Redis实现分布式锁
Posted 君子生非异也
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis实现分布式锁相关的知识,希望对你有一定的参考价值。
一、分布式锁要实现的问题
互斥:在分布式高并发的条件下,我们最需要保证,同一时刻只能有一个线程获得锁,这是最基本的一点。
防止死锁:在分布式高并发的条件下,比如有个线程获得锁的同时,还没有来得及去释放锁,就因为系统故障或者其它原因使它无法执行释放锁的命令,导致其它线程都无法获得锁,造成死锁。所以分布式非常有必要设置锁的有效时间,确保系统出现故障后,在一定时间内能够主动去释放锁,避免造成死锁的情况。
性能:对于访问量大的共享资源,需要考虑减少锁等待的时间,避免导致大量线程阻塞。
- 1、
锁的颗粒度要尽量小。比如你要通过锁来减库存,那这个锁的名称你可以设置成是商品的ID,而不是任取名称。这样这个锁只对当前商品有效,锁的颗粒度小。 - 2、
锁的范围尽量要小。比如只要锁2行代码就可以解决问题的,那就不要去锁10行代码了。
重入:同一个线程可以重复拿到同一个资源的锁。重入锁非常有利于资源的高效利用。
二、Redisson原理
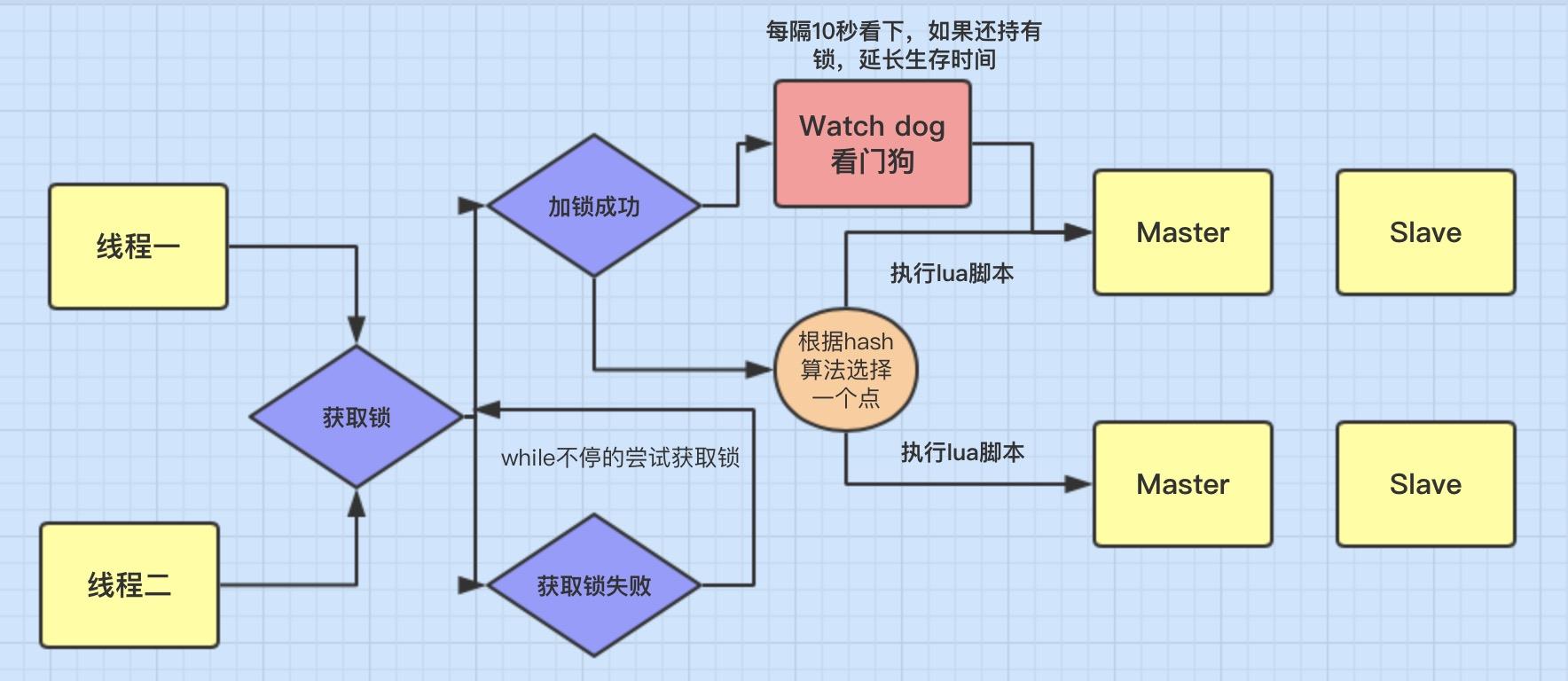
Redisson使用lua脚本语言将多条redis 指令封装成一个脚本语句提交给redis服务器,从而保保证其原子性。
看门狗的意义:为了避免程序突然宕机而锁无法释放问题,我们一般会给锁加一个过期时间。但是如果我们的业务执行时间大于锁的过期时间,怎么处理呢,看门狗的作用就是对执行中的业务锁进行续签。
Redisson如何实现重入:hset 命令插入一个 hset myLock 8743c9c0-0795-4907-87fd-6c71a6b4586:1 1;重入 incrby myLock 8743c9c0-0795-4907-87fd-6c71a6b4586:1 1
- myLock: 是redis的key
- 8743c9c0-0795-4907-87fd-6c71a6b4586:是客户端生成的一个唯一ID
- 1:是线程ID
- 最后一个1:当前线程的获取锁的次数,就是每次重入加1 ;
锁互斥机制
- 客户端2来尝试加锁,执行了同样的一段lua脚本,
- 第一个if判断会执行“exists myLock”,发现myLock这个锁key已经存在了。
- 接着第二个if判断,判断一下,myLock锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
- 所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的剩余生存时间。比如还剩15000毫秒的生存时间。
- 此时客户端2会进入一个while循环,不停的尝试加锁。
三、redis AP问题
我们使用redis‘实现分布式锁,要保证锁的高可用,就必须保证redis的高可用,如果我们使用redis的哨兵+主从模式,由于数据同步的延迟问题,必然会存在某个时刻数据不一致的问题。显然这中分布式锁是不严谨的。

如图所示:线程1对master加锁,突然master宕机,slave被选为主节点,但是slave并没有完全同步master的数据。此时线程2来竞争锁,显然这种场景下一定可以获得锁。但这不是我们期望的结果。
解决方案一:过半成功

如图:我们搭建N台redis服务器,他们之间是彼此独立的,只有加锁成功超过半数我们才认为加锁成功。显然线程2在加锁第三台服务器时是无法成功的。如此可以满足我们的需求。
缺点:浪费资源;效率较低;由于延迟的存在他们的过期时间会不一致
解决方案二:使用zookeeper 实现分布式锁
以上是关于Redis实现分布式锁的主要内容,如果未能解决你的问题,请参考以下文章