爬虫案例-如何爬取梨视频?
Posted eliwang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫案例-如何爬取梨视频?相关的知识,希望对你有一定的参考价值。
一、目标
爬取梨视频-娱乐-版块下标签为‘最热’的视频,存储到本地\'梨视频\'目录下,视频名:视频标题.mp4
首页url:https://www.pearvideo.com/category_4
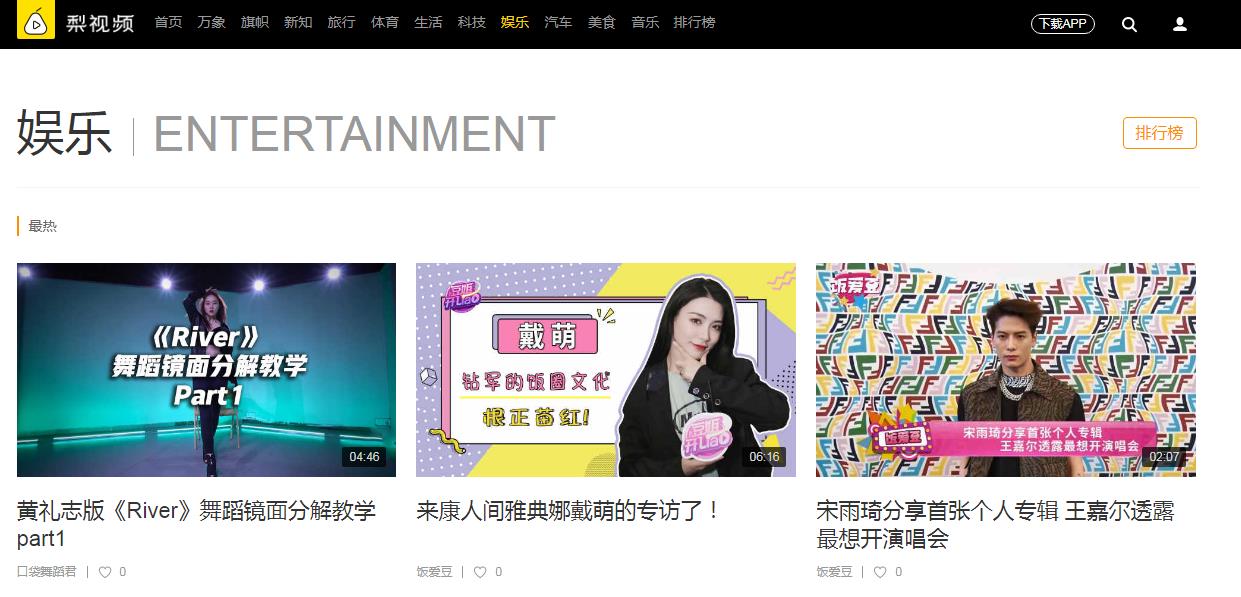
二、分析
- 首页可以提取到视频标题以及详情页url(部分),比如:\'video_1731216\',下面以该视频为例
- 进入详情页,可以从页面中查看到视频地址藏在video标签中,地址:’https://video.pearvideo.com/mp4/third/20210603/cont-1731216-10887340-153958-hd.mp4‘
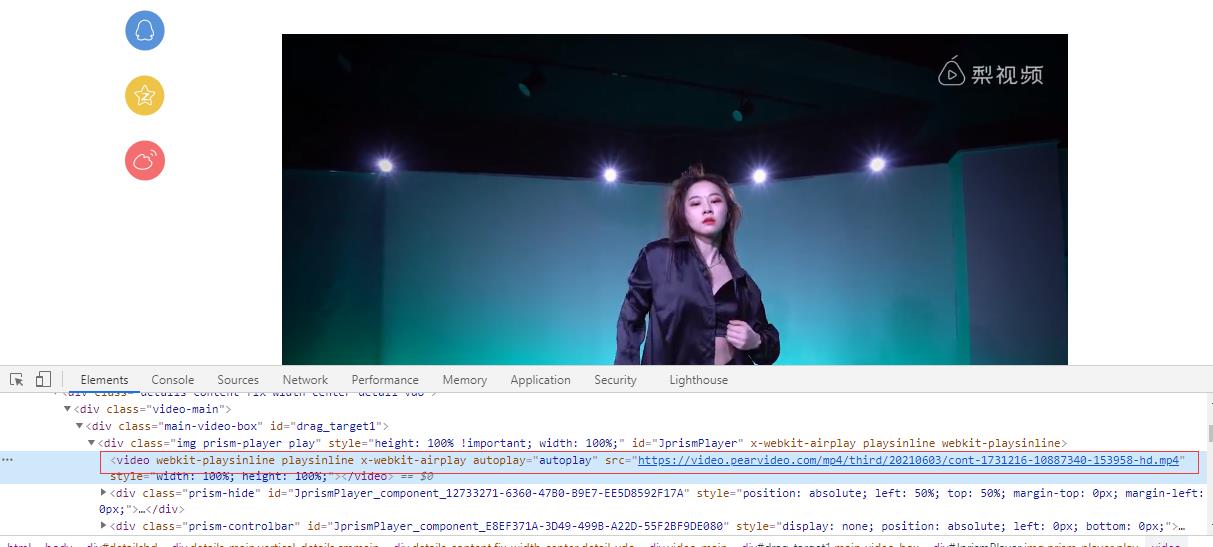
- 但是通过抓包工具局部搜索无法找到该标签,所以判断是通过ajax动态加载获取到的
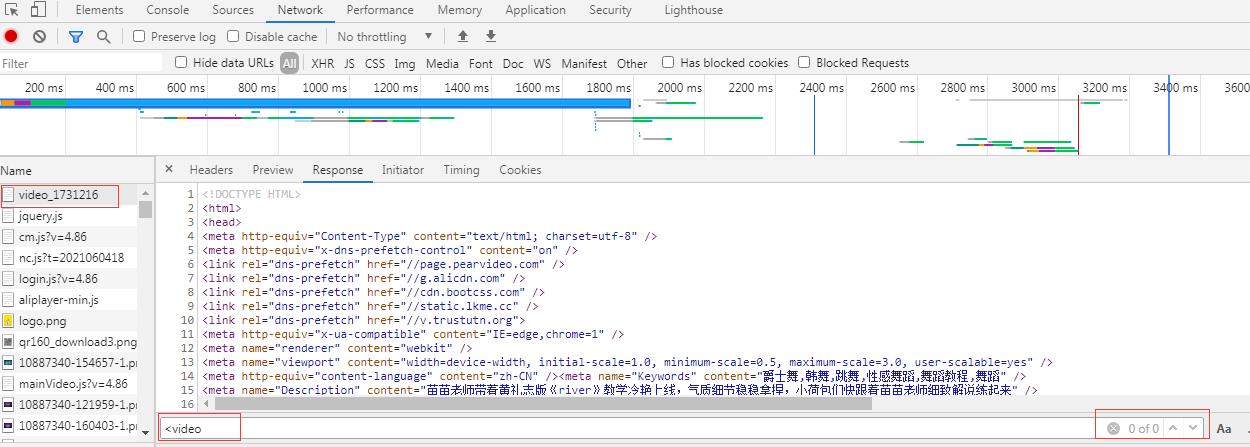
- 捕获到ajax请求
- url:’https://www.pearvideo.com/videoStatus.jsp?contId=1731216&mrd=0.03291621253058907‘
- method:GET


- 我们来回顾下整个流程:
- 主页获取到详情页url:\'video_1731216\'
- ajax请求:’https://www.pearvideo.com/videoStatus.jsp?contId=1731216&mrd=0.03291621253058907‘---mrd参数是0-1之间的一个随机数(random.random()),需要注意的是,发送ajax请求时,需要验证请求头中的Refere参数,对应的是详情页url,否则无法获取数据
- ajax请求返回的url:’https://video.pearvideo.com/mp4/third/20210603/1622802774696-10887340-153958-hd.mp4‘
- 视频真实url:’https://video.pearvideo.com/mp4/third/20210603/cont-1731216-10887340-153958-hd.mp4‘
- 总结:
- 通过主页获取详情页视频id,然后我们可以构造ajax请求:’https://www.pearvideo.com/videoStatus.jsp?contId=id&mrd=0-1之间的随机数‘
- 发送ajax请求时注意需要携带上Referer参数,并将返回的url中时间戳替换成’cont-id‘
三、代码实现
# coding:utf-8
import requests
import random
import os
import re
from multiprocessing.dummy import Pool
from fake_useragent import UserAgent
from lxml import etree
class LiVideoSpider:
\'\'\'梨视频爬虫类\'\'\'
def __init__(self):
self.st_url = \'https://www.pearvideo.com/category_4\' #首页url
self.p = Pool(4) #创建4个线程的线程池
self.headers = {
\'ua\':UserAgent().random
}
self.items = [] #存储视频相关信息,[{\'id\':\'xxx\',\'video_url\':\'xxx\'...},...]
self.video_path = \'./梨视频\' #视频存储路径
def start(self):
\'\'\'爬虫入口\'\'\'
#创建存储文件夹
if not os.path.exists(self.video_path):
os.mkdir(self.video_path)
#获取主页数据
response = requests.get(url=self.st_url,headers=self.headers)
tree = etree.html(response.text)
li_list = tree.xpath(\'//*[@id="listvideoList"]/ul/li\')
#解析主页数据,提取id,详情页url,视频标题
for li in li_list:
title = li.xpath(\'.//div[@class="vervideo-title"]/text()\')[0]
detail_url = li.xpath(\'./div/a/@href\')[0]
id = detail_url.split(\'_\')[-1]
item = {
\'id\':id,
\'title\':title+\'.mp4\',
\'detail_url\':detail_url
}
self.items.append(item)
#构造每个视频ajax请求的url
for i in range(len(self.items)):
js_url = \'https://www.pearvideo.com/videoStatus.jsp?contId={}&mrd={}\'.format(self.items[i][\'id\'],random.random())
self.items[i][\'js_url\'] = js_url
#通过线程池异步获取每个视频的下载地址url
items = self.p.map(self.get,self.items)
#异步下载每个视频
self.p.map(self.download,items)
def get(self,item):
\'\'\'获取视频下载地址\'\'\'
#headers中添上Referer参数
headers = {
\'ua\':UserAgent().random,
\'Referer\':item[\'detail_url\']
}
json_data = requests.get(url=item[\'js_url\'],headers=headers).json()
video_url = json_data["videoInfo"]["videos"]["srcUrl"]
#修正视频下载地址url
item[\'video_url\'] = re.sub(r\'16\\d+-\',r\'cont-{}-\'.format(item[\'id\']),video_url)
return item
def download(self,item):
\'\'\'下载视频\'\'\'
video_data = requests.get(url=item[\'video_url\'],headers=self.headers).content
with open(self.video_path+\'/\'+item[\'title\'],\'wb\') as f:
f.write(video_data)
if __name__ == \'__main__\':
LiVideoSpider().start()
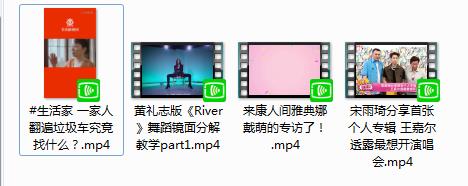
四、爬取结果

以上是关于爬虫案例-如何爬取梨视频?的主要内容,如果未能解决你的问题,请参考以下文章