日常Bug排查-系统失去响应-Redis使用不当
Posted jinnan88
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日常Bug排查-系统失去响应-Redis使用不当相关的知识,希望对你有一定的参考价值。
日常Bug排查-系统失去响应-Redis使用不当
前言
日常Bug排查系列都是一些简单Bug排查,笔者将在这里介绍一些排查Bug的简单技巧,同时顺便积累素材^_^。
Bug现场
开发反应线上系统出现失去响应的现象,收到业务告警已经频繁MarkAndSweep(Full GC)告警。于是找到笔者进行排查。
看基础监控
首先呢,当然是看我们的监控了,找到对应失去响应的系统的ip,看下我们的基础监控。 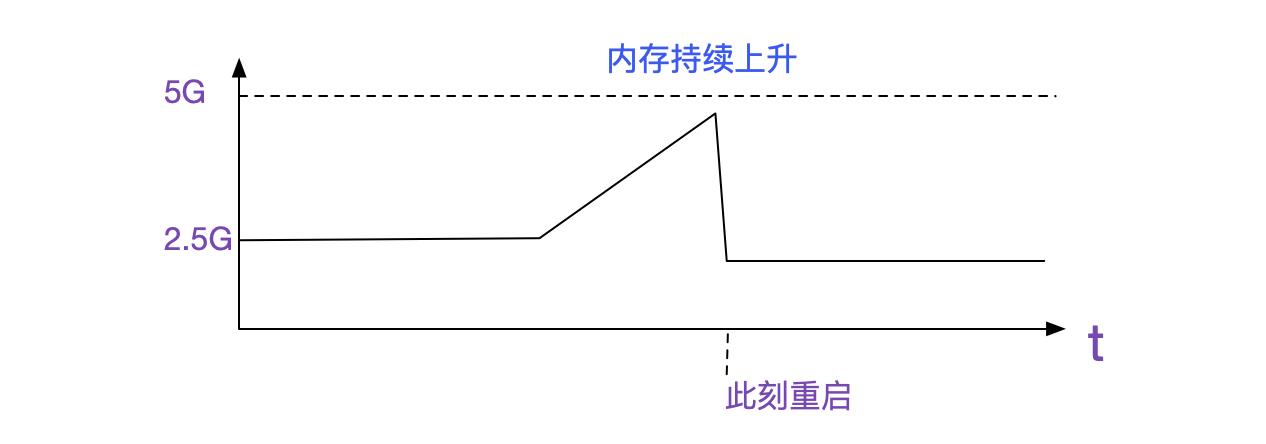
机器内存持续上升。因为我们是java系统,堆的大小一开始已经设置了最大值。
--XX:Xms2g -Xmx2g
所以看上去像堆外内存泄露。而FullGC告警只是堆外内存后一些关联堆内对象触发。
看应用监控
第二步,当然就是观察我们的应用监控,这边笔者用的是CAT。观察Cat中对应应用的情况,很容易发现,其ActiveThread呈现不正常的现象,竟然达到了5000+多个,同时和内存上升曲线保持一致。 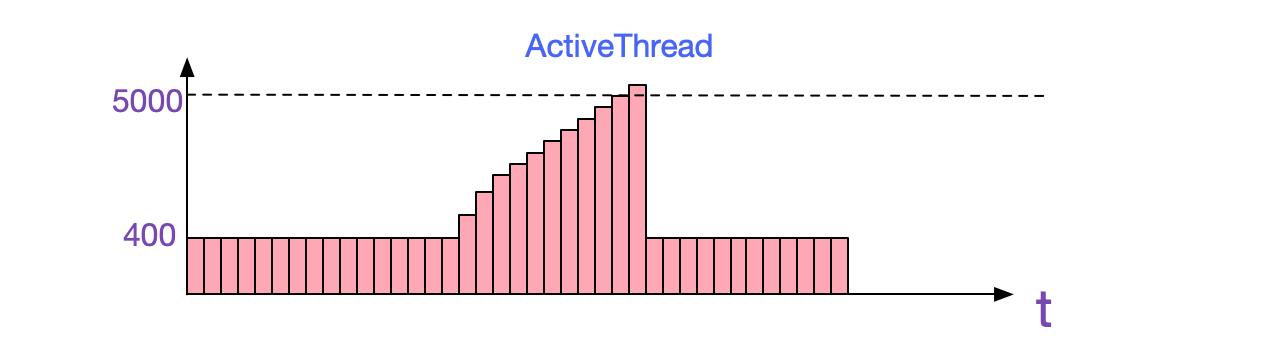
jstack
java应用中遇到线程数过多的现象,首先我们考虑的是jstack,jstack出来对应的文件后。我们less一下,发现很多线程卡在下面的代码栈上。
"Thread-1234
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park
......
at org.apache.commons.pool2.impl.LinkedBlockingQueue.takeFirst
......
at redis.clients.util.Pool.getResource
很明显的,这个代码栈值得是没有获取连接,从而卡住。至于为什么卡这么长时间而不释放,肯定是由于没设置超时时间。那么是否大部分线程都卡在这里呢,这里我们做一下统计。
cat jstack.txt | grep \'prio=\' | wc -l
======> 5648
cat jstack.txt | grep \'redis.clients.util.Pool.getResource\'
======> 5242
可以看到,一共5648个线程,有5242,也就是92%的线程卡在Redis getResource中。
看下redis情况
netstat -anp | grep 6379
tcp 0 0 1.2.3.4:111 3.4.5.6:6379 ESTABLISHED
......
一共5个,而且连接状态为ESTABLISHED,正常。由此可见他们配置的最大连接数是5(因为别的线程正在得到获取Redis资源)。
Redis连接泄露
那么很自然的想到,Redis连接泄露了,即应用获得Redis连接后没有还回去。这种泄露有下面几种可能:
情况1: 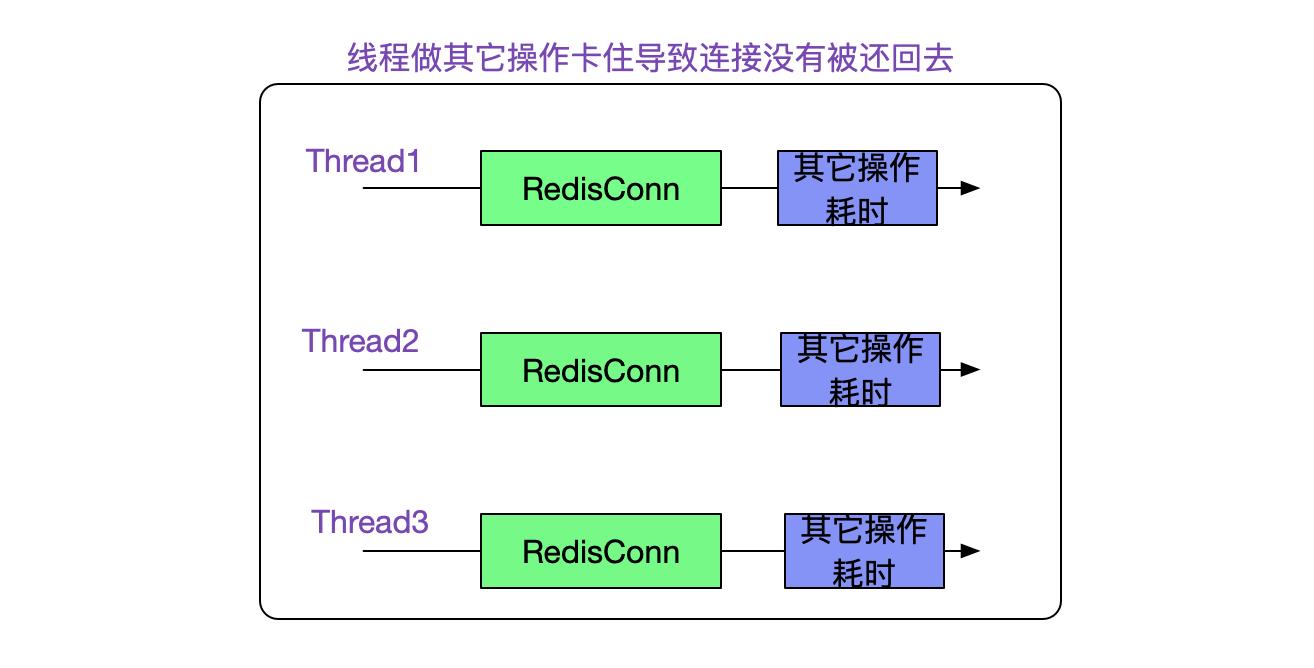
情况2:
情况3:
调用Redis卡住,由于其它机器是好的,故排除这种情况。
如何区分
我们做个简单的推理:
如果是情况1,那么这个RedisConn肯定可以通过内存可达性分析和Thread关联上,而且这个关联关系肯定会关联到某个业务操作实体(例如code stack or 业务bean)。那么我们只要观察其在堆内的关联路线是否和业务相关即可,如果没有任何关联,那么基本断定是情况2了。
可达性分析
我们可以通过jmap dump出应用内存,然后通过MAT(Memory Analysis Tool)来进行可达性分析。
首先找到RedisConn
将dump文件在MAT中打开,然后运行OQL:
select * from redis.clients.jedis.Jedis (RedisConn的实体类)
搜索到一堆Jedis类,然后我们执行
Path To GCRoots->with all references
可以看到如下结果:
redis.clients.jedis.Jedis
|->object
|->item
|->first
|->...
|->java.util.TimerThread
|->internalPool
由此可见,我们的连接仅仅被TimerThread和internalPool(Jedis本身的连接池)持有。所以我们可以判断出大概率是情况2,即忘了归还连接。翻看业务代码:
伪代码
void lock(){
conn = jedis.getResource()
conn.setNx()
// 结束,此处应该有finally{returnResource()}或者采用RedisTemplate
}
最后就是很简单的,业务开发在执行setNx操作后,忘了将连接还回去。导致连接泄露。
如果是情况1如何定位卡住的代码
到此为止,这个问题时解决了。但是如果是情况1的话,我们又该如何分析下去呢?很简单,我们如果找到了jedis被哪个业务线程拥有,直接从heap dump找到其线程号,然后取Jstack中搜索即可知道其卡住的代码栈。
jmap:
redis.clients.jedis.Jedis
|->Thread-123
jstack:
Thread-123 prio=...
at xxx.xxx.xxx.blocked
总结
这是一个很简单的问题,知道套路之后排查起来完全不费事。虽然最后排查出来是个很低级的代码,但是这种分析方法值得借鉴。
以上是关于日常Bug排查-系统失去响应-Redis使用不当的主要内容,如果未能解决你的问题,请参考以下文章
记一次因 Redis 使用不当导致应用卡死 bug 的排查及解决!