kmeans算法
Posted 北极星!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kmeans算法相关的知识,希望对你有一定的参考价值。
3.1划分方法

聚类算法距离——k-means算法

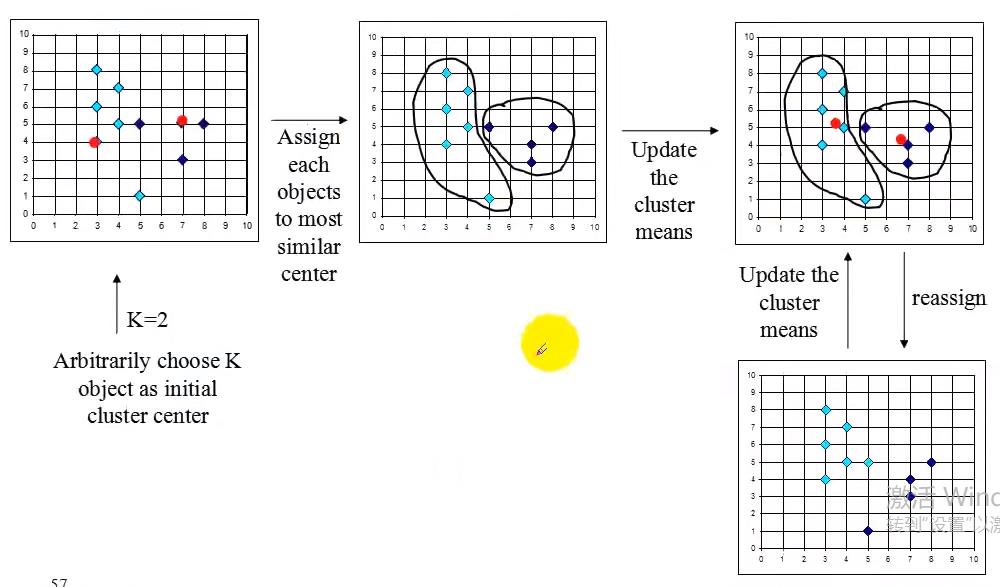
k-means算法

输入:簇的数;数据集;
输出:k个簇
方法:从数据集中找出k个对象当作原始的簇心;
k-means算法的再次解读

k-means聚类算法练习-1
下面1-10个样本
使用代码计算连续值属性距离
import numpy as np
a=np.array([(3,4),(3,6),(7,3),(4,7),(3,8),(8,5),(4,5),(4,1),(7,4),(5,5)])
lines=""
for i in a:
for j in a:
dis=np.sqrt(np.sum((j-i)**2))
lines += "%.2f"%dis + "," #保留两位小数 #“str(dis)+","
lines+=\'\\n\'
file=open("result.csv",mode="w",encoding="utf-8")
file.write(lines)
file.close()
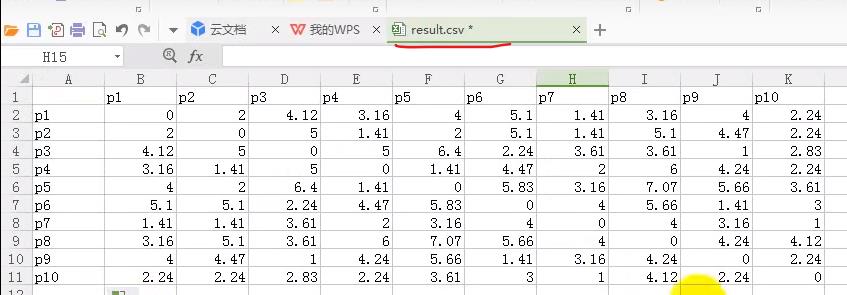
第一轮迭代完得到的分别以p7、p10为中心的两个簇
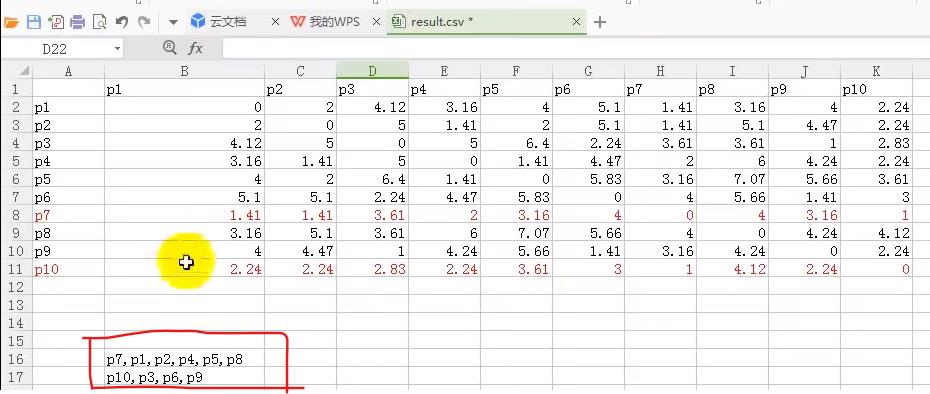
下面开始计算每个簇中心的均值
p7、p1、p2、p4、p5、p8样本点的x值相加求平均,y值相加求平均得到一个新的簇中心点
p10、p3、p6、p9样本点的x值相加求平均,y值相加求平均得到一个新的簇中心点
新的簇中心点再来和所有的样本数据点求距离

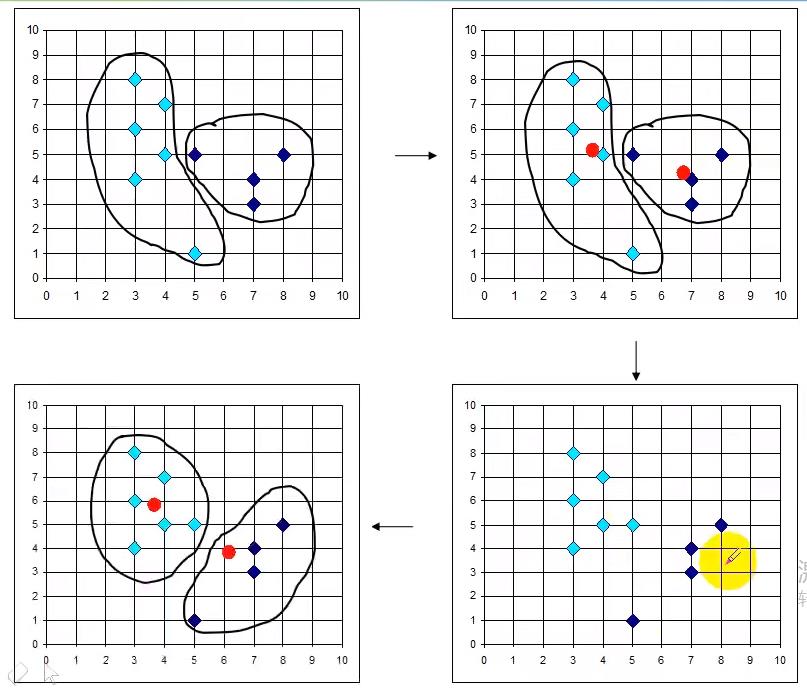
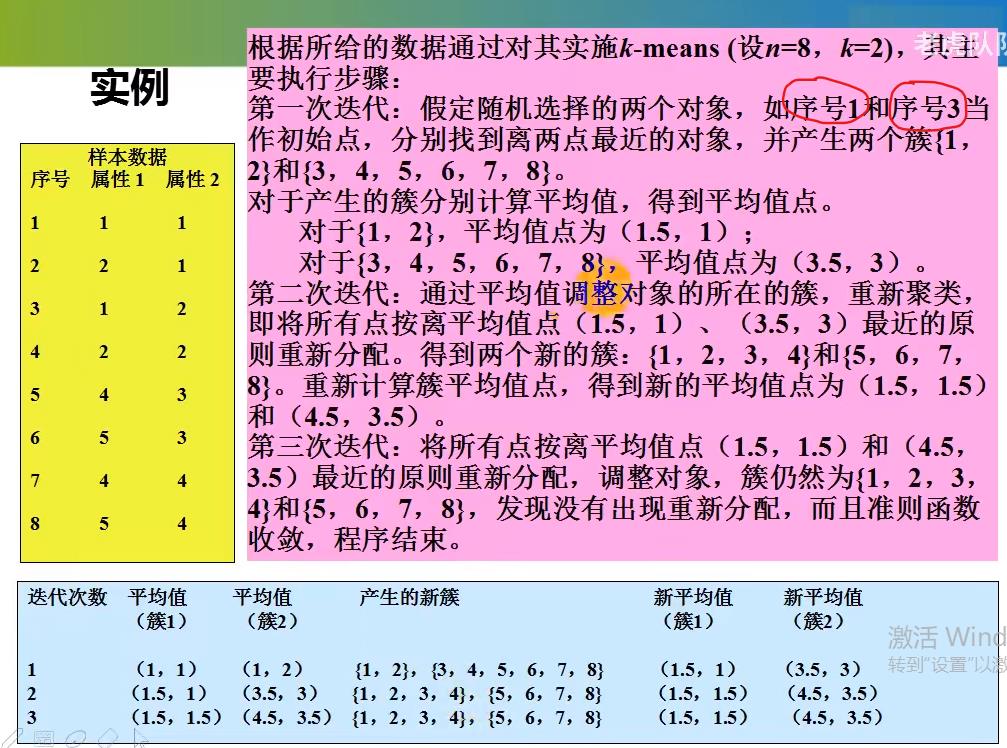
实例
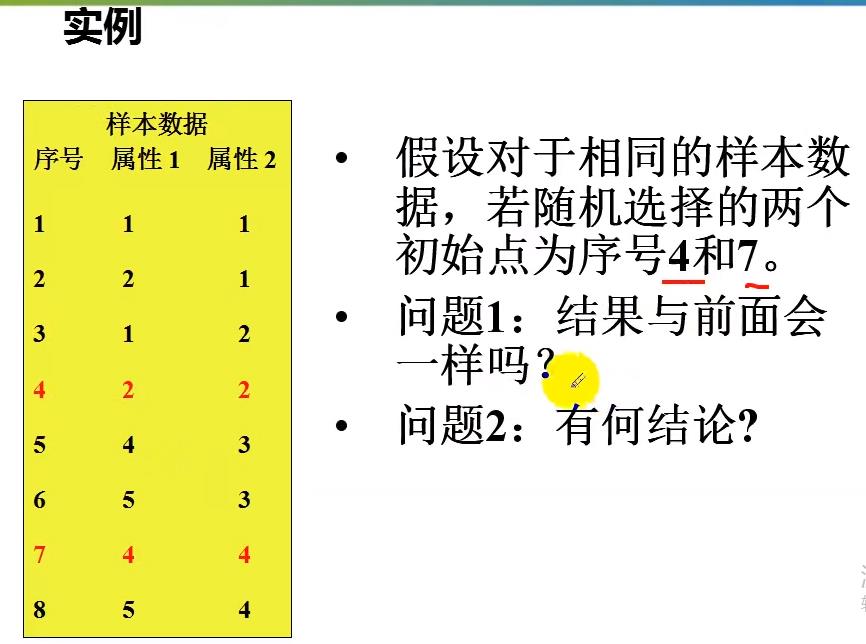
序号4和7是一样的(巧合),其实换做其他的序号3和7,与之前的结果不一样
结论是:k-means算法 的初始中心点对k-means算法有极大的影响,不同的初始点可能最终聚类的结果不同,特别是数据样本比较少的情况下

以上是关于kmeans算法的主要内容,如果未能解决你的问题,请参考以下文章