Vue源码-手写mustache源码
Posted 会飞的一棵树
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Vue源码-手写mustache源码相关的知识,希望对你有一定的参考价值。
引言
在Vue中使用模板语法能够非常方便的将数据绑定到视图中,使得在开发中可以更好的聚焦到业务逻辑的开发。
mustache是一个很经典且优秀的模板引擎,vue中的模板引擎也对其有参考借鉴,了解它能更好的知道vue的模板引擎实现的原理。
数据转换为视图的方案
Vue的核心之一就是数据驱动,而模板引擎就是实现数据驱动上的很重要一环。借助模板引擎能够方便的将数据转换为视图,那么常用转换的方案有哪些呢。
- 纯 DOM 法,使用 JS 操作 DOM,创建和新增 DOM 将数据放在视图中。(直接干脆,但在处理复杂数据时比较吃力)
- 数组 Join 法,利用数组可以换行写的特性,[].jion(\'\')成字符传,再使用 innerhtml。(能保证模板的可读和可维护性)
<div id="container"></div>
<script>
// 数据
const data = { name: "Tina", age: 11, sex: "girl"};
// 视图
let templateArr = [
" <div>",
" <div>" + data.name + "<b> infomation</b>:</div>",
" <ul>",
" <li>name:" + data.name + "</li>",
" <li>sex:" + data.sex + "</li>",
" <li>age:" + data.age + "</li>",
" </ul>",
" </div>",
];
// jion成domStr
let domStr = templateArr.join(\'\');
let container = document.getElementById(\'container\');
container.innerHTML = domStr;
</script>
- ES6 的模板字符串。
- 模板引擎。
mustache使用示例
<!-- 引入mustache -->
<script src="https://cdn.bootcdn.net/ajax/libs/mustache.js/4.2.0/mustache.js"></script>
<div class="container"></div>
<script>
// 模板
var templateStr = `
<ul>
{{#arr}}
<li>
<div class="hd">{{name}}<b> infomation</b></div>
<div class="bd">
<p>name:{{name}}</p>
<p>sex:{{sex}}</p>
<p>age:{{age}}</p>
</div>
</li>
{{/arr}}
</ul>`;
// 数据
var data = {
arr: [
{ name: "Tina", age: 11, sex: "female", friends: ["Cate", "Mark"] },
{ name: "Bob", age: 12, sex: "male", friends: ["Tim", "Apollo"] },
{ name: "Lucy", age: 13, sex: "female", friends: ["Bill"] },
],
};
// 使用render方法生成绑定了数据的视图的DOM字符串
var domStr = Mustache.render(templateStr, data);
// 将domStr放在contianer中
var container = document.querySelector(".container");
container.innerHTML = domStr;
</script>
mustache实现原理
mustache会将模板转换为tokens,然将tokens和数据相结合,再生成dom字符串。tokens将模板字符串按不同类型进行拆分后封装成数组,其保存的是字符串对应的mustache识别信息。
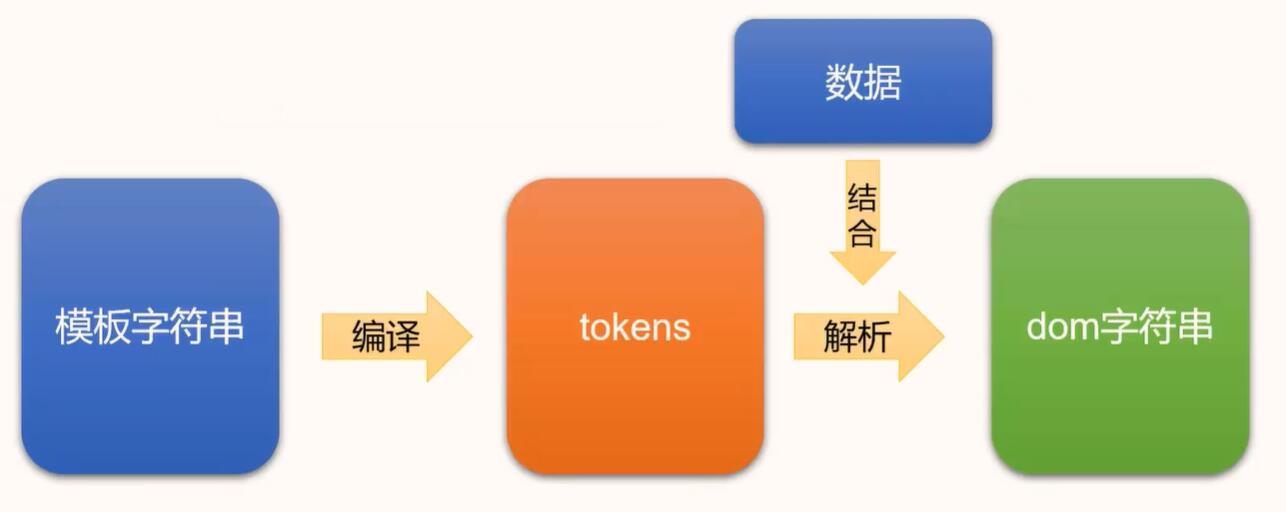
模板:
<ul>
{{#arr}}
<li>
<div class="hd">{{name}}<b> infomation</b></div>
<div class="bd">
<p>sex:{{sex}}</p>
<p>age:{{age}}</p>
</div>
</li>
{{/arr}}
</ul>
其转换的tokens(为排版方便清除部分空字符),这里tokens中的数字是,字符的开始和结束位置。
[
["text", "↵ <ul>↵", 0, 12],
["#", "arr", 22, 30, [
["text", "<li>↵<div class="hd">", 31, 78],
["name", "name", 78, 86],
["text", "<b> infomation</b></div>↵<div class="bd">↵↵ <p>sex:", 86, 166],
["name", "sex", 166, 173],
["text", "</p>↵<p>age:", 173, 201],
["name", "age", 201, 208],
["text", "</p>↵</div>↵</li>↵", 208, 252]
], 262
],
["text", "</ul>↵", 271, 289]
]
数据:
{
arr: [
{ name: "Tina", age: 11, sex: "female" },
{ name: "Bob", age: 12, sex: "male" }
]
}
生成后的Dom的字符串:
<ul>
<li>
<div class="hd">Tina<b> infomation</b></div>
<div class="bd">
<p>sex:female</p>
<p>age:11</p>
</div>
</li>
<li>
<div class="hd">Bob<b> infomation</b></div>
<div class="bd">
<p>sex:male</p>
<p>age:12</p>
</div>
</li>
</ul>
mustache关键源码
扫描模板字符串的Scanner
扫描器有两个主要方法。Scanner扫描器接收模板字符串作其构造的参数。在mustache中是以{{和}}作为标记的。
scan方法,扫描到标记就将指针移位,跳过标记。
scanUntil方法是会一直扫描模板字符串直到遇到标记,并将所扫描经过的内容进行返回。
export default class Scanner {
constructor(templateStr) {
// 将templateStr赋值到实例上
this.templateStr = templateStr;
// 指针
this.pos = 0;
// 尾巴字符串,从指针位置到字符结束
this.tail = templateStr;
}
// 扫描标记并跳过,没有返回
scan(tag) {
if (this.tail.indexOf(tag) === 0) {
// 指针跳过标记的长度
this.pos += tag.length;
this.tail = this.templateStr.substring(this.pos);
}
}
// 让指针进行扫描,直到遇见结束标记,并返回扫描到的字符
// 指针从0开始,到找到标记结束,结束位置为标记的第一位置
scanUntil(tag) {
const pos_backup = this.pos;
while (!this.eos() && this.tail.indexOf(tag) !== 0) {
this.pos++;
// 跟新尾巴字符串
this.tail = this.templateStr.substring(this.pos)
}
return this.templateStr.substring(pos_backup, this.pos);
}
// 判断指针是否到头 true结束
eos() {
return this.pos >= this.templateStr.length;
}
}
将模板转换为tokens的parseTemplateToTokens
export default function parseTemplateToTokens(templateStr) {
const startTag = "{{";
const endTag = "}}";
let tokens = [];
// 创建扫描器
let scanner = new Scanner(templateStr);
let word;
while (!scanner.eos()) {
word = scanner.scanUntil(startTag);
if (word !== \'\') {
tokens.push(["text", word]);
}
scanner.scan(startTag);
word = scanner.scanUntil(endTag);
// 判断扫描到的字是否是空
if (word !== \'\') {
if (word[0] === \'#\') {
// 判断{{}}之间的首字符是否为#
tokens.push(["#", word.substring(1)]);
} else if (word[0] === \'/\') {
// 判断{{}}之间的首字符是否为/
tokens.push(["/", word.substring(1)]);
} else {
// 都不是
tokens.push([\'name\', word]);
}
}
scanner.scan(endTag);
}
// 返回折叠处理过的tokens
return nestTokens(tokens);
}
处理tokens的折叠(数据循环时需)的nestToken
export default function nestTokens(tokens) {
// 结果数组
let nestedTokens = [];
// 收集器,初始指向结果数组
let collector = nestedTokens;
// 栈结构,用来临时存放有循环的token
let sections = [];
tokens.forEach((token, index) => {
switch (token[0]) {
case \'#\':
// 收集器中放token
collector.push(token);
// 入栈
sections.push(token);
// 将收集器指向当前token的第2项,且重置为空
collector = token[2] = [];
break;
case \'/\':
// 出栈
sections.pop();
// 判断栈中是否全部出完
// 若栈中还有值则将收集器指向栈顶项的第2位
// 否则指向结果数组
collector = sections.length > 0 ? sections[sections.length - 1][2] : nestedTokens;
break;
default:
// collector的指向是变化的
// 其变化取决于sections栈的变化
// 当sections要入栈的时候,collector指向其入栈项的下标2
// 当sections要出栈的时候,若栈未空,指向栈顶项的下标2
collector.push(token);
}
})
return nestedTokens;
}
在多层对象中深入取数据的lookup
该函数主要方便mustache取数据的。比如数据是多层的对象,模板中有{{school.class}},转换为token后是[\'name\',\'school.class\'],那么就能使用token[1](school.class)获取,其在data中对应的数据。然后将其替换过去。
data:{
school:{
class:{"English Cls"}
}
}
export default function lookup(dataObj, keyName) {
// \'.\'.split(\'.\') 为 ["", ""]
// 若是带点的取对象属性值
if (keyName.indexOf(\'.\') !== -1 && keyName !== \'.\') {
// 若有点符合则拆开
let keys = keyName.split(\'.\');
// 存放每层对象的临时变量
// 每深入一层对象,其引用就会更新为最新深入的对象
// 就像是对象褪去了一层皮
let temp = dataObj;
keys.forEach((item) => {
temp = temp[item]
})
return temp;
}
// 若没有点符号
return dataObj[keyName];
}
将tokens转换为Dom字符串的renderTemplate
这里有两个方法。renderTemplate和parseArray在遇到#时(有数据循环时),会相互调用形成递归。
export default function renderTemplate(tokens, data) {
// 结果字符串
let resultStr = \'\';
tokens.forEach(token => {
if (token[0] === \'text\') {
// 若是text直接将值进行拼接
resultStr += token[1];
} else if (token[0] === \'name\') {
// 若是name则增加name对应的data
resultStr += lookup(data, token[1]);
} else if (token[0] === \'#\') {
// 递归处理循环
resultStr += parseArray(token, data);
}
});
return resultStr;
}
// 用以处理循环中需要的使用的token
// 这里的token单独的一段token而不是整个tokens
function parseArray(token, data) {
// tData是当前token对应的data对象,不是整个的
// 相当于data也是会在这里拆成更小的data块
let tData = lookup(data, token[1]);
let resultStr = \'\';
// 在处理简单数组是的标记是{{.}}
// 判断是name后lookup函数返回的是dataObj[\'.\']
// 所以直接在其递归的data中添加{\'.\':element}就能循环简单数组
tData.forEach(element => {
resultStr += renderTemplate(token[2], { ...element, \'.\': element });
})
return resultStr;
}
gitee: https://gitee.com/mashiro-cat/notes-on-vue-source-code
以上是关于Vue源码-手写mustache源码的主要内容,如果未能解决你的问题,请参考以下文章