爬虫:读取数据库数据并处理数据
Posted tree1000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫:读取数据库数据并处理数据相关的知识,希望对你有一定的参考价值。
测试代码要利用到上一篇文章爬取到的数据,上一章链接:爬虫:多进程爬虫 ,
本文要分析上一篇文章爬取到的数据库中的数据,结果分别是与男性/女性话题相关联的话题。
1. 遍历mongodb数据语法
1.1 测试代码
from pymongo import MongoClient client = MongoClient(\'localhost\') db = client[\'zhihu_mirror_links\'] collection = db[\'女性keyword\'] results = collection.find({\'key_words\': {\'$regex\': \'.*\'}}) print(results) for i in results[:10]: print(i[\'key_words\'])
1.2 测试结果

2. 数据分析
下面的截图结果是运行两次代码的结果,每次运行要修改一下所要处理数据库的collection,其余不需要改动
2.1 测试代码
import matplotlib.pyplot as plt from pylab import mpl from collections import Counter from pymongo import MongoClient import time import os client = MongoClient(\'localhost\') db = client[\'zhihu_mirror_links\'] collection = db[\'男性keyword\'] mpl.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 指定默认字体 mpl.rcParams[\'font.size\'] = 8 # 设置标签字体大小 mpl.rcParams[\'axes.unicode_minus\'] = False # 解决保存图像是负号\'-\'显示为方块的问题 def data_view(): # 首先读取数据库数据,并进行关键字计数:Counter对象 topic = input(\'输入要分析的话题:\') # 保存文件名用到 keywords = [] db_results = collection.find({\'key_words\': {\'$regex\': \'.*\'}}) # 读取数mongodb据库数据 for result in db_results: # 将数据添加到keywords列表 for word in result[\'key_words\'].split(\',\'): keywords.append(word) print(Counter(keywords).most_common()) print(Counter(keywords).most_common()[:30]) # 列表计数测试 keywords_count = Counter(keywords).most_common()[1:31] # 取数量排名前21,去除第一个 # 遍历文件夹,保证文件夹中没有要保存图片名的图片 index = 1 while topic + str(index) + \'.png\' in os.listdir(r\'镜像话题数据分析\'): index += 1 # 提取要绘图的纵横坐标数据:x,y x = [] y = [] for data in keywords_count: # 迭代计数列表 x.append(data[0]) y.append(data[1]) x.reverse() # matplotlib画横向柱状图是从下往上画,反转一下数据 y.reverse() # 画横向柱状图 fig, ax = plt.subplots() png = ax.barh(range(len(x)), y, color=\'#ff20ff\') # 添加数据标签 for rectangle in png: width = rectangle.get_width() ax.text(width, rectangle.get_y() + rectangle.get_height() / 2, \'%d\' % int(width), ha=\'left\', va=\'center\') # 设置Y轴刻度线标签 ax.set_yticks(range(len(x))) ax.set_yticklabels(x) plt.xlabel(\'value\') plt.ylabel(\'keyword\') plt.title(topic + \'话题\' + \'\\n\' + time.ctime() + \'\\n\' + str(Counter(keywords).most_common()[0])) # 排名第一的将在图表标题显示 plt.savefig(r\'镜像话题数据分析\' + \'/\' + topic + str(index) + \'.png\', dpi=600, bbox_inches=\'tight\') # 清晰度 plt.show() # 要放在savefig后面 if __name__ == \'__main__\': data_view()
2.2 结果截图


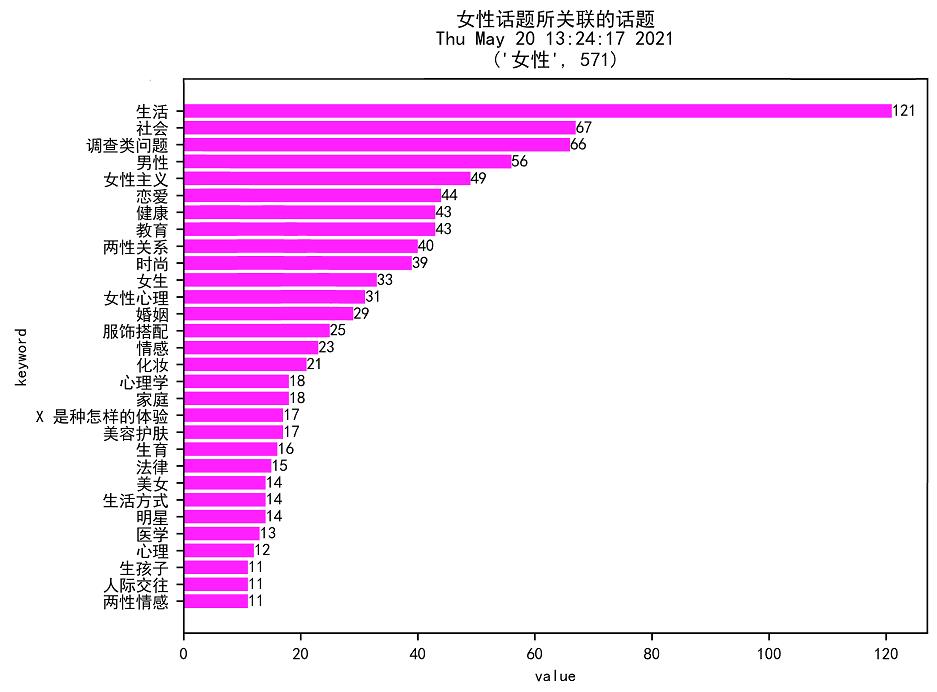
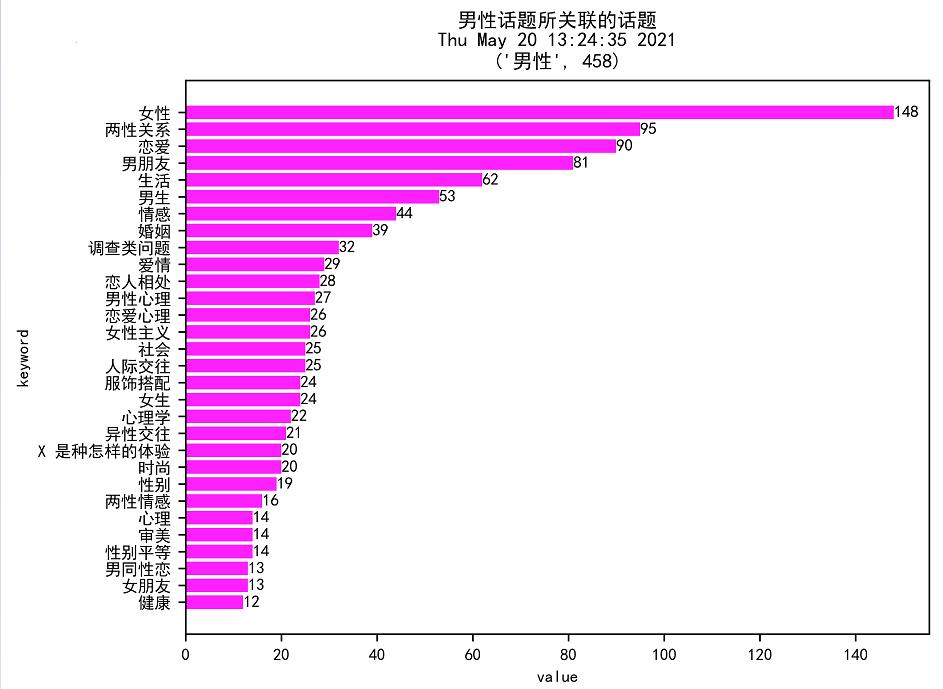
3. 结论
对于生活话题,男性不及女性。
对于化妆、美容、生育话题,男性不及女性。
对于情感、心理、婚姻、家庭、性等话题,男性和女性都同样关注。
以上是关于爬虫:读取数据库数据并处理数据的主要内容,如果未能解决你的问题,请参考以下文章