Elasticsearch的CRUD
Posted 三才生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch的CRUD相关的知识,希望对你有一定的参考价值。
在http://192.168.232.128:5601/app/dev_tools#/console连接中进行直接数据操作(安装了Kibana)
没有安装的直接连接也可用postman直接连接ES
新增数据
#相关测测试数据
PUT /product/_doc/1
{
"name" : "xiaomi phone",
"desc" : "shouji zhong de zhandouji",
"price" : 3999,
"tags": [ "xingjiabi", "fashao", "buka" ]
}
PUT /product/_doc/2
{
"name" : "xiaomi nfc phone",
"desc" : "zhichi quangongneng nfc,shouji zhong de jianjiji",
"price" : 4999,
"tags": [ "xingjiabi", "fashao", "gongjiaoka" ]
}
PUT /product/_doc/3
{
"name" : "nfc phone",
"desc" : "shouji zhong de hongzhaji",
"price" : 2999,
"tags": [ "xingjiabi", "fashao", "menjinka" ]
}
PUT /product/_doc/4
{
"name" : "xiaomi erji",
"desc" : "erji zhong de huangmenji",
"price" : 999,
"tags": [ "low", "bufangshui", "yinzhicha" ]
}
PUT /product/_doc/5
{
"name" : "hongmi erji",
"desc" : "erji zhong de kendeji",
"price" : 399,
"tags": [ "lowbee", "xuhangduan", "zhiliangx" ]
}
PUT /product/_doc/6
{
"name": "xiaomi 10",
"desc": "zui neng da de xiaomishouji",
"price": 5999,
"tags": ["fashao","xingjiabi"]
}
修改/删除数据
#全量更新id为1的数据
#产生的问题是如果没有全部写上字段,会导致字段数据丢失
PUT /product/_doc/1
{
"name" : "xiaomi phone",
"desc" : "shouji zhong de zhandouji",
"price" : 3999,
"tags": [ "xingjiabi", "fashao", "buka" ]
}
#部分字段更新
POST /product/_update/1
{
"doc":{
"price":2999
}
}
#删除数据
#显示逻辑删除,改变version,在一定时间之后会进行物理删除
DELETE /product/_doc/6
获取数据
#查询所有
GET /product/_search
#Timeout机制:假设用户查询结果有1W条数据,但是需要10ms 才能查询完毕,但是用户设置了1ms 的timeout,那么不管当前一共查询到了多少数据,都会在1ms后ES讲停止查询,并返回当前数据。
#GET /_search?timeout=1s/ms/m
GET /product/_search?timeout=1ms
#分页查询
GET /product/_search?from=0&size=2&sort=price:asc
#带参数查询 name字段包含phone
GET /product/_search?q=name:phone
Query DSL
match all:匹配所有
#获取全部数据
GET /product/_search
{
"query":{
"match_all": {}
}
}
math :包含
#包含nfc数据
GET /product/_search
{
"query": {
"match": {
"name": "nfc"
}
}
}
sort:排序
#按照价格排序
GET /product/_search
{
"query": {
"multi_match": {
"query": "nfc",
"fields": ["name","desc"]
}
},
"sort": [
{
"price": "desc"
}
]
}
multi_match:根据多个字段查询一个关键词
#name和descz字段中包含“nfc”的doc
GET /product/_search
{
"query": {
"multi_match": {
"query": "nfc",
"fields": ["name","desc"]
}
},
"sort": [
{
"price": "desc"
}
]
}
_source 元数据:只返回想要的字段
#查询包含nfc的数据,但是只返回“name”和“price”字段。
GET /product/_search
{
"query":{
"match": {
"name": "nfc"
}
},
"_source": ["name","price"]
}
分页(deep-paging)
#查询第一页(每页两条数据)
GET /product/_search
{
"query":{
"match_all": {}
},
"sort": [
{
"price": "asc"
}
],
"from": 0,
"size": 2
}
Full-text queries:全文检索
query-term:不会被分词
GET /product/_search
{
"query": {
"term": {
"name": "nfc"
}
}
}
match:会被分词
#这里因为没有分词,所以查询没有结果
GET /product/_search
{
"query": {
"term": {
"name": "nfc phone"
}
}
}
#查找必须包含nfc 或phone字段的数据
GET /product/_search
{
"query": {
"bool": {
"must": [
{"term":{"name":"nfc"}},
{"term":{"name":"phone"}}
]
}
}
}
#和上面相同,用数组传递
GET /product/_search
{
"query": {
"terms": {
"name":["nfc","phone"]
}
}
}
# match会自动分词
GET /product/_search
{
"query": {
"match": {
"name": "nfc phone"
}
}
}
全文检索
#查询包含四个单词任意一个的数据
GET /product/_search
{
"query": {
"match": {
"name": "xiaomi nfc zhineng phone"
}
}
}
#验证"xiaomi nfc zhineng phone"会被分成几个词
GET /product/_analyze
{
"analyzer": "standard",
"text": "xiaomi nfc zhineng phone"
}
Phrase search:短语搜索
#“nfc phone”会作为一个短语去检索,不会进行分词
GET /product/_search
{
"query": {
"match_phrase": {
"name": "nfc phone"
}
}
}
Query and filter:查询和过滤
bool:可以组合多个查询条件,bool查询也是采用more_matches_is_better的机制,因此满足must和should子句的文档将会合并起来计算分值。
-
must:必须满足子句(查询),
必须出现在匹配的文档中,并将有助于得分。
-
filter:过滤器 不计算相关度分数,cache。
子句(查询)必须出现在匹配的文档中。但是不像
must查询的分数将被忽略。Filter子句在filter上下文中执行,这意味着计分被忽略,并且子句被考虑用于缓存。 -
should:可能满足 or
-
must_not:必须不满足 不计算相关度分数
子句(查询)不得出现在匹配的文档中。子句在过滤器上下文中执行,这意味着计分被忽略,并且子句被视为用于缓存。由于忽略计分,
0因此将返回所有文档的分数。 -
minimum_should_match:最小匹配度
**如果为0.8, 4个词中必须要命中3个词的就会返回**。 (4*0.8向下取整)
```json
#首先筛选name包含“xiaomi phone”并且价格大于1999的数据(不排序),
#然后搜索name包含“xiaomi”and desc 包含“shouji
GET /product/_search
{
"query": {
"bool":{
"must": [
{"match": { "name": "xiaomi"}},
{"match": {"desc": "shouji"}}
],
"filter": [
{"match_phrase":{"name":"xiaomi phone"}},
{"range": {
"price": {
"gt": 1999
}
}}
]
}
}
}
# bool多条件 name包含xiaomi 不包含erji 描述里包不包含nfc都可以,价钱要大于等于4999
GET /product/_search
{
"query": {
"bool":{
#name中必须包含“xiaomi”
"must": [
{"match": { "name": "xiaomi"}}
],
#name中必须不能包含“erji”
"must_not": [
{"match": { "name": "erji"}}
],
#should中至少满足0个条件,参见下面的minimum_should_match的解释
"should": [
{"match": {
"desc": "nfc"
}}
],
#筛选价格大于4999的doc
"filter": [
{"range": {
"price": {
"gt": 4999
}
}}
]
}
}
}
#查询必须包含nfc,加个在1999~3999之间,最少命中1个词
GET /product/_search
{
"query": {
"bool":{
"must": [
{"match": { "name": "nfc"}}
],
"should": [
{"range": {
"price": {"gt":1999}
}},
{"range": {
"price": {"gt":3999}
}}
],
"minimum_should_match": 1
}
}
}
```
Highlight search
#高亮返回
GET /product/_search
{
"query" : {
"match_phrase" : {
"name" : "nfc phone"
}
},
"highlight":{
"fields":{
"name":{}
}
}
}
Compound queries:组合查询
#一台带NFC功能的 或者 小米的手机 但是不要耳机
GET /product/_search
{
"query": {
"constant_score":{
"filter": {
"bool": {
"should":[
{"term":{"name":"xiaomi"}},
{"term":{"name":"nfc"}}
],
"must_not":[
{"term":{"name":"erji"}}
]
}
},
"boost": 1.2
}
}
}
#搜索一台xiaomi nfc phone或者一台满足 是一台手机 并且 价格小于等于2999
GET /product/_search
{
"query": {
"constant_score": {
"filter": {
"bool":{
"should":[
{"match_phrase":{"name":"xiaomi nfc phone"}},
{
"bool":{
"must":[
{"term":{"name":"phone"}},
{"range":{"price":{"lte":"2999"}}}
]
}
}
]
}
}
}
}
}
Deep paging 深度分页查询
比如一个索引有三个 primary shard,分别存储了6000条数据,我们要得到第100页的数据(每页10条),类似这种情况就叫deep paging。每个 shard 把0到999条数据全部搜索出来(按排序顺序),然后全部返回给 coordinate node,由 coordinate node 按 _score 分数排序后,取出第100页的10条数据,然后返回给客户端。
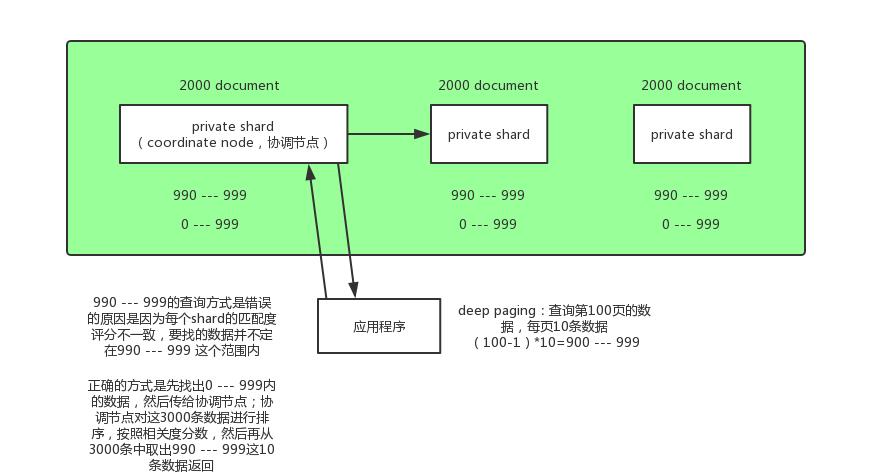
问题
- 消耗网络带宽,因为所搜过深的话,各 shard 要把数据传递给 coordinate node,这个过程是有大量数据传递的,消耗网络。
- 消耗内存,各 shard 要把数据传送给 coordinate node,这个传递回来的数据,是被 coordinate node 保存在内存中的,这样会大量消耗内存。
- 消耗cup,coordinate node 要把传回来的数据进行排序,这个排序过程很消耗cpu。
鉴于deep paging的性能问题,所有应尽量减少使用。
解决方案
Elasticsearch 使用scroll滚动技术实现大数据量搜索、深度分页问题 和 search_after 实现深度分页
基于scroll滚动技术实现大数据量搜索
- scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的
- 采用基于_doc(不使用_score)进行排序的方式,性能较高
- 每次发送scroll请求,我们还需要指定一个scroll参数,指定一个时间窗口,每次搜索请求只要在这个事件窗口内能完成就可以了
GET /product/info/_search?scroll=2m
{
"query":{
"match_all":{
}
},
"sort":["_doc"]
}
# 返回结果
#! [types removal] Specifying types in search requests is deprecated.
{
"_scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFjFKVnZMQ3lvVEw2aXkxaGs1UXN4SUEAAAAAAAASBRY4Nnl2eHRoNlNXU01sTDRXY2JDT0t3",
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
}# 第二次查询通过第一次的快照ID来查询,后面以此类推
GET /_search/scroll
{
"scroll":"1m",
"scroll_id":"FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFjFKVnZMQ3lvVEw2aXkxaGs1UXN4SUEAAAAAAAASBRY4Nnl2eHRoNlNXU01sTDRXY2JDT0t3"
}
scroll_id 的生成可以理解为建立了一个临时的历史快照,在此之后的增删改查等操作不会影响到这个快照的结果。
filter执行原理
场景
举个例子,假设有个字段是date类型的,在倒排索引中:
| word | document1 | document2 | document3 |
|---|---|---|---|
| 2017-01-01 | √ | √ | |
| 2017-02-02 | √ | √ | |
| 2017-03-03 | √ | √ | √ |
-
在倒排索引中查找搜索串,获取document list
这时候一个filter查询:2017-02-02,在倒排索引里面找,对应的document list是doc2,doc3
-
为每个在倒排索引中搜索到的结果构建一个bitset
这点非常重要, 使用找到的document list构建一个bitset,一个二进制数组,数组每个元素都是0或1,用来标识一个doc对一个filter条件是否匹配,如果匹配就是1,不匹配就是0.
上面的例子中,构建的bitset就是[0,1,1]尽可能用简单的数据结构去实现复杂的功能,可以节省内存空间,提升性能
-
遍历每个过滤条件对应的bitset,优先从最稀疏的开始搜索,查找满足条件的所有document
在一个search请求中,可以发出多个filter条件(这个后面再具体说),每个filter会对应一个bitset
遍历每个filter条件对应的bitset,先从最稀疏的开始遍历.怎么算稀疏呢?
[0,0,0,1,0,0] – 比较稀疏
[0,1,0,1,0,1]
先遍历比较稀疏的bitset,可以过滤掉尽可能多的数据比如现在有个请求 filter: postDate=2017-01,userID=1,然后构建的两个bitset分别是:
[0,0,1,1,0,0]
[0,1,0,1,0,1]
遍历玩两个bitset之后,找到匹配所有条件的document,就是第4个,这个时候就可以将符合结果document返回给客户端了 -
caching bitset 跟踪query
对于在最近的256个query中超过一定次数的过滤条件,缓存其bitset.
对于小segment(<1000或<3%)不缓存举个例子, 在最近的256次查询中,postDate=2017-02-02这个条件出现超过了一定的次数(不固定), 就会自动缓存这个filter对应的bitset
filter对于小的segment中获取到的结果可以不缓存,segment中记录数小于1000的和segment大小小于index总大小的3%的
segment数据量很小的时候,扫描是很快的,而且我们之前有说过,segment会在后台自动合并的,小的segment很快会和其他小的segment合并,此时缓存也就没有什么意义了
-
大部分情况下 filter会在query之前执行
filter先执行可以先过滤掉一部分数据,之前说过query是会计算相关度分数,然后去排序的,而filter是不计算分数,也不排序,所以先执行filter过滤掉尽可能多的数据
-
如果document有新增或修改,那么cached bitset会被自动更新
举个例子,之前有个filter 过滤条件是postDate=2017-02-02,然后他的bitset是[0,0,0,1]
这个时候如果新增了一条document进来 postDate也是 2017-02-02,id是5, 那么这个bitset会自动更新为[0,0,0,1,1]
同理,如果id = 1的document的postDate更新为2017-02-02 那么bitset也会更新为[1,0,0,1,1] -
以后只要是有相同的filter条件的,会直接来使用这个过滤条件对应的cached bitset
以上是关于Elasticsearch的CRUD的主要内容,如果未能解决你的问题,请参考以下文章
golang elasticsearch 文档操作(CRUD) --- 2022-04-02