云计算环境Hadoop安装与配置
Posted liweikuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云计算环境Hadoop安装与配置相关的知识,希望对你有一定的参考价值。
一.Ubuntu怎么开启/关闭防火墙
在Ubuntu中,使用sudo ufw status命令查看当前防火墙状态。
不活动,是关闭状态。
在Ubuntu中,使用sudo ufw enable命令来开启防火墙。
在Ubuntu中,使用sudo ufw disable命令来关闭防火墙。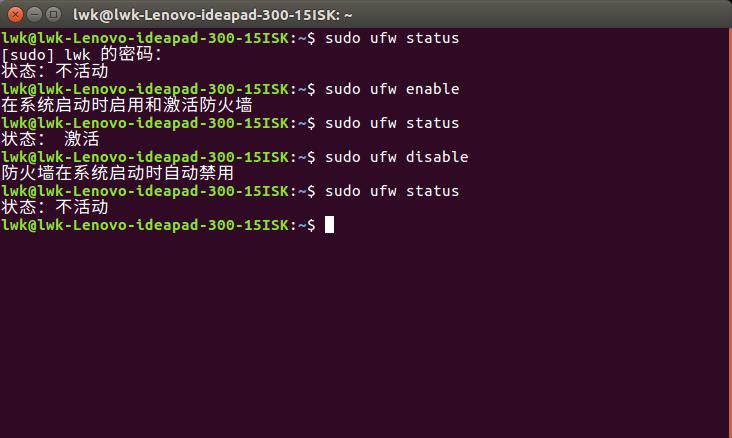
二.创建hadoop用户
如果你安装Ubuntu的时候不是使用的"hadoop"用户, 那么需要增加一个名为hadoop的用户.
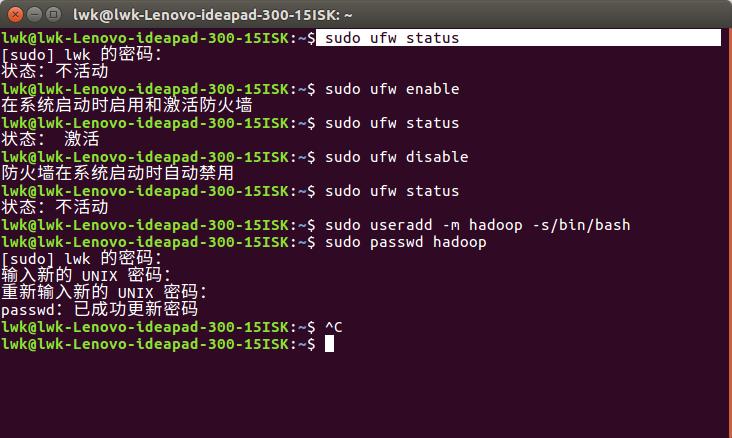
1)首先按ctrl+alt+t打开终端窗口,输入如下命令创建新用户:
sudo useradd -m hadoop -s/bin/bash
2)接着可以使用如下命令设置密码,可以简单的设置为hadoop, 按提示输入两次密码:
sudo passwd hadoop
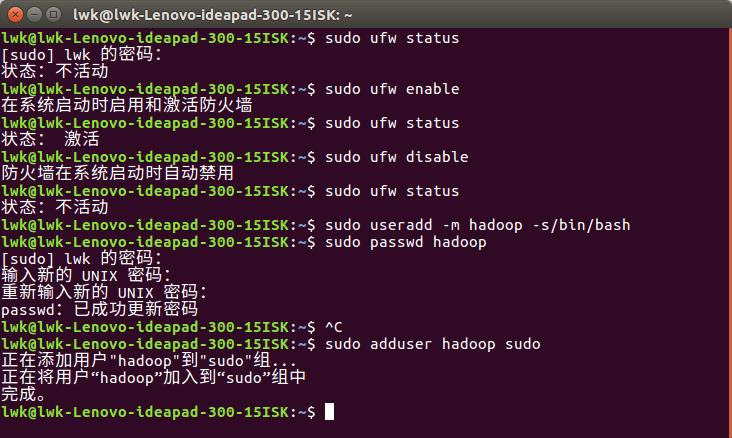
3)可以为hadoop用户增加管理员权限, 方便部署, 避免一些新手来说比较棘手的权限问题.
三.更新apt
ubuntu如何切换到其他用户
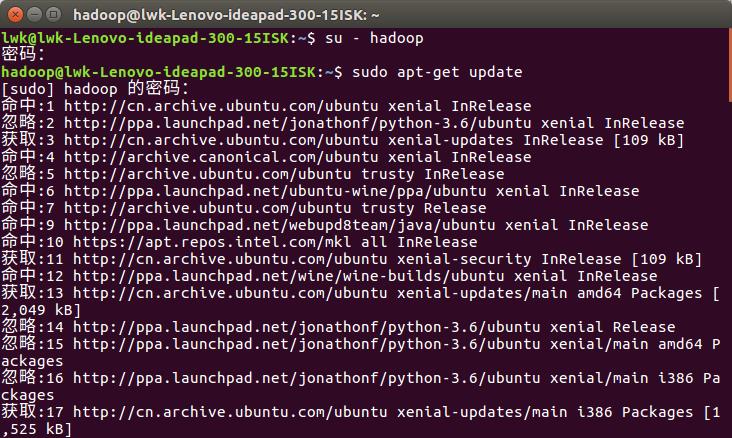
如果是字符终端切换的话,用 “su - 其他用户名”,这个命令就可以了。
-
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。
-
按 ctrl+alt+t 打开终端窗口,
-
执行如下命令:
sudo apt-get update
安装SSH、配置SSH无密码登陆
-
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,
-
并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
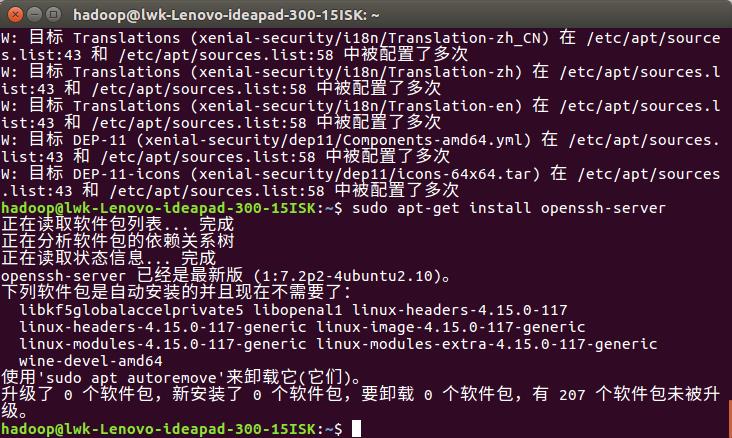
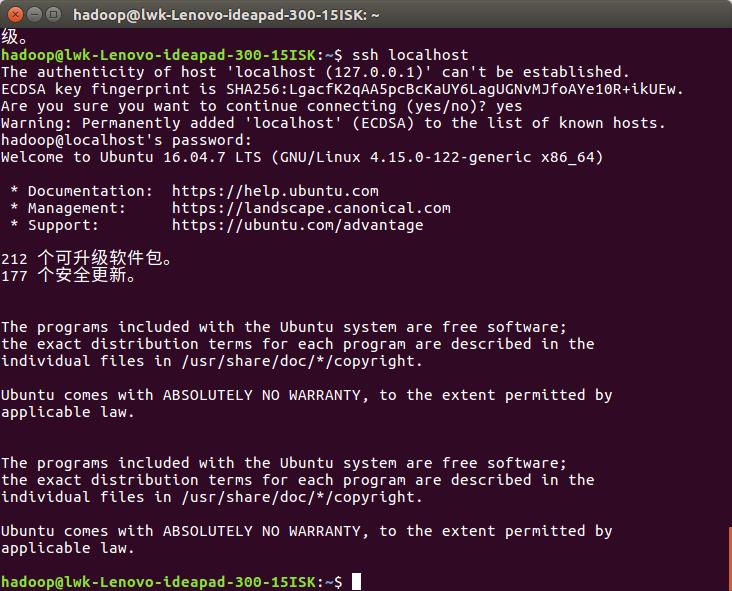
2. 安装后,可以使用如下命令登陆本机(此时会有如下提示(SSH首次登陆提示),输入 yes 。
然后按提示输入密码 hadoop,这样就登陆到本机了, 但这样登陆是需要每次输入密码的,
我们需要配置成SSH无密码登陆比较方便):
ssh localhost
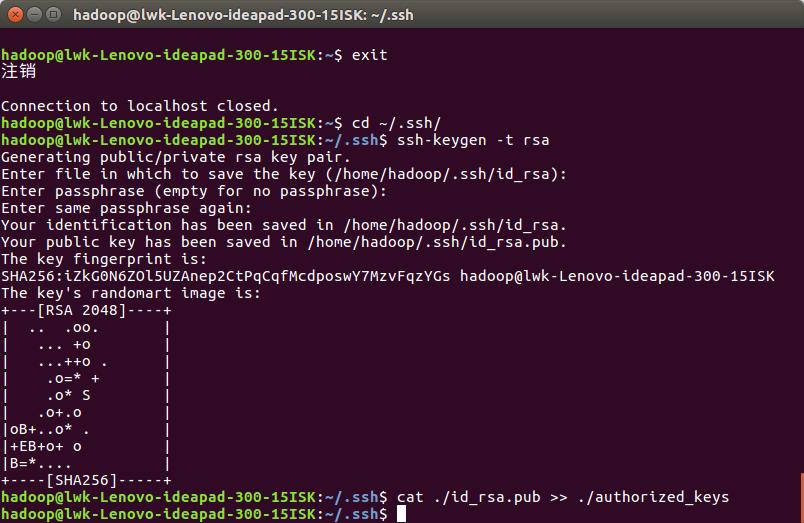
3) 首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,
并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
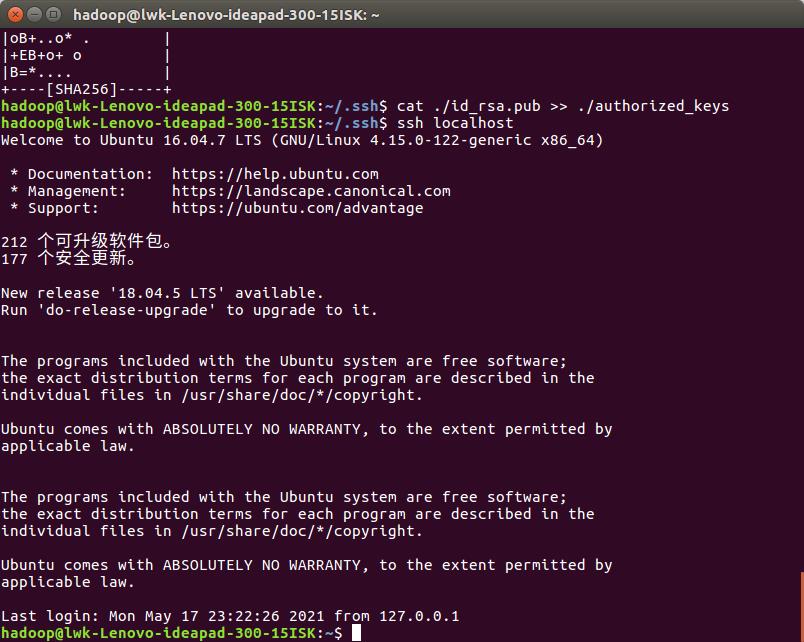
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示
安装配置JDK
-
Java环境可选择 Oracle 的 JDK,或是 OpenJDK,通过命令安装 OpenJDK 7。
sudo apt-get install openjdk-8-jre openjdk-8-jdk
-
在文件最前面添加如下单独一行:
vi ~/.bashrc # 设置JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
-
使 JAVA_HOME 变量生效:
source ~/.bashrc # 使变量设置生效
在单节点(伪分布式)环境下运行HADOOP
1.安装 Hadoop 2
cd ~/下载
sudo tar -zxvf ./hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
2.进行伪分布式配置
修改配置文件 core-site.xml (vim /usr/local/hadoop/etc/hadoop/core-site.xml):
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有一个 Slave 节点,所以 dfs.replication 的值还是设为 1
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
文件 yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.启动 Hadoop:
cd /usr/local/hadoop
bin/hdfs namenode -format # namenode 格式化
sbin/start-dfs.sh # 开启守护进程
jps # 判断是否启动成功
4.运行 WordCount 实例
bin/hdfs dfs -mkdir -p /user/hadoop # 创建HDFS目录
bin/hdfs dfs -mkdir input
bin/hdfs dfs -put etc/hadoop/*.xml input # 将配置文件作为输入
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.2.jar wordcount input output
bin/hdfs dfs -cat output/* # 查看输出
以上是关于云计算环境Hadoop安装与配置的主要内容,如果未能解决你的问题,请参考以下文章