解决jmeter做接口测试时响应数据中文显示乱码或者Unicode码的问题
Posted 风风风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解决jmeter做接口测试时响应数据中文显示乱码或者Unicode码的问题相关的知识,希望对你有一定的参考价值。
最近做jmeter接口测试ide时候,出现一个问题;请求成功之后返回的响应数据中文显示为Unicode码。如下图:

最开始一位示乱码;修改jmeter的配置文件
打开jmeter下的目录:jmeter-5.3\\bin 目录下的jmeter.properties

sampleresult.default.encoding=utf-8
但是修改配置文件后发现接口响应数据还是乱码;后来对比postman,postman返回也是这种,知识postman有一个json格式转化的小工具,可以转化下面这种

jmeter也有查看json格式的响应数据;但是写响应断言的时候默认是text格式

解决办法:在对应请求后面添加后置处理器:BeanShell PostProcessor和转码代码,在Script中附上转码代码;添加后如图:
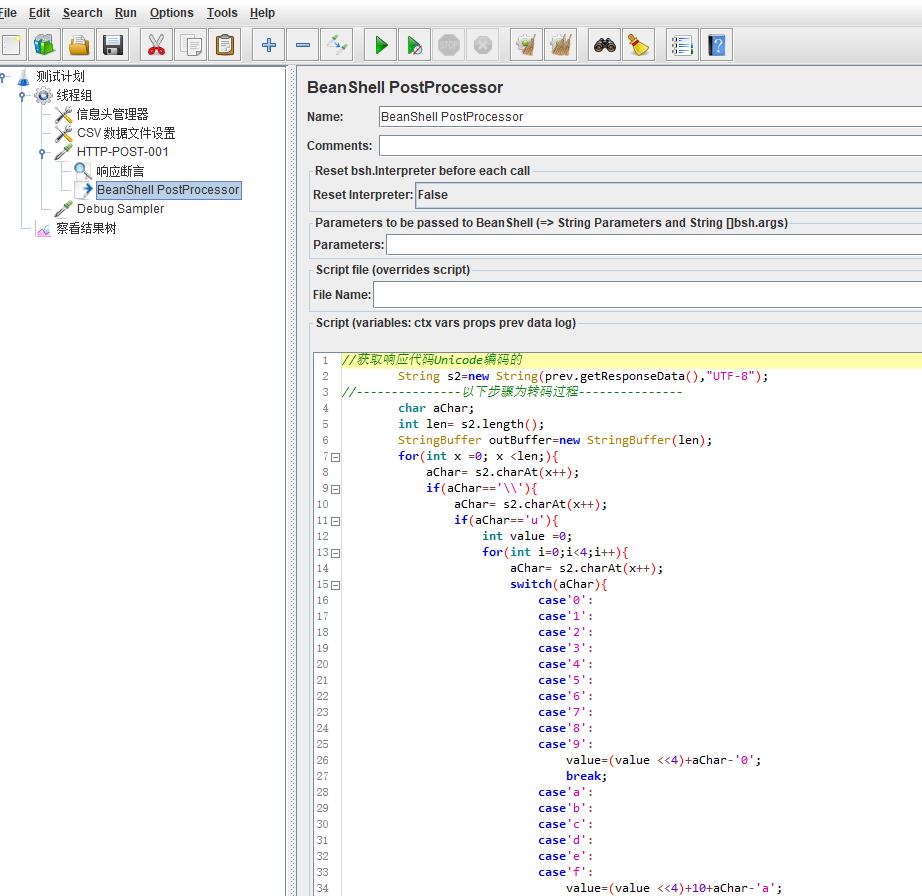
转码代码如下:
//获取响应代码Unicode编码的 String s2=new String(prev.getResponseData(),"UTF-8"); //---------------以下步骤为转码过程--------------- char aChar; int len= s2.length(); StringBuffer outBuffer=new StringBuffer(len); for(int x =0; x <len;){ aChar= s2.charAt(x++); if(aChar==\'\\\\\'){ aChar= s2.charAt(x++); if(aChar==\'u\'){ int value =0; for(int i=0;i<4;i++){ aChar= s2.charAt(x++); switch(aChar){ case\'0\': case\'1\': case\'2\': case\'3\': case\'4\': case\'5\': case\'6\': case\'7\': case\'8\': case\'9\': value=(value <<4)+aChar-\'0\'; break; case\'a\': case\'b\': case\'c\': case\'d\': case\'e\': case\'f\': value=(value <<4)+10+aChar-\'a\'; break; case\'A\': case\'B\': case\'C\': case\'D\': case\'E\': case\'F\': value=(value <<4)+10+aChar-\'A\'; break; default: throw new IllegalArgumentException( "Malformed \\\\uxxxx encoding.");}} outBuffer.append((char) value);}else{ if(aChar==\'t\') aChar=\'\\t\'; else if(aChar==\'r\') aChar=\'\\r\'; else if(aChar==\'n\') aChar=\'\\n\'; else if(aChar==\'f\') aChar=\'\\f\'; outBuffer.append(aChar);}}else outBuffer.append(aChar);} //-----------------以上内容为转码过程--------------------------- //将转成中文的响应结果在查看结果树中显示 prev.setResponseData(outBuffer.toString());
PS:
1、原理:通过BeanShell内置变量prev,获取响应数据,经过Java程序编码,把unicode转换成中文;最后查看结果数里面响应数据为转换之后的中文
2、在性能测试前,请把这个后置处理器删除,不然后消耗本机内存和CPU,会影响性能测试结果
以上是关于解决jmeter做接口测试时响应数据中文显示乱码或者Unicode码的问题的主要内容,如果未能解决你的问题,请参考以下文章