用pytorch实现Autoencoder
Posted hi_mxd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用pytorch实现Autoencoder相关的知识,希望对你有一定的参考价值。
原文连接: https://debuggercafe.com/implementing-deep-autoencoder-in-pytorch/
本文将简述pytorch环境下的线性自编码器的实现:
本文内容:
- autoencoder简介;
- 方法;
- Pytorch实现(线性层)
- 图片重构
一、autoencoder简介
深度学习自编码器是一种神经网络类型,可以从潜在code空间中重构图片;
这里涉及到三个概念:
1)encoder 2)decoder 3) code
下面以图像为例进行说明:
encoder:是个网络结构;输入图像,输出code;
decoder:也是个网络结构;输入code,输出图像;
code:可以理解为图像潜在特征表示
下面用一张图来对其进行表示:
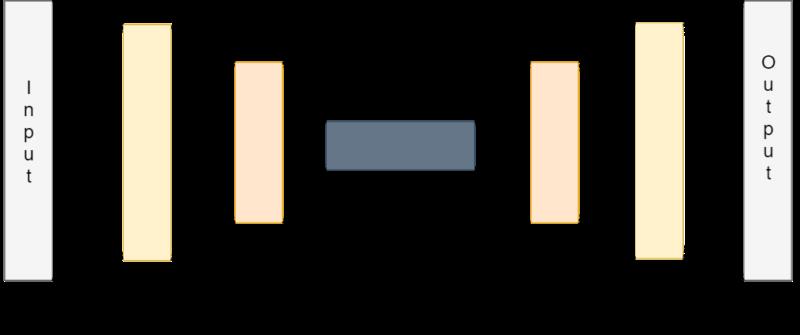
二、方法
Deep autoencoder
三、Pytorch实现
数据集: Fashion MNIST
有70000张灰度图,其中60000作为训练,10000作为测试集;
包含有10个类别;
代码实现:
1)导入需要的包
# import packages import os import torch import torchvision import torch.nn as nn import torchvision.transforms as transforms import torch.optim as optim import matplotlib.pyplot as plt import torch.nn.functional as F from torchvision import datasets from torch.utils.data import DataLoader from torchvision.utils import save_image
重要包说明:
- torchvision: 包含许多流行的计算机视觉数据集,深度神经网络架构,以及图像处理模块;我们将使用这个包来下载Fashion MNIST和CIFAR10数据集;
- torch.nn:包含了许多深度学习网络层,比如Linear()、Conv2d()等;
- transforms:帮助定义图像变换和正则化;
- optim:包含了深度学习的优化器;
- functional:在本文中的激活函数将用到它;
- Dataloader:使数据成为可迭代的训练和测试形式;
2)数据准备以及超参数定义
超参数是指,人工预先设定的,不通过网络学习得到的参数;
主要有, 迭代的次数NUM_EPOCHS,学习率LEARNING_RATE,batch的大小BATCH_SIZE
代码如下:
# constants NUM_EPOCHS = 50 LEARNING_RATE = 1e-3 BATCH_SIZE = 128 # image transformations transform = transforms.Compose([ transforms.ToTensor(), ])
transforms.Compose([transforms.ToTensor(),])是将pixel的值转换为tensor;并且将其缩放至[-1,1]范围;
训练集和测试的准备:
trainset = datasets.FashionMNIST( root=\'./data\', train=True, download=True, transform=transform ) testset = datasets.FashionMNIST( root=\'./data\', train=False, download=True, transform=transform ) trainloader = DataLoader( trainset, batch_size=BATCH_SIZE, shuffle=True ) testloader = DataLoader( testset, batch_size=BATCH_SIZE, shuffle=True )
这里的trainloader以及testloader中的batchsize大小均为128; data loaders是可迭代的;
trainloader中含有60000/128个batches,testloader中含有10000/128个batches。
3) 实用函数 utility functions
写这些函数的目的在于:节省时间,避免代码重复;
本文包含三个实用函数:
a. get_device() 设备判断函数——返回GPU或者是CPU
b.make_dir()创建一个目录来存储训练中重构的图片;
c. save_decode_image() 用于存储自编码器重构的图片。
# utility functions def get_device(): if torch.cuda.is_available(): device = \'cuda:0\' else: device = \'cpu\' return device def make_dir(): image_dir = \'FashionMNIST_Images\' if not os.path.exists(image_dir): os.makedirs(image_dir) def save_decoded_image(img, epoch): img = img.view(img.size(0), 1, 28, 28) save_image(img, \'./FashionMNIST_Images/linear_ae_image{}.png\'.format(epoch))
4)定义自编码-解码网络
Autoencoder()具有两个部分:编码encoder部分以及解码decoder部分;
encoder部分:
a. encoder将28*28维的图像进行展平处理,成为28*28=784维的向量;
b. 定义了5个Linear()层,直到最后一个输出特征是16;
encoder部分生成了潜在code表示;之后进行decoder用于重构;
decoder:
a. 将code中的16个维度通过线性层逐层递增;
b. 最后得到输出的784维的特征;
在forward()函数中,对每层的后面都接了ReLU激活函数,最后将网络结构进行返回;
net = Autoencoder() 创建了一个Autoencoder()实例,当我们需要使用神经网络的时候就可以调用它;
实际上,对于Fashion MNIST来说,我们甚至不需要这么大的网络;即使是两层网络也可以很好的捕捉到图像的重要特征;
class Autoencoder(nn.Module): def __init__(self): super(Autoencoder, self).__init__() # encoder self.enc1 = nn.Linear(in_features=784, out_features=256) self.enc2 = nn.Linear(in_features=256, out_features=128) self.enc3 = nn.Linear(in_features=128, out_features=64) self.enc4 = nn.Linear(in_features=64, out_features=32) self.enc5 = nn.Linear(in_features=32, out_features=16) # decoder self.dec1 = nn.Linear(in_features=16, out_features=32) self.dec2 = nn.Linear(in_features=32, out_features=64) self.dec3 = nn.Linear(in_features=64, out_features=128) self.dec4 = nn.Linear(in_features=128, out_features=256) self.dec5 = nn.Linear(in_features=256, out_features=784) def forward(self, x): x = F.relu(self.enc1(x)) x = F.relu(self.enc2(x)) x = F.relu(self.enc3(x)) x = F.relu(self.enc4(x)) x = F.relu(self.enc5(x)) x = F.relu(self.dec1(x)) x = F.relu(self.dec2(x)) x = F.relu(self.dec3(x)) x = F.relu(self.dec4(x)) x = F.relu(self.dec5(x)) return x net = Autoencoder() print(net)
输出:
Autoencoder( (enc1): Linear(in_features=784, out_features=256, bias=True) (enc2): Linear(in_features=256, out_features=128, bias=True) (enc3): Linear(in_features=128, out_features=64, bias=True) (enc4): Linear(in_features=64, out_features=32, bias=True) (enc5): Linear(in_features=32, out_features=16, bias=True) (dec1): Linear(in_features=16, out_features=32, bias=True) (dec2): Linear(in_features=32, out_features=64, bias=True) (dec3): Linear(in_features=64, out_features=128, bias=True) (dec4): Linear(in_features=128, out_features=256, bias=True) (dec5): Linear(in_features=256, out_features=784, bias=True) )
5)定义网络的损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=LEARNING_RATE)
6) 定义使用的train和test函数
train()函数
有一些需要注意的地方:
第6行,只提取了数据,而没有提取Label;
第8行,将28*28的图像展成784维的形式;
在每次迭代的时候,我们都将loss值存储到train_loss中,在函数最后进行返回;
每5次迭代后,我们将存储重构的图像;可以直观可视化神经网络的变现性能;
test()函数:test_image_reconstruction()
将重构一个batch的图像;
1 def train(net, trainloader, NUM_EPOCHS): 2 train_loss = [] 3 for epoch in range(NUM_EPOCHS): 4 running_loss = 0.0 5 for data in trainloader: 6 img, _ = data 7 img = img.to(device) 8 img = img.view(img.size(0), -1) 9 optimizer.zero_grad() 10 outputs = net(img) 11 loss = criterion(outputs, img) 12 loss.backward() 13 optimizer.step() 14 running_loss += loss.item() 15 16 loss = running_loss / len(trainloader) 17 train_loss.append(loss) 18 print(\'Epoch {} of {}, Train Loss: {:.3f}\'.format( 19 epoch+1, NUM_EPOCHS, loss)) 20 if epoch % 5 == 0: 21 save_decoded_image(outputs.cpu().data, epoch) 22 return train_loss 23 def test_image_reconstruction(net, testloader): 24 for batch in testloader: 25 img, _ = batch 26 img = img.to(device) 27 img = img.view(img.size(0), -1) 28 outputs = net(img) 29 outputs = outputs.view(outputs.size(0), 1, 28, 28).cpu().data 30 save_image(outputs, \'fashionmnist_reconstruction.png\') 31 break
7)训练自编码网络
接下来,接可以调用之前定义的utility函数,训练和检验我们的网络;
代码说明:
line 2 得到计算设备 cuda: cpu/gpu
line 5 加载网络到设备上;
line 6 为重构的图像建立目录文件;
line 10 绘制训练损失;
line 19 对图像进行重构来检验单个batch中的影像;
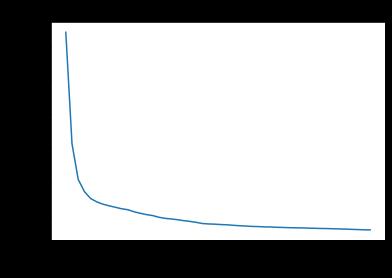
1 # get the computation device 2 device = get_device() 3 print(device) 4 # load the neural network onto the device 5 net.to(device) 6 make_dir() 7 # train the network 8 train_loss = train(net, trainloader, NUM_EPOCHS) 9 plt.figure() 10 plt.plot(train_loss) 11 plt.title(\'Train Loss\') 12 plt.xlabel(\'Epochs\') 13 plt.ylabel(\'Loss\') 14 plt.savefig(\'deep_ae_fashionmnist_loss.png\') 15 # test the network 16 test_image_reconstruction(net, testloader)
8) 分析损失图和图像重构结果
四、重构图像:
可以看出随着迭代次数的增加,图像的质量得到了显著提升;

总结与结论:
本文是关于Pytorch实现一个简单的深度自编码器的研究。
在深度学习中,如果你能够很清晰的理解一个简单的概念,那么相关的概念也会较为容易理解的。
我在此希望你已经学到了如何使用Pytorch实现深度自编码器。
接下来,我们将实现卷积自编码器。
以上是关于用pytorch实现Autoencoder的主要内容,如果未能解决你的问题,请参考以下文章