MySQL索引详解
Posted 打瞌睡的布偶猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL索引详解相关的知识,希望对你有一定的参考价值。
mysql索引
什么是索引?
官方定义
一种帮助MySQL提高查询效率的数据结构。
索引的优点
大大加快数据的查询速度
索引的缺点
创建索引是为产生索引文件的,占用磁盘空间。索引文件是一个二叉树类型的文件,可想而知我们的DML操作,对表记录的增、删、改操作同样也会对索引文件进行修改,所以性能会相应的有所下降。
索引的分类(INNODB)
主键索引
将表属性设定为主键后,数据库会自动为主键创建聚簇索引。
单值索引
一个索引只包含单个列,一个表中可以有多个单值索引,这种索引又称单列索引或者普通索引。
唯一索引
索引列的值必须唯一,但允许有空值null(和主键不同,主键不允许为空),但只能有一个(因为唯一)。
复合索引
一个索引包含多个列。
ps:MySQL5.7之前,MyISAM引擎可以提供全文索引,即在定义索引的列上支持值得全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR、TEXT类型列上创建。全文索引只有MyISAM存储引擎支持。
索引的基本操作
创建一个用于测试索引的数据库test_index
主键索引——自动创建
-- 切换数据库
use test_index;
-- 创建表t_user
create table t_user(id varchar(20) primary key , name varchar(10));
-- 展示表索引
show index from t_user;
表索引展示
单值索引——手动创建
建表时创建
-- 创建表t_user时同时创建索引
create table t_user_common(id varchar(20) primary key, name varchar(10), key(name));
索引展示

建表后创建
create index name_index on t_user(name);
唯一索引——手动创建
建表时创建
-- 创建表t_user时使用unique创建唯一索引
create table t_user(id varchar(20) primary key , name varchar(10), unique(name));
建表后创建
create unique index name_index on t_user(name);
复合索引——手动创建
建表时创建
-- 创建表t_user时使用key()创建复合索引
create table t_user(id varchar(20) primary key , name varchar(10), age int(3), key(name, age));
建表后创建
create index name_age_index on t_user(name, age);
查询时原则上需要遵从最左匹配原则,才能利用复合索引,另外MySQL的引擎为了更好地利用复合索引,再查询过程中会动态调整查询字段的顺序以便利用索引。
name age √
age name √
age ×
name √
索引的底层原理
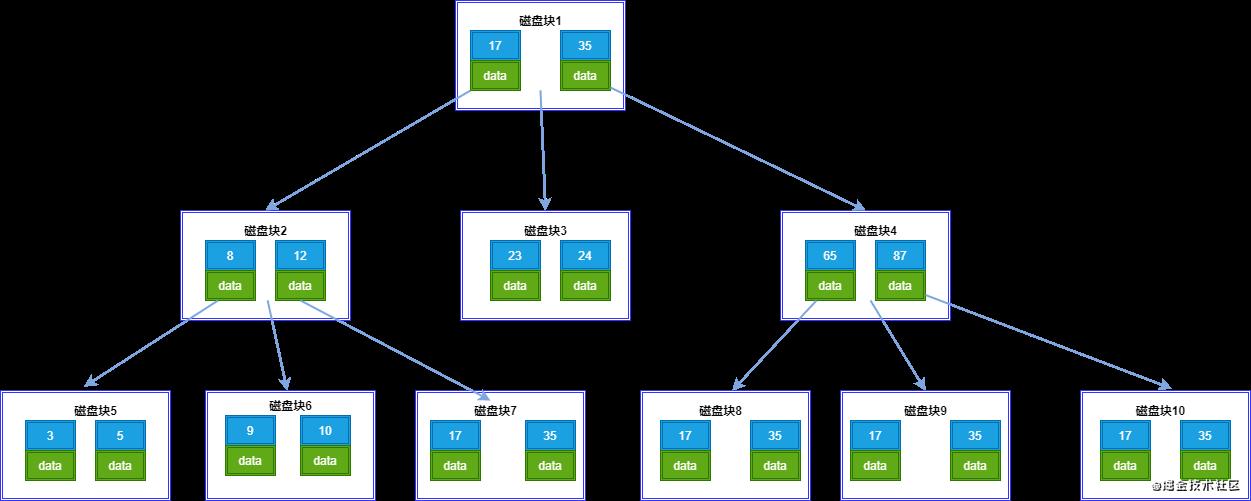
BTree
B树是一种多叉平衡查找树,其主要特点:
(1)B树的节点中存储着多个元素,每个内节点有多个分叉。
(2)节点中的元素包含键值和数据,节点中的键值从小到大排列。也就是说,在所有的节点都储存数据。
(3)父节点当中的元素不会出现在子节点中。
(4)所有的叶子结点都位于同一层,叶节点具有相同的深度,叶节点之间没有指针连接。
B+Tree
B+树是B树的升级版,它们最主要的区别在于非叶子节点是否存储数据的问题。
B+树在结构上和B树的区别在于:
只有叶子节点才会存储数据,非叶子节点只存储键值- 叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个
双向有序链表。
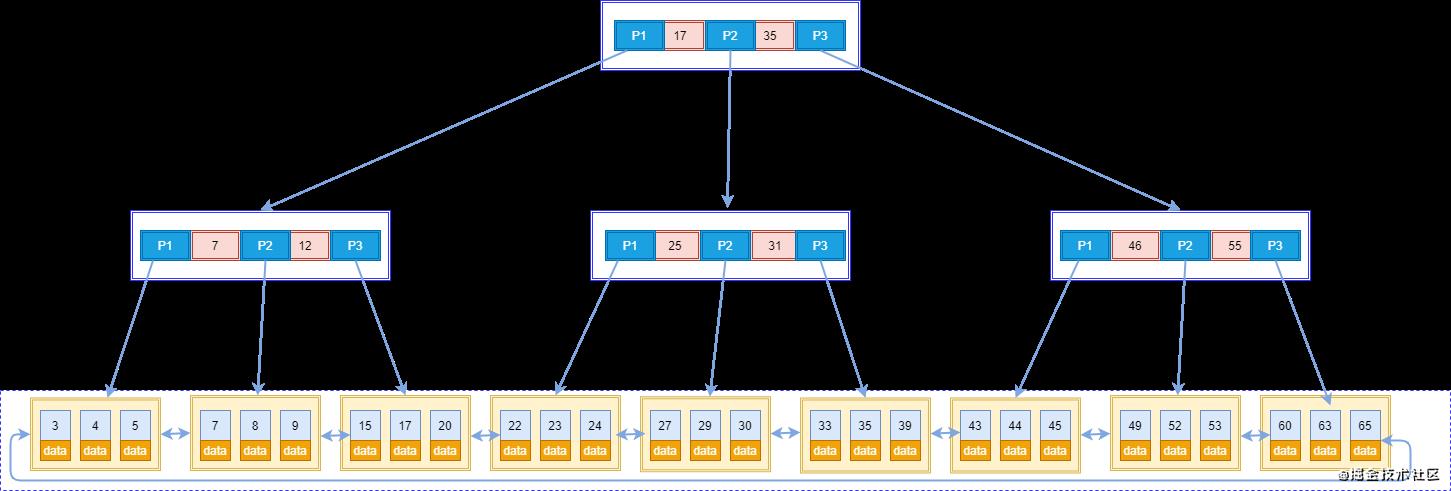
INNODB中的B+Tree的特点:
(1)它是BTree 的变种,BTree能解决的问题,它都能解决。
(2)扫库、扫表能力更强(进行全表扫描时,只需要遍历叶子节点就可以了)
(3)B+Tree的磁盘读写能力相对于BTree来说更强(根节点和分支节点不保存数据区, 所以一个节点可以保存更多的关键字,一次磁盘加载的关键字更多)
(4)排序能力更强(因为叶子节点上有下一个数据区的指针,数据形成了链表)
(5)效率更加稳定(B+Tree 永远是在叶子节点拿到数据,所以 IO 次数是稳定的)
建立索引过程
- 往数据表中插入数据时,数据库引擎会对插入的元素进行
排序,以链表的形式把节点(索引,数据,指针)串起来。 分页处理,INNODB引擎默认分页大小为16KB,在最底层的页中存放所有的数据,在其他层则存放的是分页索引和链接指针。- 索引有两种实现的数据结构,
B树和B+树- B+树的非叶节点只存储键值信息
- B+树所有叶子节点之间都有一个链接指针
- B+树把所有数据记录方法叶子节点中
- 数据库中,B+树的高度一般都在2~4层。由于MySQL的INNODB引擎在设计时是将B+树的
根节点常驻内存的,因此在查找某一键值的行记录时,最多只需要1~3次磁盘IO。
聚簇索引和非聚簇索引
MySQL中最常见的两种存储引擎分别是MyISAM和INNODB,分别实现了非聚簇索引和聚簇索引。
在索引的分类中,我们可以按照索引的键是否为主键来分为“主键索引”和“辅助索引”,使用主键键值建立的索引称为“主键索引”,其它的称为“辅助索引”。因此主键索引只能有一个,辅助索引可以有很多个。
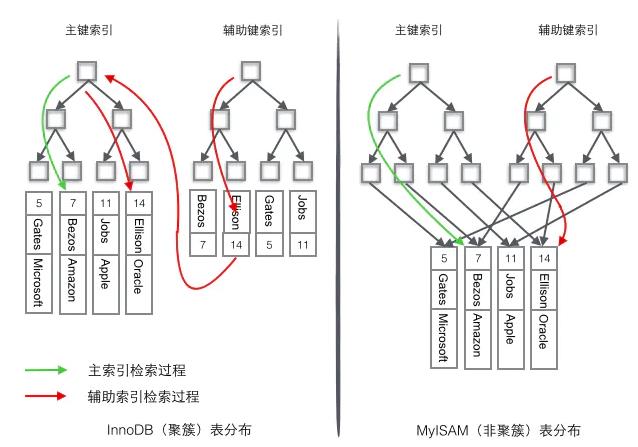
INNODB —— 聚簇索引
聚簇索引——索引和数据放在一起,找到了索引就找到了数据。
聚簇索引的使用过程
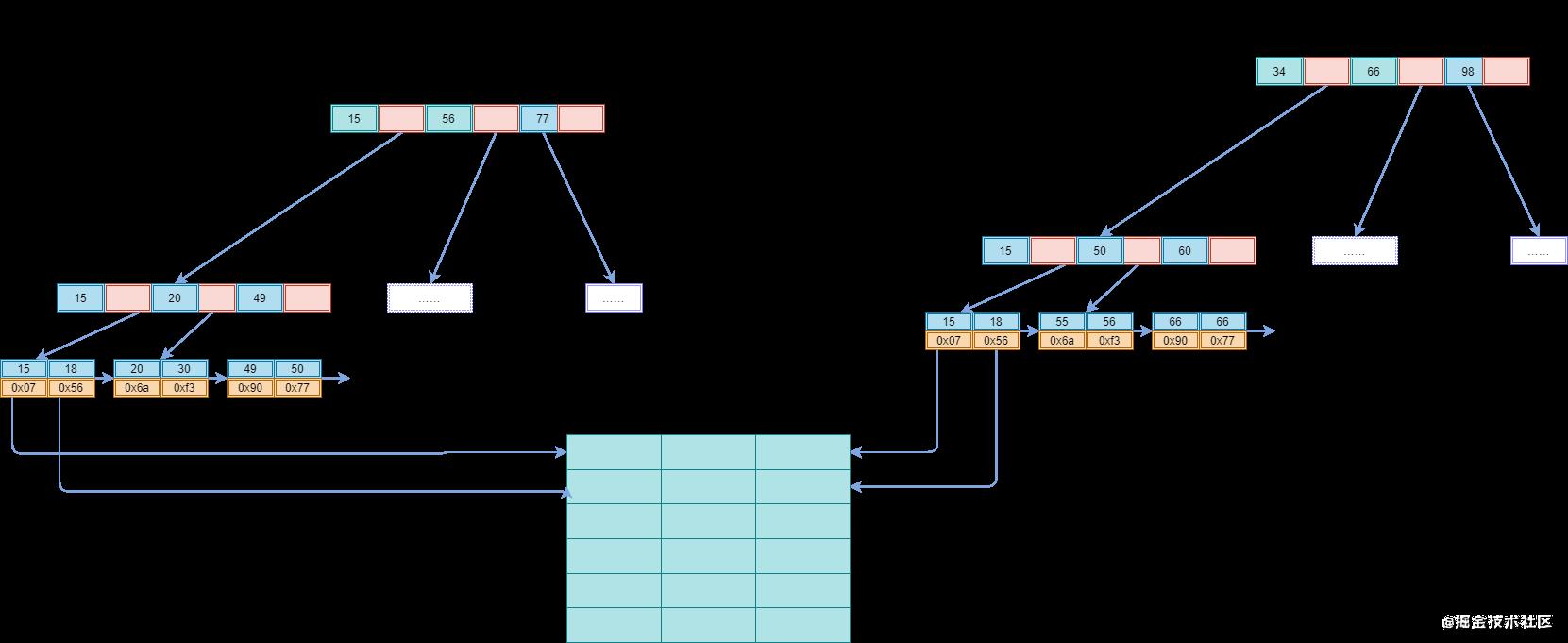
INNODB使用的是聚簇索引,将主键组织到一棵B+树中 ,而行数据就存储在叶子节点上,通过"where id = 14"这样的条件查找主键时,则按照B+树的检索算法即可找到对应的叶子节点,并获取其行数据。
特别地,若对其中的任意一列例如Name列进行条件搜索,则需要进行两个步骤:
- 第一步,在辅助索引B+树中检索Name,到达叶子节点后获取其主键
- 第二步,根据第一步获取到的主键在主索引B+树中再执行一次B+树检索操作,最终到达对应的叶子节点即可获取整行数据
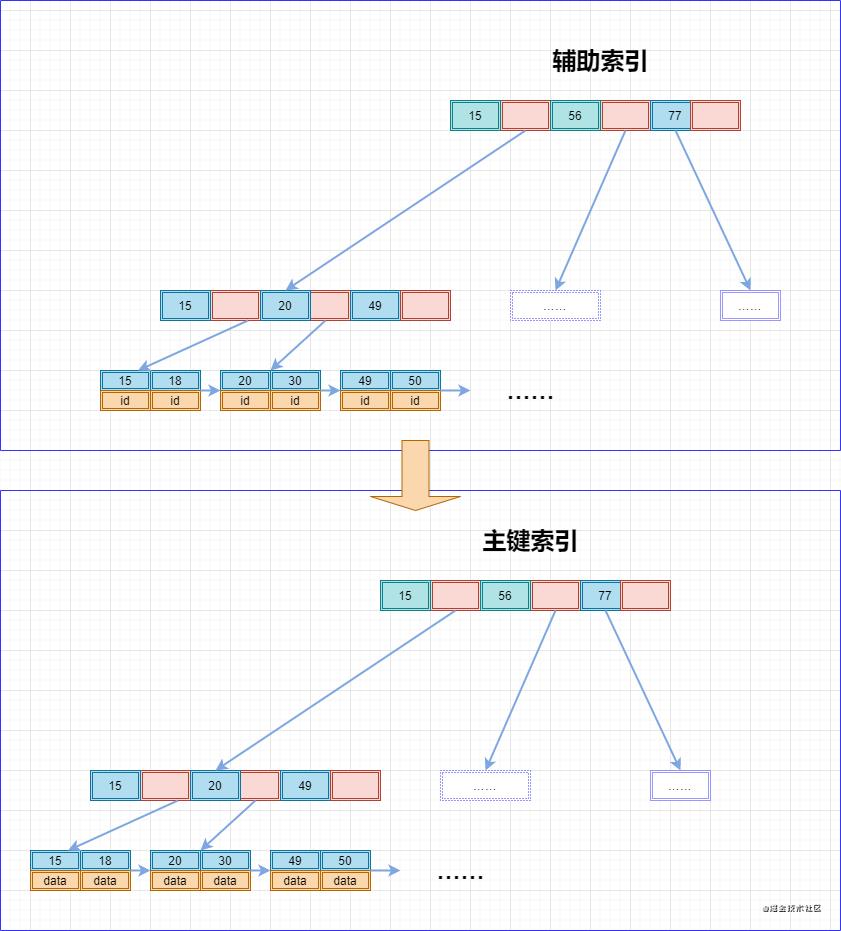
聚簇索引默认为主键,特别地,若表中没有定义主键,则INNODB会选择一个唯一且非空的索引代替,若没有这样的索引,则会隐式地定义一个主键(类似oracle中的RowId)来作为聚簇索引。
聚簇索引的优势
- 由于行数据和叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问的时候,会在内存中完成访问,不必访问磁盘。这样
主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。 - 辅助索引使用主键作为"指针"而不是使用地址值作为指针,这样做的好处是,
减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。 - 聚簇索引
适合用在排序的场合,非聚簇索引不适合 - 取出一定
范围数据的时候,使用聚簇索引 - 二级索引需要两次索引查找,而不是一次才能取到数据,因为存储引擎第一次需要通过二级索引找到索引的叶子节点,从而找到数据的主键,然后在聚簇索引中用主键再次查找索引,再找到数据
- 可以把
相关数据保存在一起。例如实现电子邮箱时,可以根据用户 ID 来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘 I/O。
聚簇索引的劣势
维护索引代价高,特别是插入新行或者主键被更新导至要分页的时候- 表因为使用UUId(随机ID)作为主键,使
数据存储稀疏,这就会出现聚簇索引有可能有比全表扫描更慢 - 如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值;
过长的主键值,会导致非叶子节点占用占用更多的物理空间
MyISAM——非聚簇索引
非聚簇索引的数据表和索引表是分开存储的。
非聚簇索引中的数据是根据数据的插入顺序保存。因此非聚簇索引更适合单个数据的查询。插入顺序不受键值影响。
参考资料及部分图源
以上是关于MySQL索引详解的主要内容,如果未能解决你的问题,请参考以下文章