开,当表的数据量大到一定程度,MySQL的优化器在做索引选择的时候也会遇到一些奇怪的问题,所以在数据库的治理上基本围绕慢SQL和大表。
针对慢SQL的治理方案
大致的解法是把采集的慢SQL同步到SLS上,通过SLS做近实时的慢SQL分析,然后通过库表信息把慢SQL分给指定团队来修复,这个过程SRE同学会给出优化方案以及通用的基础组件,比如针对大页查询的提供bigcache以及nexttoken方案,针对热点数据的common cache以及读写分离降级能力。
针对大表的治理方案
针对大表问题,业界通常的解决方案是分库分表,但是其带来的研发和运维成本很高,我们内部一般业务更常用的方式是通过历史数据归档来做,在这里SRE也有统一的基础框架提供,业务方只需要给出数据归档条件以及触发频率,框架会自动将历史数据归档到离线库并把业务库数据做物理删除,这样通过腾挪数据空洞来达到空间的一定复用,保障有限的数据空间不扩容的前提来支撑业务的发展。
高可用体系
分布式系统的高可用可以分四个层次来看。从最底层的部署层,由下至上分别是运行时、数据层、业务层,我们的高可用体系也是按照四个层次来划分的。
-
部署层,作为ECS的研发我们对外推荐的最佳实践都是多可用区部署,理由很简单,因为容灾性更好、更柔性。
-
数据层,如前面提到的数据库稳定性治理,我们数据层一方面的工作就围绕像慢SQL、热点SQL和大表的持续治理,另外一方面就是从技术架构上我们做了多读和读写自动降级框架,可以将一些大表查询自动降级到只读库,同时可以保障读写库异常情况,核心API仍然可以通过只读库提供服务,进而来保障数据库整体的高可用。
-
业务层的高可用体系,一个复杂的分布式系统,难题之一就是解决依赖的复杂性,如何在依赖方不稳定的情况下仍然保障或者有损保障自身的核心业务可以玩转,这是分布式业务系统非常有挑战与有意义的一件事情。
故障案例
我们曾经出过一个故障,一个核心系统被一个非常不起眼的边缘业务场景搞到雪崩。核心系统里引入了一个三方系统依赖,当依赖方服务RT变慢的时候,我们所有的HTTP请求由于设置的超时时间不合理全部阻塞,进而导致所有线程都block在等待该服务返回,结果就是所有服务RT变长,直至不再响应。
要知道在庞大的分布式系统里,没有绝对可靠的授信链,我们的设计理念就是Design For Failure,以及Failure as a service。
可参考以下思路:
-
在设计阶段时定义该依赖的性质,是强依赖还是弱依赖
-
对方提供的SLO/SLA是什么,依赖方可能会出现什么问题以及对我们服务的影响是什么?
-
如果依赖方出现了预期/非预期的异常,我们的策略是什么?
如何保障我们服务的最大可用性。
最大可用性,意味着做出的响应可能有损,比如对端是弱依赖,我们可能会直接降级,返回一个mock结果,如果对端是强依赖,我们可能采取的是隔离或者熔断策略,快速失败部分请求,并尽可能记录更多信息,方便后续通过离线方式进行补偿。
定标准
弹性计算的研发人员大概是百人以上规模,同时还会有一些兄弟团队以及外包人员一起参与研发,自SRE建设的第一天我们就开始逐步建立各种研发标准和流程。
以UT标准案例为例,UT缺失导致的故障占比高;难度是量大,研发不重视,实际没办法收敛。解法是通过建立UT标准,和CI自动化体系,量化指标来持续改进。效果是UT缺失导致的故障大幅降低,从占比30%降低至不到0.3%。

研发流程体系
我们从设计到发布几乎各个环境都定义了一套标准。
1.设计阶段。我们统一定义了一套设计文档模版来规范和约束研发人员。从软件工程角度来看,越早引入问题带来的成本越低,所以我们的研发原则之一也是重设计。一个好的设计不仅要从业务上定义清楚问题,定义清楚UserStory和UserCase以及约束,从技术角度也要清楚的讲清楚技术方案的tradeoff以及Design for failre如何实现、如何灰度、监控回滚等等。我们希望研发多在设计阶段下功夫,少在中途返工或者发布后打补丁。同时我们的评审机制也从线下大团队评审转变为小团队线下+大团队直播方式进行,尽可能少开会,节约大家时间。
2.研发阶段。我们的研发流程类似git-flow。是多feature并行开发,开发测试后合并进入develop分支,每天会有统一的流程基于develop进行daily deploy,我们基于阿里集团的Java规约做了扩展,加入了自定义的静态扫描规则,同时统一的UT框架,实现了CR后自动运行规约扫描执行静态检查,同时运行CI产出UT运行报告,只有静态扫描,CI结果主要是UT成功率和行增量覆盖率以及代码点赞数同时满足条件MR才会被合并,进入下次发布list。
3.测试阶段。主要分日常测试,预发测试以及上线前的功能测试以及灰度期间的回归测试。大规模研发团队大家面临的难题就是环境怎么搞?这么快速复制以及隔离?以往模式下我们只有一套日常和预发,经常出现某个人代码问题或者多人代码冲突导致测试特别耗时。后来我们做了项目环境,简单功能可以通过容器方式快速复制全链路项目环境。针对有全链路联调需求的case,我们扩展了多套预发环境,可以做到每个业务研发团队一套预发,大家互相不争抢,这样预发的问题就解决了。
上线前的功能测试主要是针对daily deploy的,我们会在每天晚上11点自动从develop拉取分支,并部署到预发环境,同时这个时候会自动运行全量的功能测试用例来保障发布的可靠性,在日常发布如果FVT非预期失败,会导致发布取消。
最后一个测试流程是灰度期间自动回归core fvt,我们的发布是滚动发布模式,通常会灰度一个地域来做灰度验证,core fvt就是做这个的,当core fvt运行通过后可以进行后续批次发布,反之判断是否回滚。

变更流程体系
在SRE建设的时候,我们特意规划了变更管控流程。针对当前的变更类型做了不同的标准要求,比如数据库变更checklist+review机制,日常发布/hotfix/回滚的批次以及暂停时长,还有就是中间件的配置规范以及黑屏变更等。
有了变更流程和规范只是第一步,接着我们针对高频率的运维操作做了工具化建设,其中有部分和现有的DevOps平台合作,游离在现DevOps之外的部分我们都自己做了研发支持,比如日志清理以及进程自动重启,并开发了自动化工具可以自动化清理大文件以及重启故障进程。
举一个例子就是数据订正,数据都是通过异步编排来实现最终一致性,所以数据订正会是一个特别高频的变更,简单的一条订正SQL蕴藏的威力有时候超过我们的想象,我们之前有一个故障就是因为一条数据订正错误导致,影响非常严重,排障过程也非常困难。
建平台
SRE 自动化平台
我们做SRE自动化平台就是为了将标准通过自动化方式来实现,比如研发阶段的高可用体系里的读写降级,限流等。我们在提供框架能力的同时,提供了运维接口和白屏化工具,帮助研发实现自动化/半自动化的高可用能力。
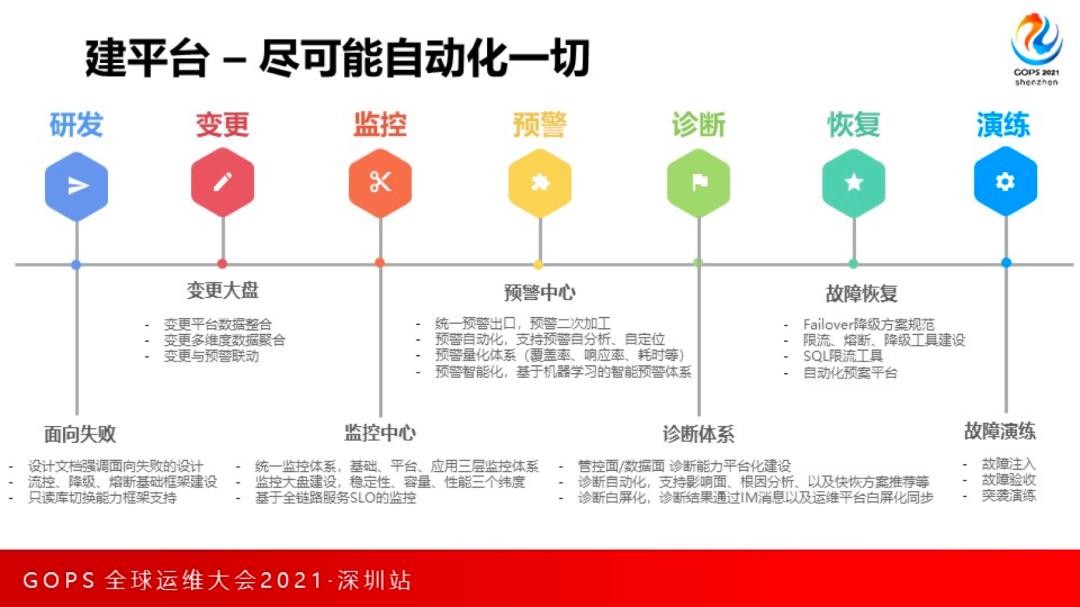
弹性计算团队的1-5-10指标
后面的变更、监控、预警、诊断、恢复,对应的就是MTTR的各个细分阶段,在阿里集团有个1-5-10的指标,意思就是分钟发现问题,5分钟定位问题,和10分钟恢复问题,这是一个非常难达到的高标准。
弹性计算团队为了满足提升1-5-10指标,建立了自己的监控平台和预警平台。我们做的是预警能力的二次消费,将所有的基础监控包括系统指标cpu和mem、JVM监控以及各种中间件监控,还有非常多的业务监控做了分层,而每一个预警都会囊括各种meta信息,比如归属团队、重要性、关联的诊断场景、快恢策略,以及推荐的变更等。
这就闭环了变更、预警、诊断、快恢整个过程。当一条预警出现的时候可以自动根据TraceID分析全链路寻找局点,同时推荐相关变更,并生成影响面比如多少API、用户是哪些,以及该预警推荐的解决方案是什么,同时提供一个hook可以执行快恢动作。
举个例子,有位同学订正了一条业务,sql写的问题有问题,导致线上几个大客户的服务异常,在sql执行完的几秒内我们的监控系统就识别出了业务异常,并产生了预警信息以及预警的stack和影响面分析,同时关联的数据库变更信息也被推荐了出来,这些信息组合在一起的1分钟内我们就定位到了问题,并立马执行了回滚,业务很快就恢复了。当然该平台目前仍然有局限性,我们今年规划会做更多智能预警和诊断的事情。
最后,必须要提一下演练,即混沌工程 Chaos engineering,最早由Netflix提出。在过去的两年里,我们通过故障演练,故障注入的方式多次回放了历史故障,同时对发现线上问题也非常有帮助,故障演练现在已经作为一个常态化的事情融入到了日常。
分享完我们的SRE自动化平台体系,有了平台之后,非常重要的一个事情就是赋能。
我认为业务团队SRE最大的价值就是赋能,通过赋能来使众人行。

做赋能
全链路SLO量化体系
ECS的上下游依赖方众多,任何一个环境出现不稳定都会影响ECS出口服务的稳定性。
举个例子ECS向下对接的是虚拟化和块存储,只要虚拟化和快存储慢了体现用户层面就是ECS实例启动慢了,而这个快慢究竟如何评定呢?可能对于我们做分布式服务来说可能觉得5ms已经很慢了,但是对于虚拟化来说他认为我这个接口1s都是正常的,这个时候就需要SLA了。
做SRE的第二年,我们梳理了全链路数十个依赖以及数百个核心API与各个业务方选择最关心的指标也就是SLI,针对不同的置信空间设置了SLO值,并且建设了统一的量化平台,通过实时与离线方式持续跟进起来。通过SLO体系建立到持续运营的一年多时间,我们的依赖方可用性和时延的SLO达标率从最初的40%多治理到98%以上。这个直接产生的业务就是我们对用户API成功率的提升,用户的体感更加好了。
落地SLO的四个阶段
-
选取SLI,即和你的依赖方确定哪些指标是需要关注的,比如通常都关心的可用性和时延;
-
和依赖方约定SLO,即明确某个API某个SLI的目标值 P99、P999分别是什么;
-
计算SLO,通常的方式都是通过记录日志,将日志采集到SLS,通过数据清洗再加工计算出指标值。
-
可视化,通过将SLO做成实时/离线的实时报表,来做持续跟进。
SRE 很大的一部分职责在于故障排查和疑难问题处理,同时我们做了一系列框架和工具,还要非常多的运维手册以及故障复盘的资料,这些我们都按照统一模版沉淀下来,可以用来指导研发同学日常问题排查和变更使用,其中部分文档我们还共享给了阿里云其它产品。
通过知识库我们也赋能了非常多的兄弟团队,另外我们研发过程中的很多业务基础组件像工作流、幂等、缓存、降级、Dataclean 等框架也都有阿里云其它团队在使用。

稳定性文化建设
SRE 是稳定性的捍卫者,也是布道师。只有人人都意识到稳定性的重要性,我们的系统才可能真正的稳定。我们从建设 SRE 团队的第一天就开始建流程,团队内通过日报,周报,月报以及不定期的线上直播以及线下培训来宣传稳定性文化。逐步在团队形成我们特有的稳定性文化,比如 Code Review 文化,安全生产文化和事后故障复盘文化。
故障复盘实践
在 SRE 初期,我们开始推行故障复盘。我们对于故障的定义是所有有损业务或者人效的异常 case 都是故障。一开始,故障复盘由 SRE 主导,由业务团队配合,但整个过程非常不愉快。
随着后面 SRE 的一些自动化工具以及一些流程真正帮助了研发避免故障,以及在故障复盘过程中 SRE 的一些见解给到了研发正向反馈,慢慢故障复盘的文化在团队开始慢慢被接受,各个业务自己会写故障复盘报告,并开直播分享,其它团队的同学也会非常积极地给反馈。文化真正的深入人心后,产生的会是非常好的良性循环。
建团队
最后分享一下SRE团队组建主要注意的几个方面。

人
在弹性计算团队,我们对 SRE 的要求是T型人才,要一专多能。
-
精通一门编程语言
-
两个基本能力:抽象能力、标准化能力
-
拥有全局视野,具备赋能意识
事
事,基本上即是前面提到的建标准、建自动化平台、做基础服务和赋能业务团队,还有on-call支持等日常工作。
同时,我们需要在团队中建立几个共同的核心理念,我个人认为SRE几条最核心的理念:

-
稳定性就是产品,稳定性不是一锤子买卖。SRE 要做的是赋予稳定性产品的灵魂,要按照产品一样去养育,去不断迭代,去持续演进。
-
软件工程的方法论解决生产系统稳定性问题。SRE 区别于业务研发和运维的很大一点是,SRE 解决的是生产环境的稳定性问题,是通过软件工程的方法论来重新定义运维模型。
-
自动化一切耗费团队的事情。SRE 的精髓在于软件工程定义运维,通过自动化以及赋能业务来最大化价值。
SRE 建设的回顾与个人展望
简单概括下弹性计算团队四年的 SRE 发展历程就是,建体系-量化-自动化-智能化。
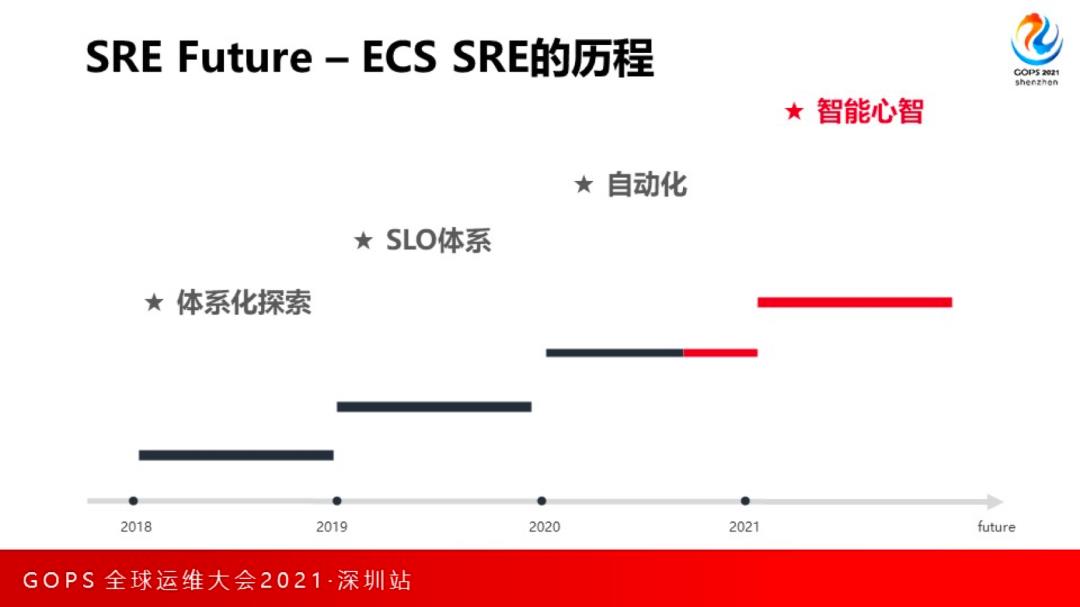
第一年:体系化探索
这一年主要的工作就是从0-1结合当前业务和团队的现状把SRE体系建设起来,比如基础框架的统一建设,稳定性治理体系。
第二年:SLO体系
第二年的重点主要是针对全链路数十个系统依赖,以及内部系统的核心功能定义了SLO(service level object,SLO)量化体系,并跨BU完成了整个链路的SLO量化体系建设。同时开始重点建设稳定性运营体系,以及自己的数据运营平台,将内外部核心依赖的核心API的可用性,时延的数据全部量化并持续跟进治理起来。
第三年:自动化
我们把研发过程中从设计、编码、测试、部署到上线后的预警响应等所有需要人工参与的事情都做了尽可能的自动化。比如在CR阶段加入UT覆盖率卡点,不符合标准的CR会自动拦截。在发布阶段接入了无人值守,根据发布期错误日志的情况来进行发布拦截,当然这里更好的方式可能是通过灰度机器的服务SLA等综合指标来判断。另外,在灰度地域发布暂停期间,我们会自动化运行corefvt来回归核心测试用例验证发布的可靠性,异常情况会自动拦截灰度,并推荐一键回滚操作。
第四年:智能心智
今年我们正在做的一些事情是高度自动化,比如无人发布值守,还有自动化预警根因分析等。当我布式系统规模足够大,应用复杂度足够高的时候,靠人的判断是非常困难的。所以,SRE要建设的自动化平台要有智能心智,通过系统化的能力来代替甚至超越人。
对SRE未来发展的个人看法:
-
稳定性即产品,我们真正是需要把稳定性当作产品来看待的,做产品意味着我们要清楚的定义问题,并产生解决方案,并且持续的迭代演讲,这不是一锤子买卖,是需要养育的。
-
我觉得随着云计算的普及,SRE的技能会倾向于研发技能,当然系统工程的能力也是必须的,因为云计算作为基础设施会帮助我们屏蔽掉非常多的机房、网络、OS层面的问题,这样SRE的重点就在于用软件工程的方法论来重新定义运维,使用自动化来提高效能。
-
Netflix提出了一个CORE SRE的概念,NetFlix是这样解读CORE的,C就是Cloud,我们都知道Netflix是run on AWS,Cloud是基础。
Operation就是运维了,Reliability和Enginering就不多说了。
而我对CORE SRE的另一个解读是少量核心的SRE人员支撑并保障大规模服务的稳定性。
-
少量的SRE支撑大规模服务背后的最核心理念我觉得是自动化,尽可能最大化一切可以自动化的事情,并且要智能的自动化。
总结下稳定性就是,产品 + Dev的比重会增大 + CORE SRE + 自动化一切。
以上就是我今天想要和大家分享的内容,谢谢大家的聆听。
以上是关于阿里云弹性计算研发团队如何从0到1自建SRE体系的主要内容,如果未能解决你的问题,请参考以下文章