u'囧'.encode('gb2312') throws UnicodeEncodeError
Posted Chuck Lu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了u'囧'.encode('gb2312') throws UnicodeEncodeError相关的知识,希望对你有一定的参考价值。
u\'囧\'.encode(\'gb2312\') throws UnicodeEncodeError
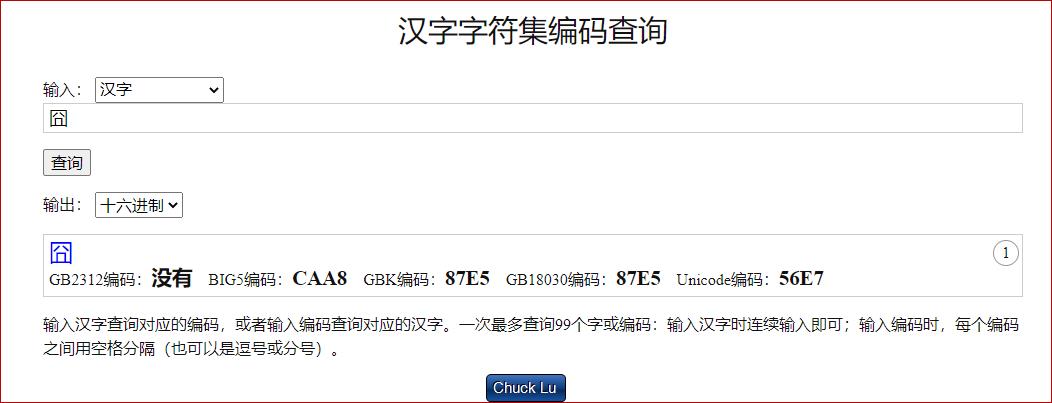
在这个页面进行查询,https://www.qqxiuzi.cn/bianma/zifuji.php
字符集编码是指对多个字符(通常在几十到几万个不等)进行整合封装成一个文件所使用的编码,外部程序通过这种编码就可以从字符集文件中调用指定的字符。我们常见的计算机字体文件就使用了字符集编码,通过输入法输入文字或者浏览网页时都会通过指定的字符集编码从字体文件中调用字符。
以下是常见的汉字字符集编码:
GB2312编码:1981年5月1日发布的简体中文汉字编码国家标准。GB2312对汉字采用双字节编码,收录7445个图形字符,其中包括6763个汉字。
BIG5编码:台湾地区繁体中文标准字符集,采用双字节编码,共收录13053个中文字,1984年实施。
GBK编码:1995年12月发布的汉字编码国家标准,是对GB2312编码的扩充,对汉字采用双字节编码。GBK字符集共收录21003个汉字,包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。
GB18030编码:2000年3月17日发布的汉字编码国家标准,是对GBK编码的扩充,覆盖中文、日文、朝鲜语和中国少数民族文字,其中收录27484个汉字。GB18030字符集采用单字节、双字节和四字节三种方式对字符编码。兼容GBK和GB2312字符集。
Unicode编码:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
https://www.qqxiuzi.cn/zh/hanzi-gb2312-bianma.php
汉字国标码查询
国标码是汉字的国家标准编码,目前主要有GB2312、GBK、GB18030三种。
- GB2312编码方案于1980年发布,收录汉字6763个,采用双字节编码。
- GBK编码方案于1995年发布,收录汉字21003个,采用双字节编码。
- GB18030编码方案于2000年发布第一版,收录汉字27533个;2005年发布第二版,收录汉字70000余个,以及多种少数民族文字。GB18030采用单字节、双字节、四字节分段编码。
新版向下兼容旧版,也就是说GBK是在GB2312已有码位基础上增加新码位,GB18030是在GBK已有码位基础上增加新码位,各种编码方案中共有的字符编码相同。现在的中文信息处理应优先采用GB18030编码方案。
在本页中,你可以输入汉字查询对应的国标码,也可以输入国标码查询对应的汉字。三种编码方案分别给出结果,以便于核对查询的字符是否收录在该编码方案中,例如:“〇”字GB2312未收录,“
以上是关于u'囧'.encode('gb2312') throws UnicodeEncodeError的主要内容,如果未能解决你的问题,请参考以下文章