正则表达式
Posted 离落想AC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式相关的知识,希望对你有一定的参考价值。
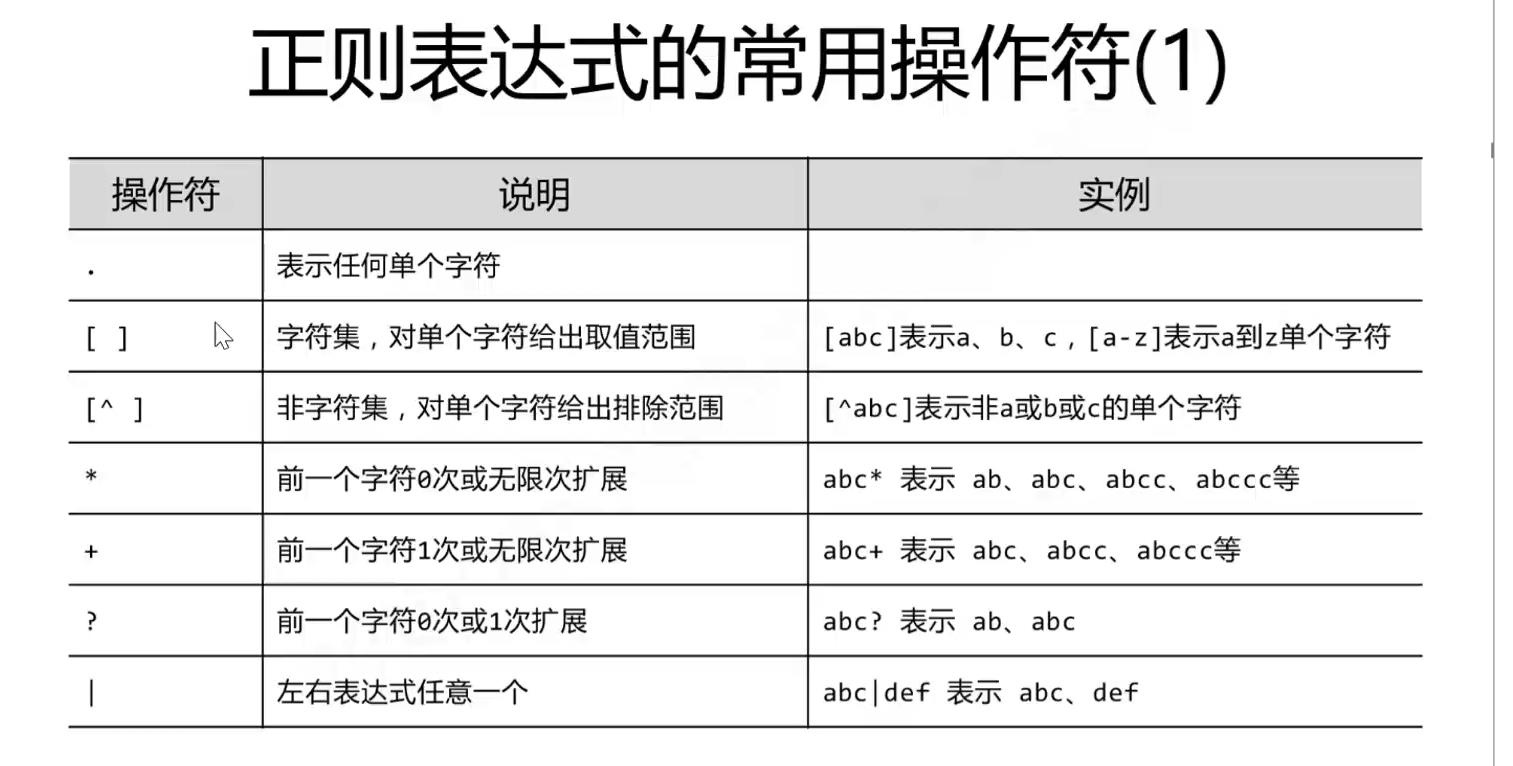
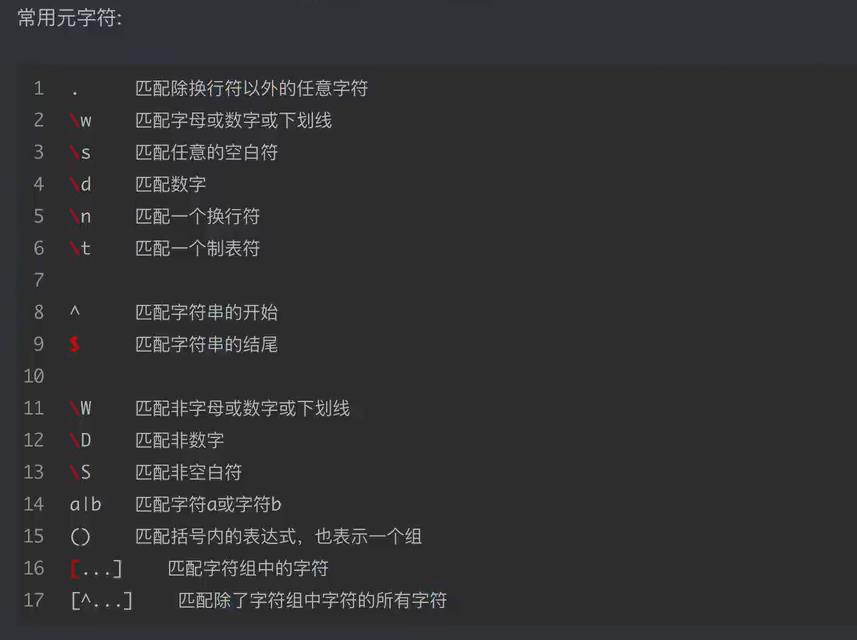
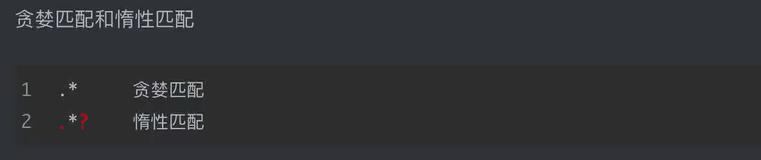
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。




# -*- coding: UTF-8 -*-
# @Time : 2021/5/25 21:13
# @Author : 李如旭
# @File :retext.py
# @Software: PyCharm
import re
# 正则表达式:字符串模式 (判断字符串是否符合一定的标准)
pat = re.compile("AA")
#此处的AA是正则表达式用来去验证其他字符。
m = pat.search("cbAA")
#findall用法:
print(m)
print("找出所有a:")
print(re.findall("a","ASDASDDSFFFAa"))
print("找出所有大写字母单个输出:")
print(re.findall("[A-Z]","asjBDJHdmalDD"))
print("找出所有大写字母连续输出:")
print(re.findall("[A-Z]+","ADsdFASsdsDA"))
#sub用法
print("把第三个式子里的a换成A:")
print(re.sub("a","A","abcdcasd"))
# -*- coding: UTF-8 -*-
# @Time : 2021/5/31 20:49
# @Author : 李如旭
# @File :reyufa.py
# @Software: PyCharm
import re
#基础:
# # findall : 匹配字符串中的所有的符合正则的内容
# lst = re.findall(r"\\d+","我的电话是10086,我女朋友的电话是10010")
# print(lst)
#
# # finditer : 匹配字符串中所有的内容[返回的是迭代器],从迭代器中拿到内容需要用.group()
# it = re.finditer(r"\\d+","我的电话是10086,我女朋友的电话是10010")
# for i in it :
# print(i.group())
#
# # search : 全文检索但是找到一个结果就返回,返回对象是match对象,拿数据要.group()
# s = re.search(r"\\d+","我的电话是10086,我女朋友的电话是10010")
# print(s.group())
#
# # match : 从头开始匹配 匹配不到就完蛋!!!
# s = re.match(r"\\d+","我的电话是10086,我女朋友的电话是10010")
# print("报错"+s.group())
#
# s1 = re.match(r"\\d+","10086,我女朋友的电话是10010")
# print("不报错:"+s1.group())
#进阶:
#预加载正则表达式
obj = re.compile(r"\\d+")
ret = obj.finditer("我的电话是10086,我女朋友的电话是10010")
for it in ret:
print(it.group())
ret = obj.findall("呵呵哒大马路了你打开234345的命令卡")
print(ret)
爬取豆瓣电影TOP250 名字,年份,评分,评价人数
# -*- coding: UTF-8 -*-
# @Time : 2021/5/31 21:10
# @Author : 李如旭
# @File :豆瓣排行榜.py
# @Software: PyCharm
import re
import requests
import csv
url ="https://movie.douban.com/top250"
head =
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.212 Safari/537.36"
rsp = requests.get(url=url,headers=head)
html = rsp.text
#print(html)
#爬取名字
# # #法一:
# name = re.finditer(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',html,re.DOTALL)
# for i in name:
# print(i.group("name"))
#
# # #法二:
# obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# result = obj.finditer(html)
# for it in result :
# print(it.group("name"))
#
# #法三:
#
# name = re.findall(r'<li>.*?<div class="item">.*?<span class="title">(.*?)</span>',html,re.S)
# print(name)
#爬取名字、年份、评分、
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>.*?'
r'<span>(?P<number>.*?)</span>', re.S)
result = obj.finditer(html)
for it in result:
print(it.group("name"))
print(it.group("year").strip())
print(it.group("score"))
print(it.group("number"))
以上是关于正则表达式的主要内容,如果未能解决你的问题,请参考以下文章