APScheuler学习笔记
Posted Jruing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了APScheuler学习笔记相关的知识,希望对你有一定的参考价值。
APScheuler学习笔记
简介
安装
pip install apscheduler
APScheduler 组成部分
触发器:包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行
执行器:处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进程池来进行。当作业完成时,执行器将会通知调度器,常用的两种执行器:ProcessPoolExecutor(进程池)及 ThreadPoolExecutor(线程池,max:10)
调度器:通常在应用中只有一个调度器,应用的开发者通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业
作业存储:存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。作业默认存储在内存中,可以手动修改为db持久化存储(比如mongodb,redis等)
APScheduler 实战
初始化
# 常用的两种调度器
# from apscheduler.schedulers.background import BlockingScheduler # 当调度器是唯一要运行的程序是采用
from apscheduler.schedulers.background import BackgroundScheduler# 当需要调度器需要后台执行时采用(比如flask启动后,调度器依旧执行)
from apscheduler.jobstores.mongodb import MongoDBJobStore
from pymongo import MongoClient
mongo_client = MongoClient(host=\'127.0.0.1\', port=27017)
# 全局配置
# 作业存储方式
jobstores = {
\'mongo\': MongoDBJobStore(collection=\'job\', database=\'test\', client=mongo_client),
\'default\': MemoryJobStore()
}
# 执行
executors = {
\'default\': ThreadPoolExecutor(10),
\'processpool\': ProcessPoolExecutor(4)
}
job_defaults = {
\'coalesce\': False,
\'max_instances\': 10
}
# sched = BlockingScheduler()
sched = BackgroundScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults)
任务新增
任务控制
任务的控制分为3种:
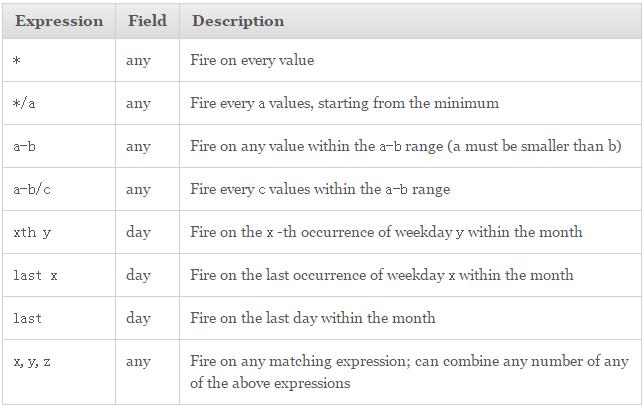
cron,interval,datecron:crontab语法
(int|str) 表示参数既可以是int类型,也可以是str类型 (datetime | str) 表示参数既可以是datetime类型,也可以是str类型 year (int|str) – 4-digit year -(表示四位数的年份,如2008年) month (int|str) – month (1-12) -(表示取值范围为1-12月) day (int|str) – day of the (1-31) -(表示取值范围为1-31日) week (int|str) – ISO week (1-53) -(格里历2006年12月31日可以写成2006年-W52-7(扩展形式)或2006W527(紧凑形式)) day_of_week (int|str) – number or name of weekday (0-6 or mon,tue,wed,thu,fri,sat,sun) - (表示一周中的第几天,既可以用0-6表示也可以用其英语缩写表示) hour (int|str) – hour (0-23) - (表示取值范围为0-23时) minute (int|str) – minute (0-59) - (表示取值范围为0-59分) second (int|str) – second (0-59) - (表示取值范围为0-59秒) start_date (datetime|str) – earliest possible date/time to trigger on (inclusive) - (表示开始时间) end_date (datetime|str) – latest possible date/time to trigger on (inclusive) - (表示结束时间) timezone (datetime.tzinfo|str) – time zone to use for the date/time calculations (defaults to scheduler timezone) -(表示时区取值)参数取值
interval:多久执行一次(比如10秒执行一次)
weeks [int] 等待的周数 days [int] 等待的天数 hours [int] 等待的小时数 minutes [int] 等待的分钟数 seconds [int] 等待的秒数 start_date 间隔计算的开始时间 end_date 下一次的执行时间 timezone 时区date: 具体什么时间执行(比如2021年5月50日 13点14分00秒执行)
run_date:任务开始时间 timezone:时区
# 第一种(本人建议使用第一种)
def say(name):
print(f"hello {name}")
# 采用任务控制中interval的方式创建
sched.add_job(func=say,args=("jruing",),id="task_01",trigger=\'interval\',seconds=3)
# 采用任务控制中cron的方式创建
sched.add_job(func=say, args=("jruing",),id="task_01",trigger=\'cron\',minute=minute, hour=hour,day=day, month=month, week=week)
# 采用任务控制中date的方式创建
sched.add_job(func=say, args=("jruing",), id="task_01",trigger=\'date\', run_date=datetime(2021, 5, 20, 13, 14, 0))
# 第二种(只适合运行期间不会改变的)
@sched.scheduled_job(\'interval\',args=("jruing",),id=\'task_01\', seconds=3)
def say(name):
print(f"hello {name}")
任务删除
# 从任务队列移除所有任务
sched.remove_all_jobs()
# 从任务队列移除单个任务(需要任务id)
sched.remove_job(\'task_01\')
任务修改
# 修改任务的执行频率(需要指定id)
sched.reschedule_job(job_id=\'task_01\',trigger=\'interval\',seconds=5)
任务查询
# 查询所有任务
sched.get_jobs()或者sched.print_jobs()
# 结果(返回所的任务对象)
[<Job (id=task_01 name=say)>]
# 查询单个任务(需要任务id)
sched.get_job(job_id=\'task_01\')
# 结果(返回这个任务的执行频率及当前状态)
say (trigger: interval[0:00:03], pending)
任务暂停
# 暂停单个任务(需要任务id)
sched.pause_job(job_id=\'task_01\')
任务恢复
# 恢复单个任务(需要任务id)
sched.resume_job(job_id=\'task_01\')
任务监听
任务一般会有如下状态
EVENT_SCHEDULER_STARTED = EVENT_SCHEDULER_START = 2 ** 0
EVENT_SCHEDULER_SHUTDOWN = 2 ** 1
EVENT_SCHEDULER_PAUSED = 2 ** 2
EVENT_SCHEDULER_RESUMED = 2 ** 3
EVENT_EXECUTOR_ADDED = 2 ** 4
EVENT_EXECUTOR_REMOVED = 2 ** 5
EVENT_JOBSTORE_ADDED = 2 ** 6
EVENT_JOBSTORE_REMOVED = 2 ** 7
EVENT_ALL_JOBS_REMOVED = 2 ** 8
EVENT_JOB_ADDED = 2 ** 9
EVENT_JOB_REMOVED = 2 ** 10
EVENT_JOB_MODIFIED = 2 ** 11
EVENT_JOB_EXECUTED = 2 ** 12
EVENT_JOB_ERROR = 2 ** 13
EVENT_JOB_MISSED = 2 ** 14
EVENT_JOB_SUBMITTED = 2 ** 15
EVENT_JOB_MAX_INSTANCES = 2 ** 16
# 代码
from apscheduler.events import EVENT_JOB_ERROR, EVENT_JOB_MISSED, EVENT_JOB_EXECUTED #可以根据情况自选
def listener(Event):
# Event的方法只有job_id,code,jobstore三种,code对应的就是上面状态的数字,apscheduler用数字代替状态显示
print(Event.job_id)
print(Event.code)
print(Event.jobstore)
# 创建一个任务监听器(本人一般放在任务添加之前)
sched.add_listener(callback=listener,EVENT_JOB_EXECUTED|EVENT_JOB_ADDED)
# 删除一个任务监听器
sched.remove_listener(callback=listener)
关闭apscheduler
# 默认是调度器会等待所有的任务执行完成后,关闭所有的调度器和作业存储
sched.shutdown(wait=True) # 若wait为False,则立刻关闭
以上是关于APScheuler学习笔记的主要内容,如果未能解决你的问题,请参考以下文章