python爬虫
Posted geeker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫相关的知识,希望对你有一定的参考价值。
前言
需要网站的,私信我(不玩套路那种)
分析
首先打开这个网站,看到由cloudflare,心里戈登一下,不慌,接着看
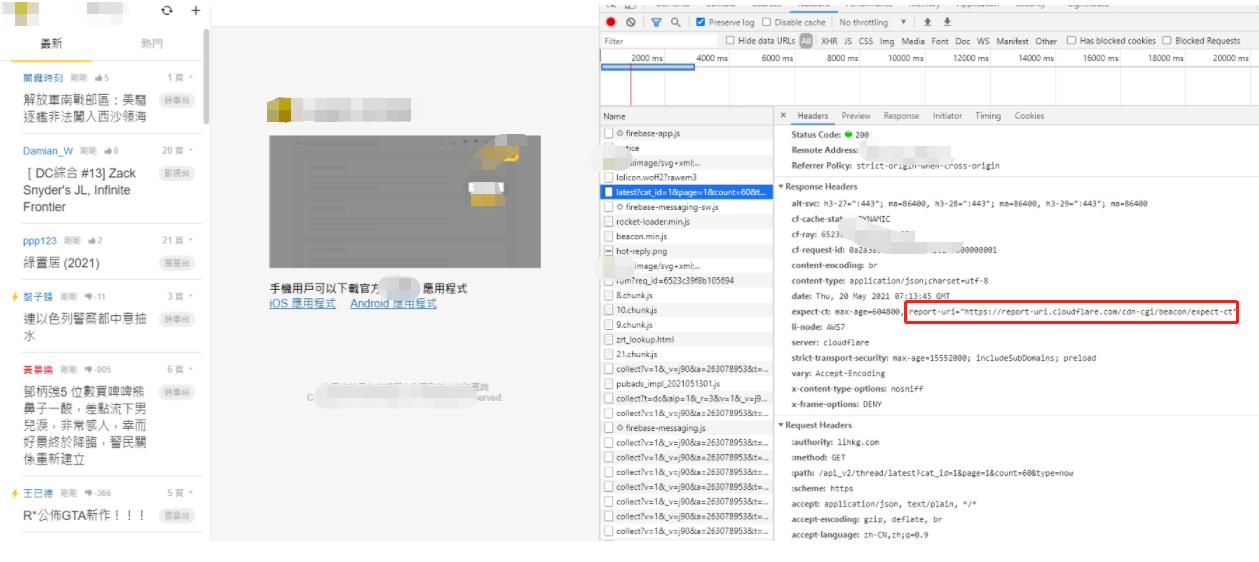
找到接口,查看返回数据
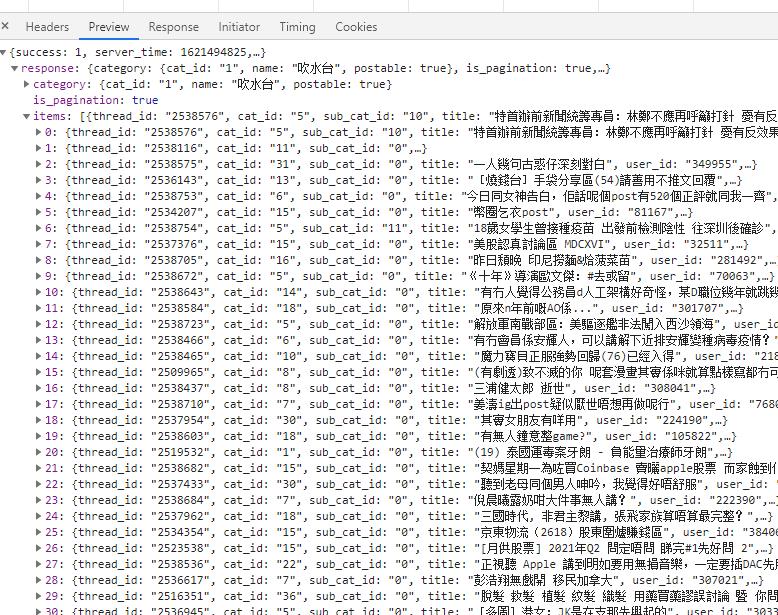
拿到数据接口单独请求会出现如下:
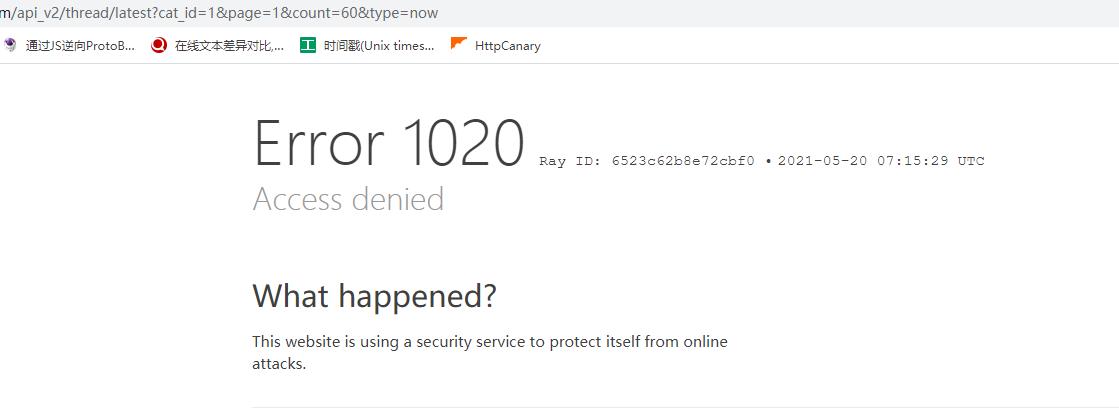
发现果然有cloundflare检测
用火狐浏览器打开
然后用重放请求功能看看,正常请求
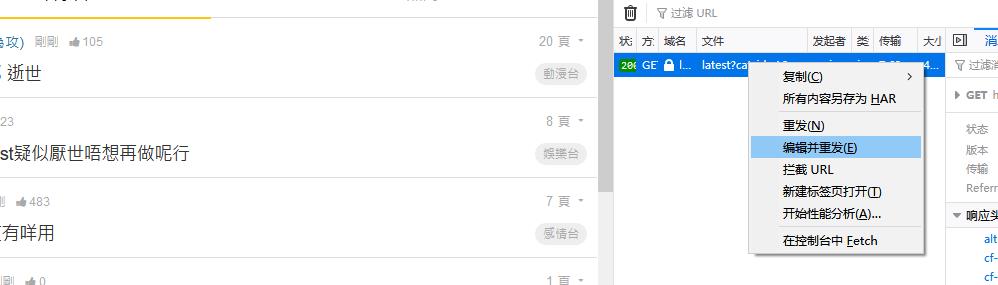
而且能正常拿数据

那我用postman测试:
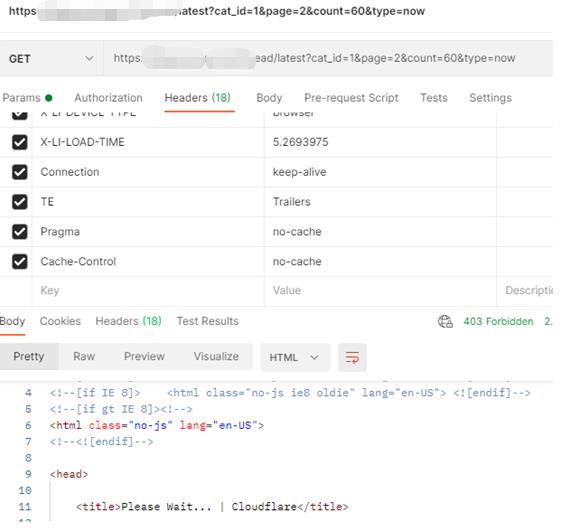
很奇怪的不行
用代码测试
也不行
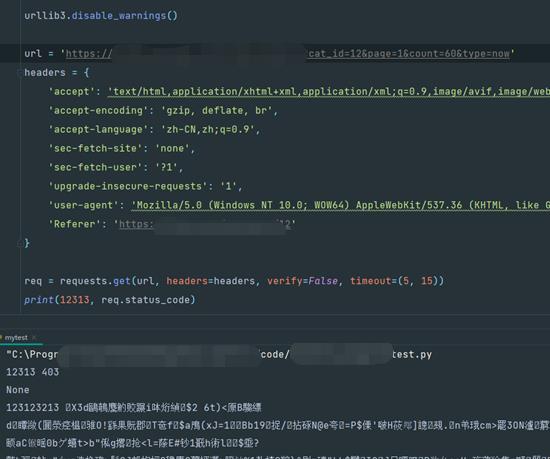
有朋友说,哎,你这不是有返回数据吗,仔细看哈,状态码时403,那说明返回的也多半不是真实数据,我知道有些确实用403状态来伪造,其实返回的也是真实数据,但是这种事极少数的情况,而前面我们已经用浏览器测试了,确实是200才会返回真实数据
你这不觉得很奇怪吗?浏览器正常请求,然后postman和代码就是不行,而它请求参数里又没有什么奇怪的参数,也是get请求,都是很简单的东西
找到关键点
这个咋整呢?
我们再回去一步一步看看,找到个关键的东西:

http2.0啥东西呢?
可以看看下面两个文字参考链接:
https://mp.weixin.qq.com/s/dFxyRYmqm5if8k-S1MjFJw
https://tding.top/archives/9bd92731.html
如果你觉得浪费时间的话,可以看我下面说的,精简过的:
1. 现在很多爬虫库其实对 HTTP/2.0 支持得不好,比如大名鼎鼎的 Python 库 —— requests,到现在为止还只支持 HTTP/1.1,啥时候支持 HTTP/2.0 还不知道。
2.Scrapy 框架最新版本 2.5.0(2021.04.06 发布)加入了对 HTTP/2.0 的支持,但是官网明确提示,现在是实验性的功能,不推荐用到生产环境
插一句,Scrapy 中怎么支持 HTTP/2.0 呢?在 settings.py 里面换一下 Download Handlers 即可:
DOWNLOAD_HANDLERS = {
\'https\': \'scrapy.core.downloader.handlers.http2.H2DownloadHandler\',
}当前 Scrapy 的 HTTP/2.0 实现的已知限制包括:
- 不支持 HTTP/2.0 明文(h2c),因为没有主流浏览器支持未加密的 HTTP/2.0。
- 没有用于指定最大帧大小大于默认值 16384 的设置,发送更大帧的服务器的连接将失败。
- 不支持服务器推送。
- 不支持
bytes_received和headers_received信号。关于其他的一些库,也不必多说了,对 HTTP/2.0 的支持也不好,目前对 HTTP/2.0 支持得还可以的有 hyper 和 httpx,后者更加简单易用一些
nginx也可以配置http2.0的:
if ($server_protocol !~* "HTTP/2.0") {
return 444;
}
3.目前在python中,支持http2.0的:
- Hyper
- Httpx
hyper的话,不是很适用,因为很多功能跟requests库没法类比,所以这里选用httpx
前提需要安装:
pip install httpx[http2] # 这样写才能装上支持http2的httpx,不写的话默认是不支持http2的
使用httpx:
配置好后使用,正常拿数据,记得要加http=True的属性
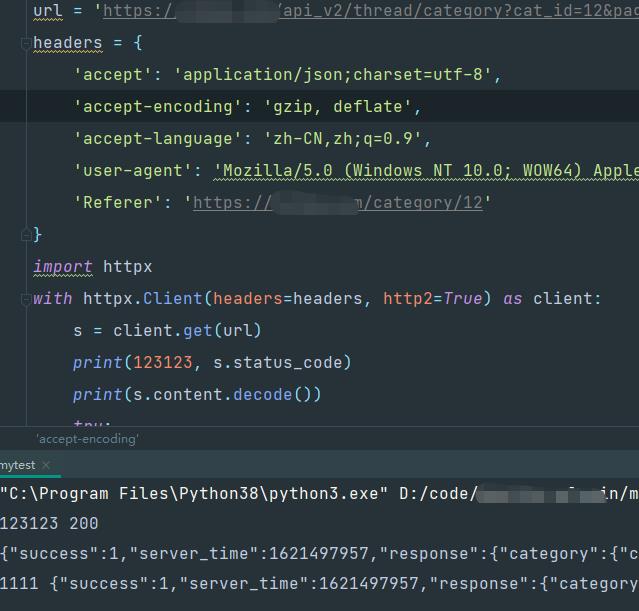
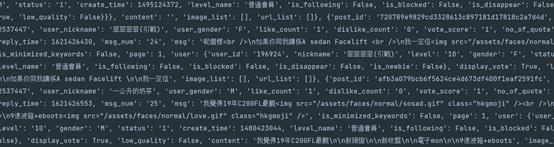
关于httpx使用socks协议代理问题:

https://pypi.org/project/httpx-socks/,
装完httpx-scoks库之后就支持socks协议的代理了,然后正常拿到数据
以上是关于python爬虫的主要内容,如果未能解决你的问题,请参考以下文章
Python练习册 第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-),(http://tieba.baidu.com/p/2166231880)(代码片段