后期数据库主从架构的痛点,真的痛
Posted 猿天地
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了后期数据库主从架构的痛点,真的痛相关的知识,希望对你有一定的参考价值。
原创:猿天地(微信公众号ID:cxytiandi),欢迎分享,转载请保留出处。
读写分离是什么?读写分离的作用就不讲了,如果有不了解的同学可以自己去搜索资料进行了解。或者查看我之前的文章读写分离。
一开始的场景肯定都基于主库去做增删改查的操作,等后面压力慢慢上来后才会考虑加数据库的从节点,通过读写分离的方式来提高查询的性能。

首先读写分离默认查询都是走从节点的。
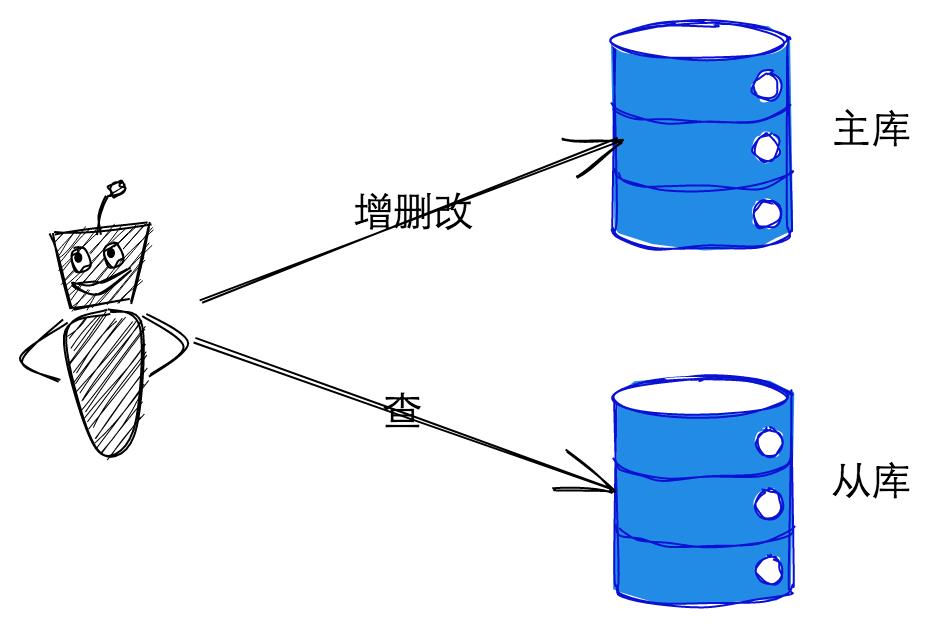
从我们的使用习惯或者业务的场景来说,查询的场景是大于增删改的。所以我们会在需要走主库进行数据操作的业务场景下,手动去控制这条Sql要去主库执行,这个控制的逻辑可以自己写,也可以利用框架自带的功能实现,就不细讲了。
比如我们定义一个注解 @Master 用于标记此方法走主库操作,然后通过Aspect可以去切换数据源。这其实是很常见的实现方式,如果说你一开始就有从节点,就规范了这么做是没问题的,如果是后面新增了从节点要开始做读写分离,这么做是存在问题的。
一旦这么做的话,对于增删改的操作没有问题,对于查的操作可能会有问题。这个问题不是说有Bug,而是有一些体验上的问题可能会导致Bug。大家都知道主从架构其实是存在数据延迟的问题,只要有延迟那么就有可能出现问题。
某些业务场景下,你新增了一条数据,然后会马上跳到详情去,此时如果数据有延迟,到详情的时候去查询从节点,就查不到刚刚新增的数据,会存在这样的问题。
解决办法就是把所有业务场景都整理下,然后让测试整体回归一遍,将需要走主库操作的查询方法都加上 @Master 注解,就不会有问题了。
看似没有任何问题,其实大家忽略了一点就是时间成本问题。要整理业务场景,要整体回归测试,这些都是要花时间的,时间就是最大的成本。
所以我们在后期做读写分离的时候,基本上不会采用上面的方式去实现,因为业务功能越多,成本越高。
真正的做法是反着来,无论实现任何新功能,我们都要考虑的点就是如何让影响最小?如何不影响之前的逻辑?
方法就是所有的老逻辑都不动,默认还是走主库,但是我们程序中已经做了读写分离的功能,默认查询就是会走从库的,所以第一步就是要将所有查询的Sql都发往主库,可以通过Aspect实现。
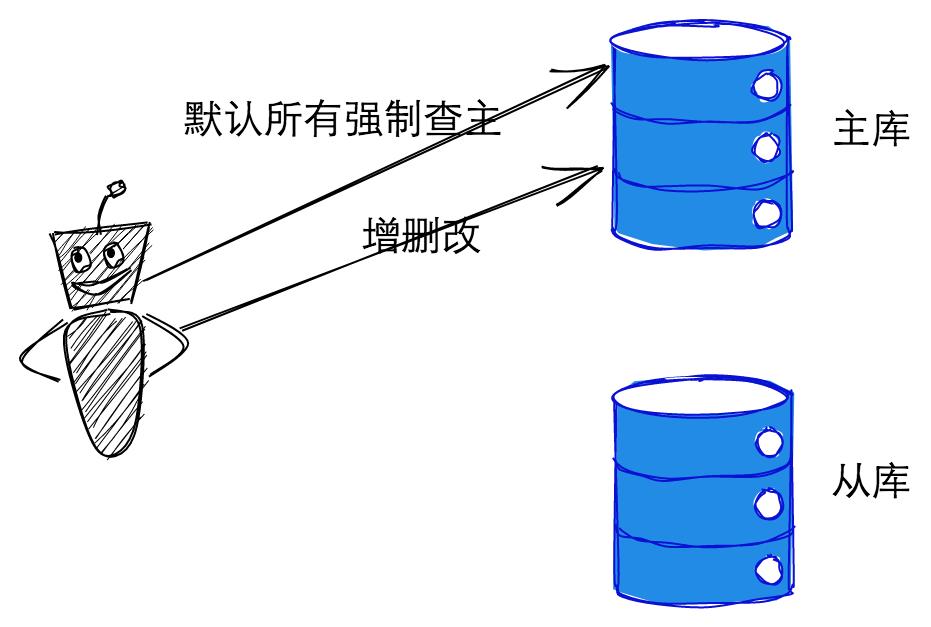
做完了上面这一步就可以直接上线了,因为所有的操作还是走的主库,跟以前没有任何区别,不会影响任何老的逻辑。
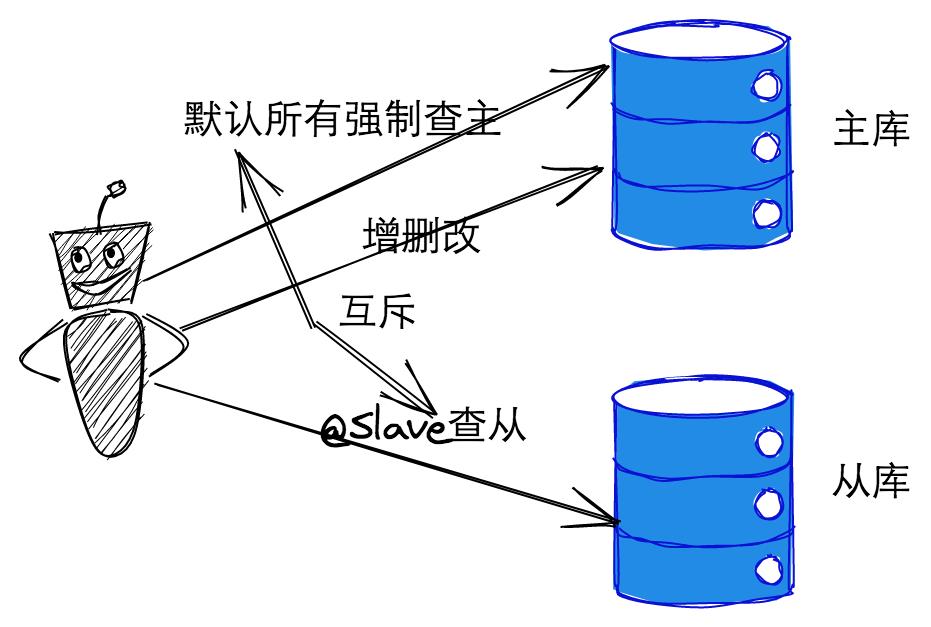
现在就要考虑哪些查询可以走从库了,但是这个动作可以慢慢做,可以慢慢梳理。这样就会比较轻松了,每个迭代我们可以梳理几个走从库的查询,直接加个 @Slave 的注解让它强制走从库,这个场景我们梳理过,验证过是没问题的。就这样慢慢的整理,直到所有老逻辑都梳理完。
好的思路能够保证稳定性和易用性,如果有收获那就点个赞呗!
关于作者:尹吉欢,简单的技术爱好者,《Spring Cloud微服务-全栈技术与案例解析》, 《Spring Cloud微服务 入门 实战与进阶》作者, 公众号猿天地发起人。
以上是关于后期数据库主从架构的痛点,真的痛的主要内容,如果未能解决你的问题,请参考以下文章
Redis主从与哨兵架构详解 Redis主从架构 如何在同一台机器搭建主从架构 Redis主从工作原理 数据部分复制 Jedis使用 Redis的管道(Pipeline) Redis Lua脚本(代码