PostgreSQL故障恢复能力之检查点(Checkpoint)
Posted 明矾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PostgreSQL故障恢复能力之检查点(Checkpoint)相关的知识,希望对你有一定的参考价值。
复习下前面的知识点:
1、缓冲区高速缓存(Buffer Cache)位于服务器的共享内存中,并且所有进程均可访问。在读取或更新数据时,进程将页面读入缓存。当页面位于缓存中时,我们在RAM中使用它并保存数据到磁盘。
2、当遇到掉电等故障场景,所有 RAM 内容丢失时,要在故障后恢复数据,pg必须维护一份预写式日志(WAL),在故障恢复过程中通过重放WAL日志进行数据恢复。
checkpoint
本文需要讨论的是,我们不知道在恢复期间从哪里开始重放 WAL 记录。
方案一:
从头开始恢复,带来是问题是我们不一定保留了所有历史的WAL日志记录(保留所有历史WAL会占用大量磁盘空间),即使我们通过归档保留了所有的WAL记录,恢复的时长也会难以接受。
方案二:
我们需要一个逐渐向前推进的时间点,我们可以从该时间点开始恢复(并可以安全地删除时间点以前的WAL 记录),为此,pg引入了检查点(checkpoint)。
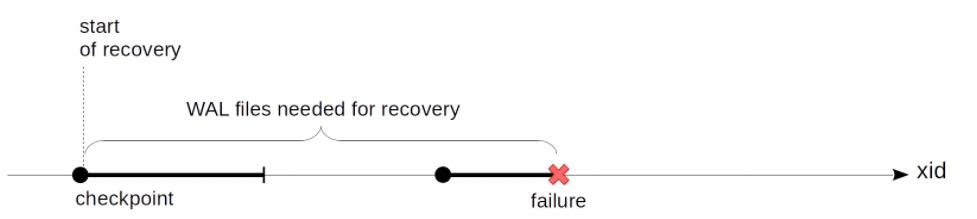
当执行checkpoint后,会确保检查点开始时所有脏的缓冲区都刷到磁盘上,此时checkpoint执行完成。后续我们可以使用checkpoint记录的开始时间作为开始恢复的点。
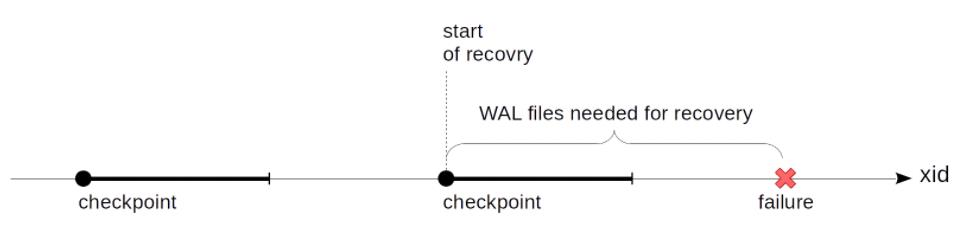
checkpoint会执行多久
checkpoint执行后会带来大量的页面写入操作,为了避免大量的页面写入对I/O造成冲击,在检查点期间写入脏缓冲区的过程会分散为一段时间。该周期由checkpoint_completion_target控制,它是检查点间隔的一部分,默认为0.5,也就是说每个checkpoint需要在checkpoints间隔时间的50%内完成。
通常checkpoint_completion_target值会增加到 0.9 以获得更好的均匀性,PostgreSQL 14版本中会将默认值修改为0.9。
checkpoint执行过程
1、首先会对缓冲区中的脏页进行标记
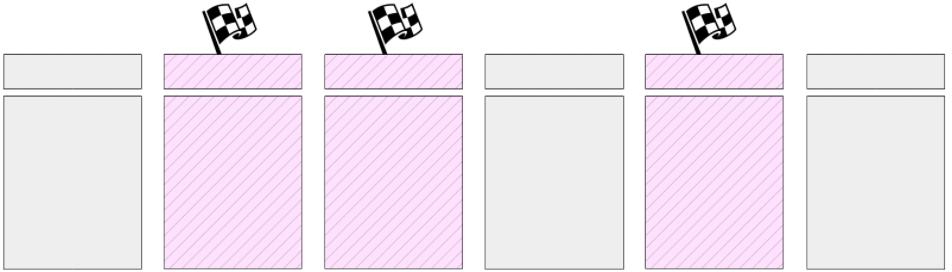
2、然后检查指针遍历所有缓存并将标记的脏页刷新到磁盘(页面不会从缓存中逐出,而只会写入磁盘)。
3、新的脏缓冲区不会被标记,并且检查指针不会写入它们。
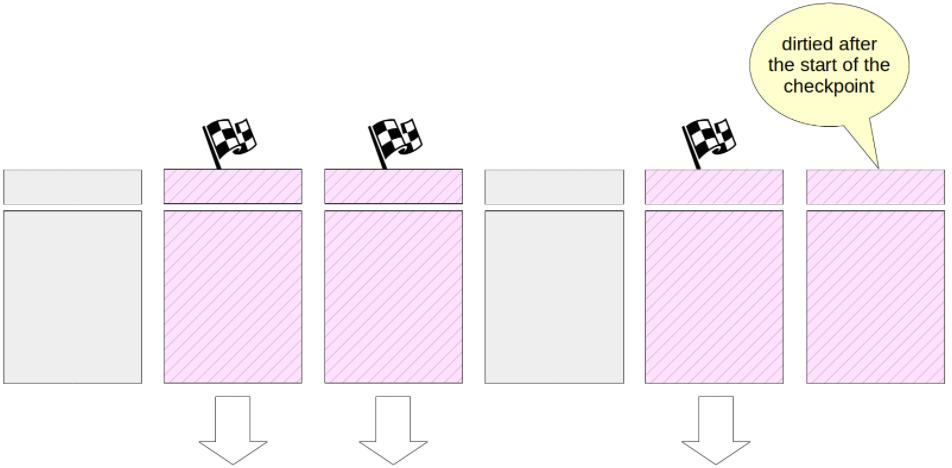
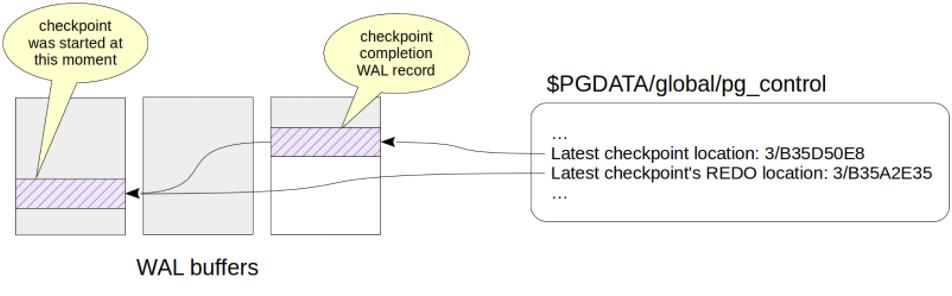
4、创建检查点结束的 WAL 记录,该记录包含检查点开始时间的 LSN。
5、更新控制文件信息($PGDATA/global/pg_control)。
演示
1、创建一个表;它的页面将进入缓冲区缓存并变脏:
CREATE EXTENSION pg_buffercache; CREATE TABLE chkpt AS SELECT * FROM generate_series(1,10000) AS g(n); SELECT count(*) FROM pg_buffercache WHERE isdirty;
postgres=# SELECT count(*) FROM pg_buffercache WHERE isdirty; count ------- 62 (1 row)
2、记住当前的 WAL 位置
SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 3/8A0B3810 (1 row)
3、手动执行检查点操作
CHECKPOINT; SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 0 (1 row)
4、看看检查点是如何反映在 WAL 中的
SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 3/8A0B38F8 (1 row)
可以看到lsn有更新,接下来用pg_waldump查看wal日志记录了哪些内容
查看当前lsn对应的wal日志文件
SELECT file_name, upper(to_hex(file_offset)) file_offset FROM pg_walfile_name_offset(\'3/8A0B38F8\');
file_name | file_offset --------------------------+------------- 00000001000000030000008A | B38F8 (1 row)
/usr/local/pgsql/bin/pg_waldump -p /usr/local/pgsql/data/pg_wal/ -s 3/8A0B3810 -e 3/8A0B38F8 00000001000000030000008A
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 3/8A0B3810, prev 3/8A0B37D8, desc: RUNNING_XACTS nextXid 58215 latestCompletedXid 58214 oldestRunningXid 58215 rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 3/8A0B3848, prev 3/8A0B3810, desc: CHECKPOINT_ONLINE redo 3/8A0B3810; tli 1; prev tli 1; fpw true; xid 0:58215; oid 34053; multi 1; offset 0; oldest xid 479 in DB 1; oldest multi 1 in DB 12723; oldest/newest commit timestamp xid: 0/0; oldest running xid 58215; online
可以看到日志记录了CHECKPOINT_ONLINE信息,checkpoint start的LSN在单词“redo”之后输出,这个位置对应checkpoint start时间最后一个WAL记录。
5、查看控制文件信息,可知控制文件记录了最近的checkpoint点对应的lsn信息
pg_controldata -D /usr/local/pgsql/data/ |egrep \'Latest.*location\'
Latest checkpoint location: 3/8A0B3848 Latest checkpoint\'s REDO location: 3/8A0B3810
故障后恢复
如果服务器出现故障,则在后续启动时,会通过查看pg_control控制文件,查找与“关闭”不同的状态来检测此情况。在这种情况下进行自动恢复。
1、直接kill掉postgres主进程
2、查看控制文件Database cluster state状态,没有发生变化
pg_controldata -D /usr/local/pgsql/data/ |grep state -------- Database cluster state: in production
3、启动数据库,查看日志
pg_ctl -D /usr/local/pgsql/data/ start

可知故障后,数据库从Latest checkpoint\'s REDO location开始恢复数据
正常关闭后恢复
1、记录当前的lsn
SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
3/8B0000A0
(1 row)
2、正常关闭数据库
pg_ctl -D /usr/local/pgsql/data/ stop
3、查看控制文件Database cluster state状态,可知正确记录了关闭状态
pg_controldata -D /usr/local/pgsql/data/ |grep state
Database cluster state: shut down
4、查看wal日志, 拥有最终检查点的唯一记录(CHECKPOINT_SHUTDOWN)
/usr/local/pgsql/bin/pg_waldump -p /usr/local/pgsql/data/pg_wal/ -s 3/8B0000A0 00000001000000030000008B
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 3/8B0000A0, prev 3/8B000028, desc: RUNNING_XACTS nextXid 58215 latestCompletedXid 58214 oldestRunningXid 58215 rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 3/8B0000D8, prev 3/8B0000A0, desc: CHECKPOINT_SHUTDOWN redo 3/8B0000D8; tli 1; prev tli 1; fpw true; xid 0:58215; oid 34053; multi 1; offset 0; oldest xid 479 in DB 1; oldest multi 1 in DB 12723; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown pg_waldump: fatal: error in WAL record at 3/8B0000D8: invalid record length at 3/8B000150: wanted 24, got 0
5、再次启动数据库,可知数据库正常启动,无恢复操作

以上是关于PostgreSQL故障恢复能力之检查点(Checkpoint)的主要内容,如果未能解决你的问题,请参考以下文章