Understanding Tensorcore Computing Performance of Ampere
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Understanding Tensorcore Computing Performance of Ampere相关的知识,希望对你有一定的参考价值。
看到下面的白皮书的两段话:
Using FP16/FP32 mixed-precision Tensor Core operations as an example, at the hardware
level, each Tensor Core in the Volta architecture can execute 64 FP16 fused multiply-add
operations (FMAs) with FP32 accumulation per clock, allowing it to compute a mixed-precision
4x4x4 matrix multiplication per clock. Since each Volta SM includes eight Tensor Cores, a
single SM delivers 512 FP16 FMA operations per clock or 1024 individual FP16 floating point
operations per clock. Each of the A100 Tensor Cores can execute 256 FP16 FMA operations
per clock, allowing it to compute the results for an 8x4x8 mixed-precision matrix multiplication
per clock. Each SM in the A100 GPU includes four of the new redesigned Tensor Cores and
therefore each SM in A100 delivers 1024 FP16 FMA operations per clock (or 2048 individual
FP16 floating point operations per clock)
Comparing total GPU performance, not just SM-level performance, the NVIDIA A100 Tensor
Core GPU with its 108 SMs includes a total of 432 Tensor Cores that deliver up to 312 TFLOPS
of dense mixed-precision FP16/FP32 performance.
结合这个文章的介绍:
对Tensore Core带来的加速算力有了进一步的理解:
使用Tensor Core执行混合精度运算为例;
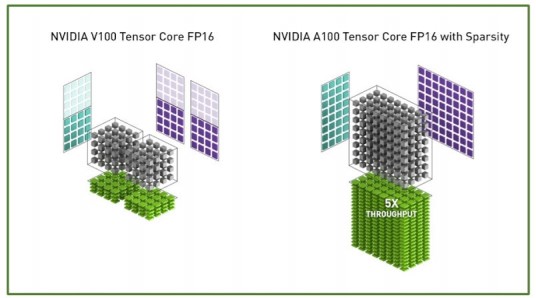
对Volta:
矩阵大小是[4*4]FP16*[4*4]FP16+[4*4]FP32
在硬件层面,一个Volta的Tensor Core在一个时钟周期可以执行4^3=64个FP16的乘法和FP32的加法运算;那么单时钟的混合精度的算力就是4^3个FMA;
SM有8个Tensor Core,那么1个SM可以提供8*64=512个FP16 FMA,也就是1024 FP16 FLOPS;
对Ampere:
矩阵大小是[8*4]FP16*[4*8]FP16+[8*8]FP32
每个A100的Tensor Core每个周期可以执行的是8*4*8=256个FP16的乘法和FP32的加法运算;那么单时钟的混合精度的算力就是256个FMA;
SM有8个Tensor Core,那么1个SM可以提供4*256=1024个FP16 FMA,也就是2048 FP16 FLOPS;
考虑A100有108个SM,工作在1410MHz,那么算力就是108SM*1410MHz*2048 FP16 FLOPS=312 FP16 TFLOPS
考虑到FP64Core是Tensor Core的8倍,但是Tensor Core单周期是256个FP16 FMA,FP64 Core单周期是1个FP64 FMA,因此使用Tensore Core的FP16算力是FP64算力的256/8=32倍;不使用的时候是4倍。FP64是9.7TFLOPS。
以上是关于Understanding Tensorcore Computing Performance of Ampere的主要内容,如果未能解决你的问题,请参考以下文章