fofa采集脚本
Posted fengge233
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了fofa采集脚本相关的知识,希望对你有一定的参考价值。
FOFA-网络空间安全搜索引擎是网络空间资产检索系统(FOFA)是世界上数据覆盖更完整的IT设备搜索引擎,拥有全球联网IT设备更全的DNA信息。探索全球互联网的资产信息,进行资产及漏洞影响范围分析、应用分布统计、应用流行度态势感知等。
首先安装库
pip install requests
pip install lxml
脚本代码 是可以用命令行调用的 只不过我比较懒
import base64 import requests from lxml import etree import timedef fofa_search(search_data,page): pages = page + 1 search_data_b=base64.b64encode(search_data.encode(\'utf-8\')) #转换为base64加密 search_data_bs=search_data_b.decode(\'utf-8\') headers={ \'user-agent\':\'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)\', "cookie":\'_fofapro_ars_session=\' # cookie } for yeshu in range(1,pages): url="https://classic.fofa.so/result?page="+str(yeshu)+"&qbase64=" urls=url+search_data_bs #拼接参数 加上base64的值 ImdsYXNzZmlzaCIgJiYgcG9ydD0iNDg0OCI= print("正在提取" + str(yeshu) + "页") try: result=requests.get(urls,headers=headers,timeout=0.8).content #请求 soup =etree.HTML(result) ip_data=soup.xpath(\'//div[@class="list_mod_t"]/a[@target="_blank"]/@href\') #找到节点的值 print(ip_data) ipdata=\'\\n\'.join(ip_data) with open(r\'ip.txt\',\'a+\') as f: #写文件 f.write(ipdata+\'\\n\') f.close() time.sleep(0.8) except Exception as e: pass if __name__ == \'__main__\': fofa_search(\'country="TW" && title="公司" && port="80" && app="Microsoft-ASP.NET"\',5)
拿自己cookie复制过去
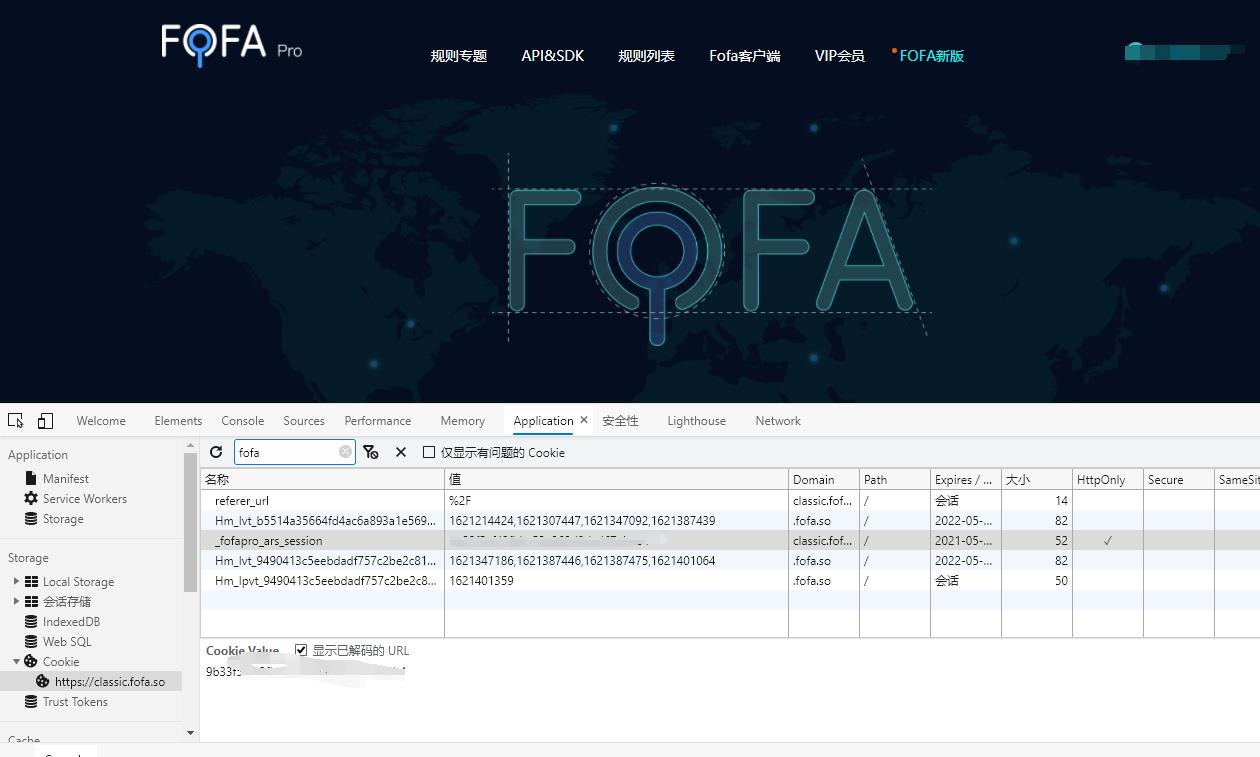
复制到这里看好
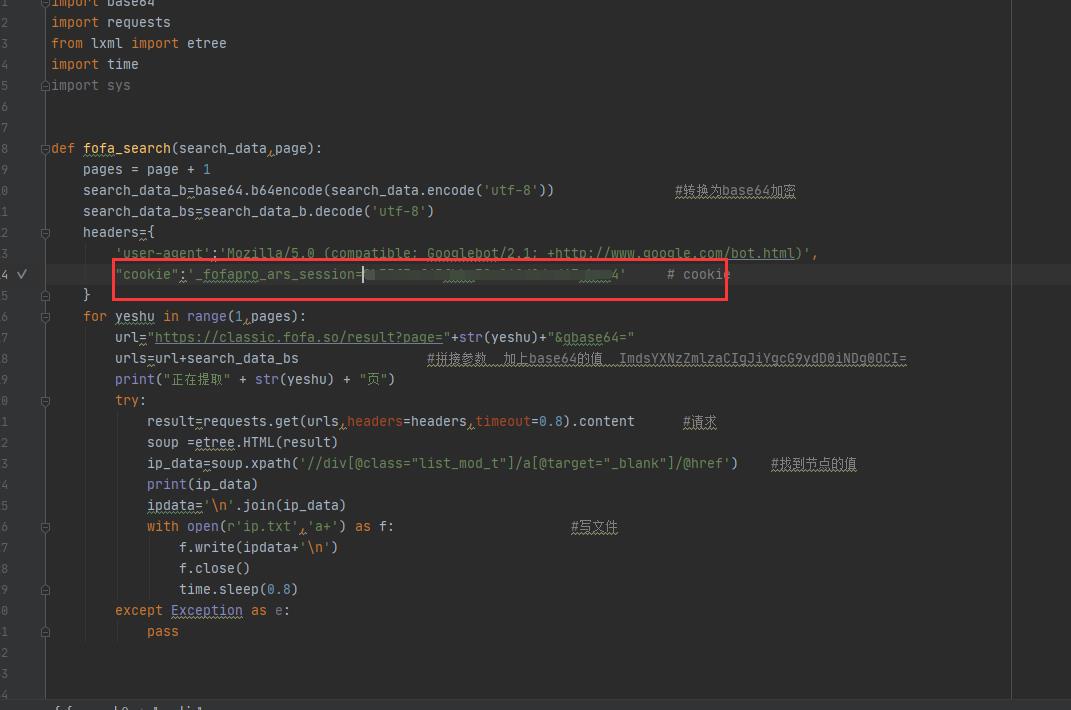
然后就能用了

以上是关于fofa采集脚本的主要内容,如果未能解决你的问题,请参考以下文章