[源码解析] 并行分布式框架 Celery 之 Lamport 逻辑时钟 & Mingle
Posted 罗西的思考
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[源码解析] 并行分布式框架 Celery 之 Lamport 逻辑时钟 & Mingle相关的知识,希望对你有一定的参考价值。
[源码解析] 并行分布式框架 Celery 之 Lamport 逻辑时钟 & Mingle
0x00 摘要
Celery是一个简单、灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列,同时也支持任务调度。本文介绍 Celery 的Lamport 逻辑时钟 & Mingle。
本文为 Celery 最后一篇。接下来有几篇独立文章,然后会开一个新系列,敬请期待。
全部连接如下:
[源码解析] 并行分布式框架 Celery 之 worker 启动 (1)
[源码解析] 并行分布式框架 Celery 之 worker 启动 (2)
[源码解析] 分布式任务队列 Celery 之启动 Consumer
[源码解析] 并行分布式任务队列 Celery 之 Task是什么
[从源码学设计]celery 之 发送Task & AMQP
[源码解析] 并行分布式任务队列 Celery 之 消费动态流程
[源码解析] 并行分布式任务队列 Celery 之 多进程模型
[源码分析] 分布式任务队列 Celery 多线程模型 之 子进程
[源码分析]并行分布式任务队列 Celery 之 子进程处理消息
[源码分析] 并行分布式任务队列 Celery 之 Timer & Heartbeat
[源码解析] 并行分布式任务队列 Celery 之 EventDispatcher & Event 组件
[源码解析] 并行分布式任务队列 Celery 之 负载均衡
[源码解析] 并行分布式框架 Celery 之 Lamport 逻辑时钟 & Mingle
0x01 逻辑时钟
1.1 来由
分布式系统解决了传统单体架构的单点问题和性能容量问题,另一方面也带来了很多的问题,其中一个问题就是多节点的时间同步问题:不同机器上的物理时钟难以同步,导致无法区分在分布式系统中多个节点的事件时序。
1978年 Lamport 提出了逻辑时钟的概念,来解决分布式系统中区分事件发生的时序问题。
1.2 什么是逻辑时钟
逻辑时钟是为了区分现实中的物理时钟提出来的概念,一般情况下我们提到的时间都是指物理时间,但实际上很多应用中,只要所有机器有相同的时间就够了,这个时间不一定要跟实际时间相同。
更进一步,如果两个节点之间不进行交互,那么它们的时间甚至都不需要同步。因此问题的关键点在于节点间的交互要在事件的发生顺序上达成一致,而不是对于时间达成一致。
综上,逻辑时钟指的是分布式系统中用于区分事件的发生顺序的时间机制。
1.3 为什么需要逻辑时钟
时间是在现实生活中是很重要的概念,有了时间我们就能比较事情发生的先后顺序。如果是单个计算机内执行的事务,由于它们共享一个计时器,所以能够很容易通过时间戳来区分先后。同理在分布式系统中也通过时间戳的方式来区分先后行不行?
答案是NO,因为在分布式系统中的不同节点间保持它们的时钟一致是一件不容易的事情。因为每个节点的CPU都有自己的计时器,而不同计时器之间会产生时间偏移,最终导致不同节点上面的时间不一致。
那么是否可以通过某种方式来同步不同节点的物理时钟呢?答案是有的,NTP就是常用的时间同步算法,但是即使通过算法进行同步,总会有误差,这种误差在某些场景下(金融分布式事务)是不能接受的。
因此,Lamport提出逻辑时钟就是为了解决分布式系统中的时序问题,即如何定义a在b之前发生。
当且仅当事件A是由事件B引起的时候,事件A和B之间才存在一个先后关系。两个事件可以建立因果关系的前提是:两个事件之间可以用等于或小于光速的速度传递信息。 值得注意的是这里的因果关系指的是时序关系,即时间的前后,并不是逻辑上的原因和结果。
在分布式系统中,网络是不可靠的,所以我们去掉可以和速度的约束,得到两个事件可以建立因果(时序)关系的前提是:两个事件之间是否发生过信息传递。在分布式系统中,进程间通信的手段(共享内存、消息发送等)都属于信息传递。
1.4 Lamport 逻辑时钟
分布式系统中按是否存在节点交互可分为三类事件,一类发生于节点内部,二是发送事件,三是接收事件。
逻辑时钟定义
- Clock Condition:对于任意事件a, b:如果a -> b(->表示a先于b发生),那么C(a) < C(b),反之不然,因为有可能是并发事件。
- 如果a和b都是进程Pi里的事件,并且a在b之前,那么Ci(a) < Ci(b) 。
- 如果a是进程Pi里关于某消息的发送事件,b是另一进程Pj里关于该消息的接收事件,那么Ci(a) < Cj(b)
Lamport 逻辑时钟原理如下:
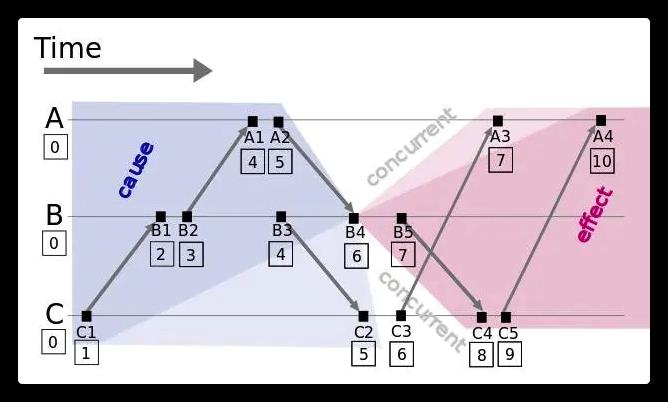
- 每个事件对应一个Lamport时间戳,初始值为0
- 如果事件在节点内发生,时间戳加1
- 如果事件属于发送事件,时间戳加1并在消息中带上该时间戳
- 如果事件属于接收事件,时间戳 = Max(本地时间戳,消息中的时间戳) + 1
假设有事件a、b,C(a)、C(b)分别表示事件a、b对应的Lamport时间戳,如果a发生在b之前(happened before),记作 a -> b,则有C(a) < C(b),例如图中有 C1 -> B1,那么 C(C1) < C(B1)。通过该定义,事件集中Lamport时间戳不等的事件可进行比较,我们获得事件的偏序关系(partial order)。注意:如果C(a) < C(b),并不能说明a -> b,也就是说C(a) < C(b)是a -> b的必要不充分条件
如果C(a) = C(b),那a、b事件的顺序又是怎样的?值得注意的是当C(a) = C(b)的时候,它们肯定不是因果关系,所以它们之间的先后其实并不会影响结果,我们这里只需要给出一种确定的方式来定义它们之间的先后就能得到全序关系。注意:Lamport逻辑时钟只保证因果关系(偏序)的正确性,不保证绝对时序的正确性。
0x02 Lamport 时钟 in Kombu
在 Kombu 中,就有 Lamport 时钟 的实现。
具体定义如下,我们可以知道:
- 当发送消息时候,使用 forward API 来增加时钟;
- 当收到消息时候,使用 adjust 来调整本地时钟;
class LamportClock:
"""Lamport\'s logical clock.
A Lamport logical clock is a monotonically incrementing software counter
maintained in each process. It follows some simple rules:
* A process increments its counter before each event in that process;
* When a process sends a message, it includes its counter value with
the message;
* On receiving a message, the receiver process sets its counter to be
greater than the maximum of its own value and the received value
before it considers the message received.
Conceptually, this logical clock can be thought of as a clock that only
has meaning in relation to messages moving between processes. When a
process receives a message, it resynchronizes its logical clock with
the sender.
*Usage*
When sending a message use :meth:`forward` to increment the clock,
when receiving a message use :meth:`adjust` to sync with
the time stamp of the incoming message.
"""
#: The clocks current value.
value = 0
def __init__(self, initial_value=0, Lock=Lock):
self.value = initial_value
self.mutex = Lock()
def adjust(self, other):
with self.mutex:
value = self.value = max(self.value, other) + 1
return value
def forward(self):
with self.mutex:
self.value += 1
return self.value
def sort_heap(self, h):
if h[0][0] == h[1][0]:
same = []
for PN in zip(h, islice(h, 1, None)):
if PN[0][0] != PN[1][0]:
break # Prev and Next\'s clocks differ
same.append(PN[0])
# return first item sorted by process id
return sorted(same, key=lambda event: event[1])[0]
# clock values unique, return first item
return h[0]
def __str__(self):
return str(self.value)
def __repr__(self):
return f\'<LamportClock: {self.value}>\'
0x03 使用 clock
3.1 Kombu mailbox
比如在 Kombu mailbox 之中,发送时候就需要携带本地的clock。
producer.publish(
reply, exchange=exchange, routing_key=routing_key,
declare=[exchange], headers={
\'ticket\': ticket, \'clock\': self.clock.forward(),
}, retry=True,
**opts
)
在收到消息时,就相应调整本地时钟
def _collect(self, ticket,
limit=None, timeout=1, callback=None,
channel=None, accept=None):
adjust_clock = self.clock.adjust
def on_message(body, message):
header = message.headers.get
adjust_clock(header(\'clock\') or 0)
3.2 Celery 应用
Celery 应用本身就有一个 LamportClock 变量。
class Celery:
self.clock = LamportClock()
3.3 EventDispatcher
在 EventDispatcher 发送 Event 时候,就会使用 LamportClock 的时钟。
def publish(self, type, fields, producer,
blind=False, Event=Event, **kwargs):
clock = None if blind else self.clock.forward()
event = Event(type, hostname=self.hostname, utcoffset=utcoffset(),
pid=self.pid, clock=clock, **fields)
with self.mutex:
return self._publish(event, producer,
routing_key=type.replace(\'-\', \'.\'), **kwargs)
0x04 Mingle
在 Celery 的介绍中,Mingle 主要用在启动或者重启的时候,它会和其他的 worker 交互,从而进行同步。同步的数据有:
- 其他 worker 的 clock
- 其他 worker 已经处理掉的 tasks
同步 clock 比较好理解,但是为什么要同步 其他worker已经处理完的 task 呢?因为这个场景是启动或者重启。
如果我们在 Celery 之中设置一个节点为task_acks_late=True之后,那么这个节点上正在执行的任务若是遇到断电,运行中被结束等情况,这些任务会被重新分发到其他节点进行重试。
所以当某个节点重启期间,可能本来由本 worker 负责的 task 会已经被其他 worker 处理掉,为了避免重复处理,就需要同步一下。
4.1 定义
Mingle 定义如下:
class Mingle(bootsteps.StartStopStep):
"""Bootstep syncing state with neighbor workers.
At startup, or upon consumer restart, this will:
- Sync logical clocks.
- Sync revoked tasks.
"""
label = \'Mingle\'
requires = (Events,)
compatible_transports = {\'amqp\', \'redis\'}
def start(self, c):
self.sync(c)
4.2 Sync 过程
启动即同步,代码逻辑如下:
- Mingle 向 每一个 Worker 发送 hello
- 每个 Worker 都向 Mingle 回复自己的信息(clock 和 tasks)
- Mingle 更新自己的信息
这需要注意的是:没有回调函数,直接 send_hello 就返回了其他 worker 的结果,这是用异步来模拟的一个同步过程。
而 在 send_hello返回时候,因为这时候收到了所有 worker 的回复,也包括自己,所以需要把自己host对应的回复删除。
对应代码如下:
def sync(self, c):
replies = self.send_hello(c)
if replies:
[self.on_node_reply(c, nodename, reply)
for nodename, reply in replies.items() if reply]
else:
info(\'mingle: all aone\')
4.2.1 发起同步
首先,Mingle 会向 每一个 Worker 发送 hello。
def send_hello(self, c):
inspect = c.app.control.inspect(timeout=1.0, connection=c.connection)
our_revoked = c.controller.state.revoked
replies = inspect.hello(c.hostname, our_revoked._data) or {}
replies.pop(c.hostname, None) # delete my own response
return replies
此时相关变量如下:
c.controller.state = {module} <module \'celery.worker.state\' >
c.controller.state.revoked = {LimitedSet: 0} <LimitedSet(0): maxlen=50000, expires=10800, minlen=0>
c.controller = {Worker} celery@DESKTOP-0GO3RPO
c = {Consumer}
4.2.1.1 revoked task
我们可以看到,Mingle 会从 c.controller.state.revoked之中获取 内容,即 当前 worker 记录的已被完成的 tasks。然后发送给其他 worker。
4.2.1.2 inspect.hello
这里是使用了 celery.app.control.Control 的 inspect 功能进行广播发送。
def _request(self, command, **kwargs):
return self._prepare(self.app.control.broadcast(
command,
arguments=kwargs,
destination=self.destination,
callback=self.callback,
connection=self.connection,
limit=self.limit,
timeout=self.timeout, reply=True,
pattern=self.pattern, matcher=self.matcher,
))
4.2.2 其他worker 回复
celery.app.control.Control 之中,会使用 _prepare 来处理其他 worker 的返回。
def _prepare(self, reply):
if reply:
by_node = flatten_reply(reply)
if (self.destination and
not isinstance(self.destination, (list, tuple))):
return by_node.get(self.destination)
if self.pattern:
pattern = self.pattern
matcher = self.matcher
return {node: reply for node, reply in by_node.items()
if match(node, pattern, matcher)}
return by_node
4.2.3 收到后同步
在收到其他worker回复之后会进行同步,我们可以看到其同步了时钟 和 tasks。
具体 task 的更新,是由 state 完成的。
def sync_with_node(self, c, clock=None, revoked=None, **kwargs):
self.on_clock_event(c, clock)
self.on_revoked_received(c, revoked)
def on_clock_event(self, c, clock):
c.app.clock.adjust(clock) if clock else c.app.clock.forward()
def on_revoked_received(self, c, revoked):
if revoked:
c.controller.state.revoked.update(revoked)
4.2.4 如何使用 revoked
当发布任务时候,如果发现该任务已经被设置为 revoked,则不会发布该任务。
def default(task, app, consumer,
info=logger.info, error=logger.error, task_reserved=task_reserved,
to_system_tz=timezone.to_system, bytes=bytes,
proto1_to_proto2=proto1_to_proto2):
"""Default task execution strategy.
Note:
Strategies are here as an optimization, so sadly
it\'s not very easy to override.
"""
.....
revoked_tasks = consumer.controller.state.revoked
def task_message_handler(message, body, ack, reject, callbacks,
to_timestamp=to_timestamp):
......
if (req.expires or req.id in revoked_tasks) and req.revoked():
return
......
if callbacks:
[callback(req) for callback in callbacks]
handle(req)
return task_message_handler
0xEE 个人信息
★★★★★★关于生活和技术的思考★★★★★★
微信公众账号:罗西的思考
如果您想及时得到个人撰写文章的消息推送,或者想看看个人推荐的技术资料,敬请关注。

0xFF 参考
以上是关于[源码解析] 并行分布式框架 Celery 之 Lamport 逻辑时钟 & Mingle的主要内容,如果未能解决你的问题,请参考以下文章