Kubernetes业务log-pilot日志收集实战配置-elkf
Posted Serverless和DevOps技术分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes业务log-pilot日志收集实战配置-elkf相关的知识,希望对你有一定的参考价值。
Kubernetes业务日志收集实战
> 本次所用到的插件有elasticsearch、logstash、kafka、zookeeper、log-pilot、kibana
OK,那么到目前为止,我们的服务顺利容器化并上了K8s,同时也能通过外部网络进行请求访问,相关的服务数据也能进行持久化存储了,那么接下来很关键的事情,就是怎么去收集服务产生的日志进行数据分析及问题排查,怎么去监控服务的运行是否正常,下面会以生产中的经验来详细讲解这两大块。
日志收集方案总结
现在市面上大多数课程都是以EFK来作来K8s项目的日志解决方案,它包括三个组件:Elasticsearch, Fluentd(filebeat), Kibana;Elasticsearch 是日志存储和日志搜索引擎,Fluentd 负责把k8s集群的日志发送给 Elasticsearch, Kibana 则是可视化界面查看和检索存储在 Elasticsearch 的数据。
但根据生产中实际使用情况来看,它有以下弊端:
1、日志收集系统 EFK是在每个kubernetes的NODE节点以daemonset的形式启动一个fluentd的pod,来收集NODE节点上的日志,如容器日志(/var/log/containers/*.log),但里面无法作细分,想要的和不想要的都收集进来了,带来的后面就是磁盘IO压力会比较大,日志过滤麻烦。
2、无法收集对应POD里面的业务日志 上面第1点只能收集pod的stdout日志,但是pod内如有需要收集的业务日志,像pod内的/tmp/datalog/*.log,那EFK是无能为力的,只能是在pod内启动多个容器(filebeat)去收集容器内日志,但这又会带来的是pod多容器性能的损耗,这个接下来会详细讲到。
3、fluentd的采集速率性能较低,只能不到filebeat的1/10的性能。
基于此,我通过调研发现了阿里开源的智能容器采集工具 Log-Pilot,github地址:
https://github.com/AliyunContainerService/log-pilot
下面以sidecar 模式和log-pilot这两种方式的日志收集形式做个详细对比说明:
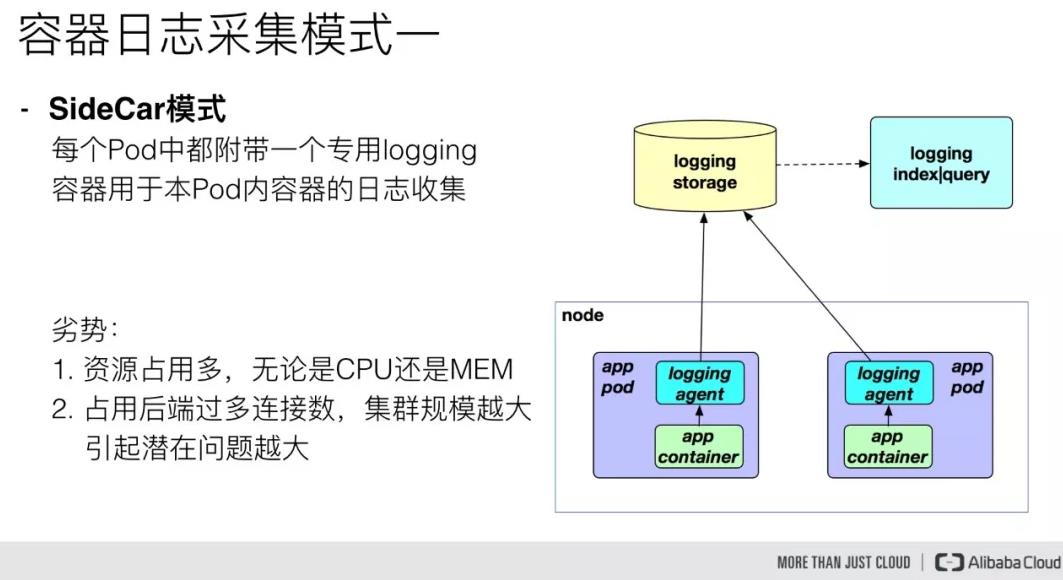
第一种模式是 sidecar 模式,这种需要我们在每个 Pod 中都附带一个 logging 容器来进行本 Pod 内部容器的日志采集,一般采用共享卷的方式,但是对于这一种模式来说,很明显的一个问题就是占用的资源比较多,尤其是在集群规模比较大的情况下,或者说单个节点上容器特别多的情况下,它会占用过多的系统资源,同时也对日志存储后端占用过多的连接数。当我们的集群规模越大,这种部署模式引发的潜在问题就越大。
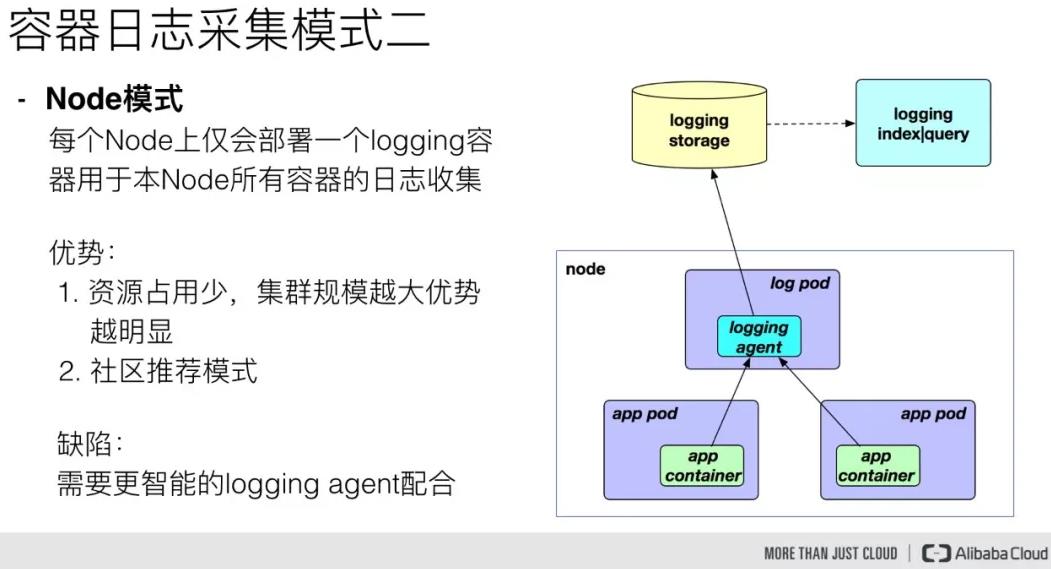
另一种模式是 Node 模式,这种模式是我们在每个 Node 节点上仅需部署一个 logging 容器来进行本 Node 所有容器的日志采集。这样跟前面的模式相比最明显的优势就是占用资源比较少,同样在集群规模比较大的情况下表现出的优势越明显,同时这也是社区推荐的一种模式。
经过多方面测试,log-pilot对现有业务pod侵入性很小,只需要在原有pod的内传入几行env环境变量,即可对此pod相关的日志进行收集,已经测试了后端接收的工具有logstash、elasticsearch、kafka、redis、file,均OK,下面开始部署整个日志收集环境。
方案一实例:log-pilot直达elasticsearch6
我们这里用一个tomcat服务来模拟业务服务,用log-pilot分别收集它的stdout以及容器内的业务数据日志文件到指定后端存储(这里分别以elasticsearch、kafka的这两种企业常用的接收工具来做示例)
日志收集数据链路如下:
log-pilot ---> elasticsearch6.8 ---> kibana6.8
准备好相应的yaml配置
> vim tomcat-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tomcat
name: tomcat
spec:
replicas: 1
selector:
matchLabels:
app: tomcat
template:
metadata:
labels:
app: tomcat
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
containers:
- name: tomcat
image: "tomcat:7.0"
env: # 注意点一,添加相应的环境变量(下面收集了两块日志1、stdout 2、/usr/local/tomcat/logs/catalina.*.log)
- name: aliyun_logs_tomcat-syslog # 如日志发送到es,那index名称为 tomcat-syslog
value: "stdout"
- name: aliyun_logs_tomcat-access # 如日志发送到es,那index名称为 tomcat-access
value: "/usr/local/tomcat/logs/catalina.*.log"
volumeMounts: # 注意点二,对pod内要收集的业务日志目录需要进行共享,可以收集多个目录下的日志文件
- name: tomcat-log
mountPath: /usr/local/tomcat/logs
volumes:
- name: tomcat-log
emptyDir: {}
> vim elasticsearch.6.8.13-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
k8s-app: elasticsearch-logging
version: v6.8.13
name: elasticsearch-logging
# namespace: logging
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: elasticsearch-logging
version: v6.8.13
serviceName: elasticsearch-logging
template:
metadata:
labels:
k8s-app: elasticsearch-logging
version: v6.8.13
spec:
nodeSelector:
esnode: "true" ## 注意给想要运行到的node打上相应labels
containers:
- env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: cluster.name
value: elasticsearch-logging-0
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
image: elastic/elasticsearch:6.8.13
name: elasticsearch-logging
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- mountPath: /usr/share/elasticsearch/data
name: elasticsearch-logging
dnsConfig:
options:
- name: single-request-reopen
initContainers:
- command:
- /sbin/sysctl
- -w
- vm.max_map_count=262144
image: alpine:3.12
imagePullPolicy: IfNotPresent
name: elasticsearch-logging-init
resources: {}
securityContext:
privileged: true
- name: fix-permissions
image: alpine:3.12
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: elasticsearch-logging
mountPath: /usr/share/elasticsearch/data
volumes:
- name: elasticsearch-logging
hostPath:
path: /esdata
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: elasticsearch-logging
name: elasticsearch
# namespace: logging
spec:
ports:
- port: 9200
protocol: TCP
targetPort: db
selector:
k8s-app: elasticsearch-logging
type: ClusterIP
> vim kibana.6.8.13.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
# namespace: logging
labels:
app: kibana
spec:
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: elastic/kibana:6.8.13
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
---
apiVersion: v1
kind: Service
metadata:
name: kibana
# namespace: logging
labels:
app: kibana
spec:
ports:
- port: 5601
protocol: TCP
targetPort: 5601
type: ClusterIP
selector:
app: kibana
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
# namespace: logging
spec:
rules:
- host: kibana.boge.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 5601
> vim log-pilot.yml # 后端输出的elasticsearch
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-pilot
labels:
app: log-pilot
# 设置期望部署的namespace
# namespace: ns-elastic
spec:
selector:
matchLabels:
app: log-pilot
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: log-pilot
annotations:
scheduler.alpha.kubernetes.io/critical-pod: \'\'
spec:
# 是否允许部署到Master节点上
#tolerations:
#- key: node-role.kubernetes.io/master
# effect: NoSchedule
containers:
- name: log-pilot
# 版本请参考https://github.com/AliyunContainerService/log-pilot/releases
image: registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-filebeat
resources:
limits:
memory: 500Mi
requests:
cpu: 200m
memory: 200Mi
env:
- name: "NODE_NAME"
valueFrom:
fieldRee:
fieldPath: spec.nodeName
##--------------------------------
# - name: "LOGGING_OUTPUT"
# value: "logstash"
# - name: "LOGSTASH_HOST"
# value: "logstash-g1"
# - name: "LOGSTASH_PORT"
# value: "5044"
##--------------------------------
- name: "LOGGING_OUTPUT"
value: "elasticsearch"
## 请确保集群到ES网络可达
- name: "ELASTICSEARCH_HOSTS"
value: "elasticsearch:9200"
## 配置ES访问权限
#- name: "ELASTICSEARCH_USER"
# value: "{es_username}"
#- name: "ELASTICSEARCH_PASSWORD"
# value: "{es_password}"
##--------------------------------
## https://github.com/AliyunContainerService/log-pilot/blob/master/docs/filebeat/docs.md
## to file need configure 1
# - name: LOGGING_OUTPUT
# value: file
# - name: FILE_PATH
# value: /tmp
# - name: FILE_NAME
# value: filebeat.log
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: root
mountPath: /host
readOnly: true
- name: varlib
mountPath: /var/lib/filebeat
- name: varlog
mountPath: /var/log/filebeat
- name: localtime
mountPath: /etc/localtime
readOnly: true
## to file need configure 2
# - mountPath: /tmp
# name: mylog
livenessProbe:
failureThreshold: 3
exec:
command:
- /pilot/healthz
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
- name: root
hostPath:
path: /
- name: varlib
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: varlog
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /etc/localtime
## to file need configure 3
# - hostPath:
# path: /tmp/mylog
# type: ""
# name: mylog
先创建一个测试用的命名空间:
# kubectl create ns testlog
收集日志到elasticserach
部署es 和 kibana:
# kubectl -n testlog apply -f elasticsearch.6.8.13-statefulset.yaml
# kubectl -n testlog apply -f kibana.6.8.13.yaml
部署log-pilot
# kubectl -n testlog apply -f log-pilot.yml
部署tomcat
# kubectl -n testlog apply -f tomcat-test.yaml
然后通过kibana域名kibana.boge.com来创建索引,查看日志是否已经被收集到es了。
方案二实例:业务日志增加kafka缓冲--->logstash过滤--->elasticsearch实战
在实际生产环境中,我们的业务日志可能会非常多,这时候建议收集时直接先缓存到KAFKA,然后根据后面我们的实际需求来消费KAFKA里面的日志数据,转存到其他地方,这里接上面继续,我以一个logstash来收集KAFKA里面的日志数据到最新版本的elasticsearch里面(正好也解决了log-pilot不支持elasticsearch7以上版本的问题)
完整的日志收集架构链路如下:
log-pilot ---> kafka ---> logstash ---> elasticsearch7 ---> kibana7
配置测试tomcat
准备好相应的yaml配置
> vim tomcat-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tomcat
name: tomcat
namespace: logging
spec:
replicas: 1
selector:
matchLabels:
app: tomcat
template:
metadata:
labels:
app: tomcat
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
containers:
- name: tomcat
image: "tomcat:7.0"
env: # 注意点一,添加相应的环境变量(下面收集了两块日志1、stdout 2、/usr/local/tomcat/logs/catalina.*.log)
- name: aliyun_logs_tomcat-syslog # 如日志发送到es,那index名称为 tomcat-syslog
value: "stdout"
- name: aliyun_logs_tomcat-access # 如日志发送到es,那index名称为 tomcat-access
value: "/usr/local/tomcat/logs/catalina.*.log"
volumeMounts: # 注意点二,对pod内要收集的业务日志目录需要进行共享,可以收集多个目录下的日志文件
- name: tomcat-log
mountPath: /usr/local/tomcat/logs
volumes:
- name: tomcat-log
emptyDir: {}
配置log-pilot并设置输出到kafka
> vim log-pilot2-kafka.yaml #后端输出到kafka
---
apiVersion: v1
kind: ConfigMap
metadata:
name: log-pilot2-configuration
namespace: logging
data:
logging_output: "kafka"
kafka_brokers: "10.0.1.204:9092"
kafka_version: "0.10.0"
# configure all valid topics in kafka
# when disable auto-create topic
kafka_topics: "tomcat-syslog,tomcat-access"
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-pilot2
#namespace: ns-elastic
labels:
k8s-app: log-pilot2
spec:
selector:
matchLabels:
k8s-app: log-pilot2
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
k8s-app: log-pilot2
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: log-pilot2
#
# wget https://github.com/AliyunContainerService/log-pilot/archive/v0.9.7.zip
# unzip log-pilot-0.9.7.zip
# vim ./log-pilot-0.9.7/assets/filebeat/config.filebeat
# ...
# output.kafka:
# hosts: [$KAFKA_BROKERS]
# topic: \'%{[topic]}\'
# codec.format:
# string: \'%{[message]}\'
# ...
image: registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-filebeat
env:
- name: "LOGGING_OUTPUT"
valueFrom:
configMapKeyRee:
name: log-pilot2-configuration
key: logging_output
- name: "KAFKA_BROKERS"
valueFrom:
configMapKeyRee:
name: log-pilot2-configuration
key: kafka_brokers
- name: "KAFKA_VERSION"
valueFrom:
configMapKeyRee:
name: log-pilot2-configuration
key: kafka_version
- name: "NODE_NAME"
valueFrom:
fieldRee:
fieldPath: spec.nodeName
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: logs
mountPath: /var/log/filebeat
- name: state
mountPath: /var/lib/filebeat
- name: root
mountPath: /host
readOnly: true
- name: localtime
mountPath: /etc/localtime
# configure all valid topics in kafka
# when disable auto-create topic
- name: config-volume
mountPath: /etc/filebeat/config
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
type: Socket
- name: logs
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
- name: state
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: root
hostPath:
path: /
type: Directory
- name: localtime
hostPath:
path: /etc/localtime
type: File
# kubelet sync period
- name: config-volume
configMap:
name: log-pilot2-configuration
items:
- key: kafka_topics
path: kafka_topics
本地Docker环境准备Kafka和Zookeeper
> 准备一个测试用的kafka服务
# 部署前准备
# 0. 先把代码pull到本地
# https://github.com/wurstmeister/kafka-docker
# 修改docker-compose.yml为:
#——------------------------------
version: \'2\'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
#build: .
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAMe: 10.0.1.204 # docker运行的机器IP
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /nfs_storageclass/kafka:/kafka
#——------------------------------
# 1. docker-compose setup:
# docker-compose up -d
Recreating kafka-docker-compose_kafka_1 ... done
Starting kafka-docker-compose_zookeeper_1 ... done
# 2. result look:
# docker-compose ps
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------
kafka-docker-compose_kafka_1 start-kafka.sh Up 0.0.0.0:9092->9092/tcp
kafka-docker-compose_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 0.0.0.0:2181->2181/tcp, 22/tcp,
2888/tcp, 3888/tcp
# 3. run test-docker
bash-4.4# docker run --rm -v /var/run/docker.sock:/var/run/docker.sock -e HOST_IP=10.0.1.204 -e ZK=10.0.1.204:2181 -i -t wurstmeister/kafka /bin/bash
# 4. list topic
bash-4.4# kafka-topics.sh --zookeeper 10.0.1.204:2181 --list
tomcat-access
tomcat-syslog
# 列出所有的组,并查看组里面的topic和logstash的连接关系
kafka-consumer-groups.sh --bootstrap-server 10.10.147.43:9092 --group logstash --describe
# 5. consumer topic data:
bash-4.4# kafka-console-consumer.sh --bootstrap-server 10.0.1.204:9092 --topic tomcat-access --from-beginning
收集日志到Kafka
# 先清除上面的配置
# kubectl -n testlog delete -f elasticsearch.6.8.13-statefulset.yaml
# kubectl -n testlog delete -f kibana.6.8.13.yaml
# kubectl -n testlog delete -f log-pilot.yml
# kubectl -n testlog delete -f tomcat-test.yaml
# 然后部署新配置的log-pilot以及测试kafka
# kubectl -n testlog apply -f log-pilot2-kafka.yaml
# 注意修改里面的configmap配置
apiVersion: v1
kind: ConfigMap
metadata:
name: log-pilot2-configuration
data:
logging_output: "kafka" # 指定输出到kafka服务
kafka_brokers: "10.0.1.204:9092" # kafka地址
kafka_version: "0.10.0" # 指定版本,生产中实测kafka_2.12-2.5.0及以下,这里都配置为"0.10.0" 就可以了
# configure all valid topics in kafka
# when disable auto-create topic
kafka_topics: "tomcat-syslog,tomcat-access" # 注意这里要把需要收集的服务topic给加到白名单这里,否则不给收集,而且同个服务里面都要加,否则都不会被收集
# kafka的部署配置上面已经贴出
# 重新部署下tomcat
# kubectl -n testlog delete -f tomcat-test.yaml
# 然后在kafka里面只要能列出相应topic并能对其进行消费就证明日志收集没问题了
tomcat-access
tomcat-syslog
配置Namespace和ES集群和Kibana
相关yaml配置如下:
> namespace.yaml
kind: Namespace
apiVersion: v1
metadata:
name: logging
> es-client-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: logging
name: elasticsearch-client-config
labels:
app: elasticsearch
role: client
data:
elasticsearch.yml: |-
cluster.name: ${CLUSTER_NAME}
node.name: ${NODE_NAME}
discovery.seed_hosts: ${NODE_LIST}
cluster.initial_master_nodes: ${MASTER_NODES}
network.host: 0.0.0.0
node:
master: false
data: false
ingest: true
xpack.security.enabled: true
xpack.monitoring.collection.enabled: true
> es-client-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: logging
name: elasticsearch-client
labels:
app: elasticsearch
role: client
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch
role: client
template:
metadata:
labels:
app: elasticsearch
role: client
spec:
containers:
- name: elasticsearch-client
image: elastic/elasticsearch:7.10.1
env:
- name: CLUSTER_NAME
value: elasticsearch
- name: NODE_NAME
value: elasticsearch-client
- name: NODE_LIST
value: elasticsearch-master,elasticsearch-data,elasticsearch-client
- name: MASTER_NODES
value: elasticsearch-master
- name: "ES_JAVA_OPTS"
value: "-Xms256m -Xmx256m"
ports:
- containerPort: 9200
name: client
- containerPort: 9300
name: transport
volumeMounts:
- name: config
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
readOnly: true
subPath: elasticsearch.yml
- name: storage
mountPath: /data
volumes:
- name: config
configMap:
name: elasticsearch-client-config
- name: "storage"
emptyDir:
medium: ""
initContainers:
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
> es-client-service.yaml
apiVersion: v1
kind: Service
metadata:
namespace: logging
name: elasticsearch-client
labels:
app: elasticsearch
role: client
spec:
ports:
- port: 9200
name: client
- port: 9300
name: transport
selector:
app: elasticsearch
role: client
> es-data-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: logging
name: elasticsearch-data-config
labels:
app: elasticsearch
role: data
data:
elasticsearch.yml: |-
cluster.name: ${CLUSTER_NAME}
node.name: ${NODE_NAME}
discovery.seed_hosts: ${NODE_LIST}
cluster.initial_master_nodes: ${MASTER_NODES}
network.host: 0.0.0.0
node:
master: false
data: true
ingest: false
xpack.security.enabled: true
xpack.monitoring.collection.enabled: true
> es-data-service.yaml
apiVersion: v1
kind: Service
metadata:
namespace: logging
name: elasticsearch-data
labels:
app: elasticsearch
role: data
spec:
ports:
- port: 9300
name: transport
selector:
app: elasticsearch
role: data
> es-data-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: logging
name: elasticsearch-data
labels:
app: elasticsearch
role: data
spec:
serviceName: "elasticsearch-data"
replicas: 1
selector:
matchLabels:
app: elasticsearch-data
template:
metadata:
labels:
app: elasticsearch-data
role: data
spec:
containers:
- name: elasticsearch-data
image: elastic/elasticsearch:7.10.1
env:
- name: CLUSTER_NAME
value: elasticsearch
- name: NODE_NAME
value: elasticsearch-data
- name: NODE_LIST
value: elasticsearch-master,elasticsearch-data,elasticsearch-client
- name: MASTER_NODES
value: elasticsearch-master
- name: "ES_JAVA_OPTS"
value: "-Xms300m -Xmx300m"
ports:
- containerPort: 9300
name: transport
volumeMounts:
- name: config
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
readOnly: true
subPath: elasticsearch.yml
- name: elasticsearch-data-persistent-storage
mountPath: /data/db
volumes:
- name: config
configMap:
name: elasticsearch-data-config
initContainers:
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: elasticsearch-data-persistent-storage
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-boge"
resources:
requests:
storage: 2Gi
> es-master-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: logging
name: elasticsearch-master-config
labels:
app: elasticsearch
role: master
data:
elasticsearch.yml: |-
cluster.name: ${CLUSTER_NAME}
node.name: ${NODE_NAME}
discovery.seed_hosts: ${NODE_LIST}
cluster.initial_master_nodes: ${MASTER_NODES}
network.host: 0.0.0.0
node:
master: true
data: false
ingest: false
xpack.security.enabled: true
xpack.monitoring.collection.enabled: true
> es-master-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: logging
name: elasticsearch-master
labels:
app: elasticsearch
role: master
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch
role: master
template:
metadata:
labels:
app: elasticsearch
role: master
spec:
containers:
- name: elasticsearch-master
image: elastic/elasticsearch:7.10.1
env:
- name: CLUSTER_NAME
value: elasticsearch
- name: NODE_NAME
value: elasticsearch-master
- name: NODE_LIST
value: elasticsearch-master,elasticsearch-data,elasticsearch-client
- name: MASTER_NODES
value: elasticsearch-master
- name: "ES_JAVA_OPTS"
value: "-Xms256m -Xmx256m"
ports:
- containerPort: 9300
name: transport
volumeMounts:
- name: config
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
readOnly: true
subPath: elasticsearch.yml
- name: storage
mountPath: /data
volumes:
- name: config
configMap:
name: elasticsearch-master-config
- name: "storage"
emptyDir:
medium: ""
initContainers:
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
> es-master-service.yaml
apiVersion: v1
kind: Service
metadata:
namespace: logging
name: elasticsearch-master
labels:
app: elasticsearch
role: master
spec:
ports:
- port: 9300
name: transport
selector:
app: elasticsearch
role: master
> kibana-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: logging
name: kibana-config
labels:
app: kibana
data:
kibana.yml: |-
server.host: 0.0.0.0
elasticsearch:
hosts: ${ELASTICSEARCH_URL}
username: ${ELASTICSEARCH_USER}
password: ${ELASTICSEARCH_PASSWORD}
> kibana-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: logging
name: kibana
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: elastic/kibana:7.10.1
env:
- name: ELASTICSEARCH_URL
value: "http://elasticsearch-client:9200"
- name: ELASTICSEARCH_USER
value: "elastic"
- name: ELASTICSEARCH_PASSWORD
valueFrom:
secretKeyRee:
name: elasticsearch-pw-elastic
key: password
resources:
limits:
cpu: 2
memory: 1.5Gi
requests:
cpu: 0.5
memory: 1Gi
ports:
- containerPort: 5601
name: kibana
protocol: TCP
volumeMounts:
- name: config
mountPath: /usr/share/kibana/config/kibana.yml
readOnly: true
subPath: kibana.yml
volumes:
- name: config
configMap:
name: kibana-config
> kibana-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: logging
labels:
component: kibana
spec:
selector:
app: kibana
ports:
- name: http
port: 5601
protocol: TCP
type: NodePort
开始部署新版本的es集群(开启了X-Pack安全配置):
> 注:这里为了节省资源,可以把上面创建的6版本的es和kibana给清理掉
# 部署es集群
kubectl apply -f namespace.yaml
kubectl apply -f es-master-configmap.yaml -f es-master-service.yaml -f es-master-deployment.yaml
kubectl apply -f es-data-configmap.yaml -f es-data-service.yaml -f es-data-statefulset.yaml
kubectl apply -f es-client-configmap.yaml -f es-client-service.yaml -f es-client-deployment.yaml
# 查看es是否正常运行
kubectl logs -f -n logging $(kubectl get pods -n logging | grep elasticsearch-master | sed -n 1p | awk \'{print $1}\') \\
| grep "Cluster health status changed from \\[YELLOW\\] to \\[GREEN\\]"
# 查看生成的es相关帐号密码(这里只用到了帐号elastic)
# kubectl exec -it $(kubectl get pods -n logging | grep elasticsearch-client | sed -n 1p | awk \'{print $1}\') -n logging -- bin/elasticsearch-setup-passwords auto -b
Changed password for user apm_system
PASSWORD apm_system = py0fZjuCP2Ky3ysc3TW6
Changed password for user kibana_system
PASSWORD kibana_system = ltgJNL8dw1nF34WLw9cQ
Changed password for user kibana
PASSWORD kibana = ltgJNL8dw1nF34WLw9cQ
Changed password for user logstash_system
PASSWORD logstash_system = biALFG4UYoc8h4TSxAJC
Changed password for user beats_system
PASSWORD beats_system = E5TdQ8LI33mTQRrJlD3r
Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = GtlT45XgtVvT5KpAp791
Changed password for user elastic
PASSWORD elastic = cR5SFjHajVOoGZPzfiEQ
# 创建elastic帐号的密码secret
kubectl create secret generic elasticsearch-pw-elastic -n logging --from-literal password=cR5SFjHajVOoGZPzfiEQ
# 创建kibana
kubectl apply -f kibana-configmap.yaml -f kibana-service.yaml -f kibana-deployment.yaml
> logstash.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: logging
name: logstash-configmap
data:
logstash.yml: |
http.host: "0.0.0.0"
path.config: /usr/share/logstash/pipeline
logstash.conf: |
# all input will come from filebeat, no local logs
input {
kafka {
bootstrap_servers => ["192.168.40.199:49153"] #填写kafka的地址加端口号
# bin/kafka-consumer-groups.sh --list --bootstrap-server localhost:9092
topics_pattern => "tomcat-.*"
consumer_threads => 5
decorate_events => true
codec => json
auto_offset_reset => "latest"
group_id => "boge"
}
}
filter {
}
output {
elasticsearch {
index => "%{[@metadata][kafka][topic]}-%{+YYYY-MM-dd}"
hosts => [ "${ELASTICSEARCH_URL}" ]
user => "${ELASTICSEARCH_USER}"
password => "${ELASTICSEARCH_PASSWORD}"
#cacert => \'/etc/logstash/certificates/ca.crt\'
}
stdout {
codec => rubydebug
}
}
---
#apiVersion: v1
#kind: Service
#metadata:
# labels:
# app: logstash
# name: logstash
#spec:
# ports:
# - name: "5044"
# port: 5044
# targetPort: 5044
# selector:
# app: logstash
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: logging
name: logstash
spec:
replicas: 1
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
containers:
- name: logstash
image: elastic/logstash:7.10.1
ports:
- containerPort: 5044
name: logstash
env:
- name: ELASTICSEARCH_URL
value: "http://elasticsearch-client:9200"
- name: ELASTICSEARCH_USER
value: "elastic"
- name: ELASTICSEARCH_PASSWORD
valueFrom:
secretKeyRef:
name: elasticsearch-pw-elastic
key: password
volumeMounts:
- name: config-volume
mountPath: /usr/share/logstash/config/
- name: logstash-pipeline-volume
mountPath: /usr/share/logstash/pipeline/
- name: localtime
mountPath: /etc/localtime
# - name: cert-ca
# mountPath: "/etc/logstash/certificates"
# readOnly: true
command:
- logstash
volumes:
- name: config-volume
configMap:
name: logstash-configmap
items:
- key: logstash.yml
path: logstash.yml
- name: logstash-pipeline-volume
configMap:
name: logstash-configmap
items:
- key: logstash.conf
path: logstash.conf
- name: localtime
hostPath:
path: /etc/localtime
type: File
# - name: cert-ca
# secret:
# secretName: elasticsearch-es-http-certs-public
logstash 配置成功之后,就可以通过kibana页面,访问es,检测到对应的es存储索引,然后再去kibana上创建对应的搜索索引,既可以。
注意
> 生产环境踩坑:
>
> 1. logstash这里需要先配置好,启动成功之后,kafka的topic才会进行创建出来,一定注意,需要确定kafka和logstash链接成功之后,再去写入大量日志。
>
> 2. 日志写入之后,如果topic的存储块不够,可以使用alter进行扩容
>
> > kafka-topics.sh --bootstrap-server 10.10.147.43:9092 --alter --topic java-info --partitions 100 >
>
> 3. 扩容之后也要增加对应logstash的机器,这里在生产环境中最容易出现瓶颈。
以上是关于Kubernetes业务log-pilot日志收集实战配置-elkf的主要内容,如果未能解决你的问题,请参考以下文章