SQL的JOIN用法总结
Posted Billy编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL的JOIN用法总结相关的知识,希望对你有一定的参考价值。

为了便于理解,本文将关键字全大写,非关键字全小写。实际使用没有这个要求。
SQL的JOIN会用,用得好,能使SQL准确取到想取的数据,同时SQL语句还结构清晰易维护。它的通常形式为:
SELECT <结果字段集> FROM <左表> JOIN <右表> ON <连接条件> WHERE <筛选条件>
其中的JOIN可以换成以下的这些
JOIN, INNER JOIN, LEFT JOIN, RIGHT JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL JOIN, FULL OUTER JOIN, CROSS JOIN
但上面有些是等价的,一些是另一些的简写,整理如下:
| 全写 | 简写 |
| INNER JOIN | JOIN |
| LEFT OUTER JOIN | LEFT JOIN |
| RIGHT OUTER JOIN | RIGHT JOIN |
| FULL OUTER JOIN | FULL JOIN |
| CROSS JOIN | (无) |
除了CROSS JOIN无须有、也不能有ON之外,其它的JOIN都必须有ON。
关于这些JOIN的基本用法,网上已经不少文章介绍,可以先看看 这个,这个 或者百度一下。
下文假设你已经明白这些JOIN的基本用法。
哪个表算左,哪个表算右?
如果是两表,则XX JOIN左边的表算左,右边的表算右,与ON后面的条件的写法无关。比如ON后面是等于号,等于号两边互换,不影响左右表的认定,也不影响查询结果。
如果是多表,则XX JOIN左边的全部表算左,右边紧跟的那一个表算右,与ON后面的条件写法无关。
ON后面如果有多个条件,会如何影响查询的结果?
如果有多个条件,只看整个表达式的结果是True还是False,与部分表达式是否成立无关。比如 ON a.f1 = b.f1 AND a.f2 = b.f2,假如a.f1不等于b.f1,则不管a.f2是否等于b.f2,整个ON表达式都对查询的结果无影响。ON后面不管多复杂,只看表达式整体运算的结果。
容易犯的一个误区(重点来啦!)
以LEFT JOIN举例,一些人认为LEFT JOIN从左表出发得到的结果,(假设没有WHERE语句),左表的一行在结果中有且只有一行。
基于ON的关联条件,结果分成3种情况: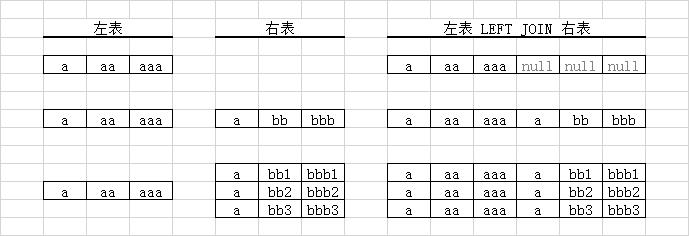
1. 左表的1行,对应右表0行,则结果是1行,其中右表字段都为NULL
2. 左表的1行,对应右表1行,则结果是1行。
3. 左表的1行,对应右表n行(n>1),则结果是n行,其中左表字段被复制到结果中的n行中。
结论:对于LEFT JOIN,左表的一行,在结果中也可能出现多行!
RIGHT JOIN同理:对于RIGHT JOIN,右表的一行,在结果中也可能出现多行!
其它的JOIN都会在对面(左的对面是右)的表有多条数据符合ON条件时在结果中出现多次。
没有ON的CROSS JOIN,天生就会出现多行,左右表在结果中都可能出现多行!
当需要用FULL JOIN,但当前的数据库又不支持怎么办?
比如mysql就不支持FULL JOIN。
这个网上有通用的解法,即是把FULL JOIN转化成(LEFT JOIN) UNION (RIGHT JOIN)的结构。
支持FULL JOIN的写法:
SELECT * FROM table_a AS a FULL JOIN table_b AS b ON a.a_id = b.a_id
不支持FULL JOIN的写法:
SELECT * FROM table_a AS a LEFT JOIN table_b AS b ON a.a_id = b.a_id UNION SELECT * FROM table_a AS a RIGHT JOIN table_b AS b ON a.a_id = b.a_id
但是实际SQL往往不会这么简单。当table_a或table_b是一个子查询(可能SQL很长)时,被写成两处,就会带来维护的不便和两处修改可能不一致的风险。
SELECT * FROM ( SELECT * FROM table_a -- 想象这是这是一个语句很长、很复杂的子查询 ) AS a LEFT JOIN ( SELECT * FROM table_b -- 想象这是这是另一个语句很长、很复杂的子查询 ) AS b ON a.a_id = b.a_id UNION SELECT * FROM ( SELECT * FROM table_a -- 想象这是这是一个语句很长、很复杂的子查询 ) AS a LEFT JOIN ( SELECT * FROM table_b -- 想象这是这是另一个语句很长、很复杂的子查询 ) AS b ON a.a_id = b.a_id
改成下面这样的写法就能避免这个问题:
WITH a AS ( SELECT * FROM table_a -- 想象这是这是一个语句很长、很复杂的子查询 ), b AS ( SELECT * FROM table_b -- 想象这是这是另一个语句很长、很复杂的子查询 ) SELECT * FROM a LEFT JOIN b ON a.a_id = b.a_id UNION SELECT * FROM a RIGHT JOIN b ON a.a_id = b.a_id
现在你是不是对JOIN的认知加深了一些?有不清楚欢迎留言。
以上是关于SQL的JOIN用法总结的主要内容,如果未能解决你的问题,请参考以下文章