02 Spark架构与运行流程
Posted DZZZZZ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了02 Spark架构与运行流程相关的知识,希望对你有一定的参考价值。
一、简述Spark生态系统。
答:Spark 生态系统以Spark Core 为核心,能够读取传统文件(如文本文件)、HDFS、Amazon S3、Alluxio 和NoSQL 等数据源,利用Standalone、YARN 和Mesos 等资源调度管理,完成应用程序分析与处理。这些应用程序来自Spark 的不同组件,如Spark Shell 或Spark Submit 交互式批处理方式、Spark Streaming 的实时流处理应用、Spark SQL 的即席查询、采样近似查询引擎BlinkDB 的权衡查询、MLbase/MLlib 的机器学习、GraphX 的图处理和SparkR 的数学计算等,如下图所示,正是这个生态系统实现了“One Stack to Rule Them All”目标。
1、Spark Core 是整个BDAS 生态系统的核心组件,是一个分布式大数据处理框架。Spark Core提供了多种资源调度管理,通过内存计算、有向无环图(DAG)等机制保证分布式计算的快速,并引入了RDD 的抽象保证数据的高容错性
2、Spark Streaming 是一个对实时数据流进行高吞吐、高容错的流式处理系统,可以对多种数据源(如Kafka、Flume、Twitter 和ZeroMQ 等)进行类似Map、Reduce 和Join 等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘
3、Spark SQL 的前身是Shark,它发布时Hive 可以说是SQL on Hadoop 的唯一选择(Hive 负责将SQL 编译成可扩展的MapReduce 作业),鉴于Hive 的性能以及与Spark 的兼容
4、BlinkDB 是一个用于在海量数据上运行交互式SQL 查询的大规模并行查询引擎,它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内
5、MLBase 是Spark 生态系统中专注于机器学习的组件,它的目标是让机器学习的门槛更低,让一些可能并不了解机器学习的用户能够方便地使用MLBase
6、GraphX 最初是伯克利AMP 实验室的一个分布式图计算框架项目,后来整合到Spark 中成为一个核心组件。它是Spark 中用于图和图并行计算的API,可以认为是GraphLab 和Pregel 在Spark 上的重写及优化。跟其他分布式图计算框架相比,GraphX 最大的优势是:在Spark 基础上提供了一栈式数据解决方案,可以高效地完成图计算的完整的流水作业
7、R 是遵循GNU 协议的一款开源、免费的软件,广泛应用于统计计算和统计制图,但是它只能单机运行。为了能够使用R 语言分析大规模分布式的数据,伯克利分校AMP 实验室开发了SparkR,并在Spark 1.4 版本中加入了该组件。通过SparkR 可以分析大规模的数据集,并通过R Shell 交互式地在SparkR 上运行作业
8、
Alluxio 是一个分布式内存文件系统,它是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark 和 MapReduce 那样。Alluxio 是架构在最底层的分布式文件存储和上层的各种计算框架之间的一种中间件。其主要职责是将那些不需要落地到DFS 里的文件,落地到分布式内存文件系统中,来达到共享内存,从而提高效率。同时可以减少内存冗余、GC 时间等
二、 用图文描述Spark运行架构,运行流程
1、Spark运行架构
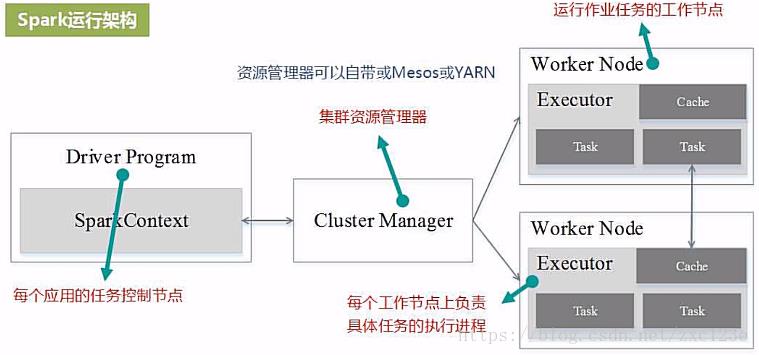
Application:用户编写的Spark应用程序。
Driver:Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭。
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task。
RDD:弹性分布式数据集,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
DAG:有向无环图,反映RDD之间的依赖关系。
Task:运行在Executor上的工作单元。
Job:一个Job包含多个RDD及作用于相应RDD上的各种操作。
Stage:是Job的基本调度单位,一个Job会分为多组Task,每组Task被称为Stage,或者也被称为TaskSet,代表一组关联的,相互之间没有Shuffle依赖关系的任务组成的任务集。
Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
1) Standalon : spark原生的资源管理,由Master负责资源的分配
2) Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
3) Hadoop Yarn: 主要是指Yarn中的ResourceManager
2、Spark运行基本流程

1、为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控
2、资源管理器为Executor分配资源,并启动Executor进程
3、SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理。
4、Executor向SparkContext申请Task,TaskScheduler将Task发放给Executor运行并提供应用程序代码。
5、Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
Spark运行架构特点:
每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task。
Spark运行过程与资源管理器无关,只要能够获取Executor进程并保存通信即可。
Task采用数据本地性和推测执行等优化机制。
以上是关于02 Spark架构与运行流程的主要内容,如果未能解决你的问题,请参考以下文章