机器学习——实验一
Posted bycsdn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习——实验一相关的知识,希望对你有一定的参考价值。
| 作业属于课程 | 机器学习实验—计算机18级 |
|---|---|
| 作业要求链接 | 实验一 感知器及其应用 |
| 学号 | 3180701110 |
实验一 感知器及其应用
【实验目的】
- 理解感知器算法原理,能实现感知器算法;
- 掌握机器学习算法的度量指标;
- 掌握最小二乘法进行参数估计基本原理;
- 针对特定应用场景及数据,能构建感知器模型并进行预测。
【实验内容】
- 安装Pycharm,注册学生版。
- 安装常见的机器学习库,如Scipy、Numpy、Pandas、Matplotlib,sklearn等。
- 编程实现感知器算法。
- 熟悉iris数据集,并能使用感知器算法对该数据集构建模型并应用。
【实验过程及结果】
实验代码及注释
①
#导入包
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
%matplotlib inline
②
# load data
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df[\'label\'] = iris.target
③
#columns是列名(列索引)
df.columns = [\'sepal length\', \'sepal width\', \'petal length\', \'petal width\', \'label\']//将各个列重命名
df.label.value_counts()value_counts//计算相同数据出现的次数
结果截图

④
#画散点图,第一维数据作为x轴,第二维数据作为y轴,[\'sepal length\',\'sepal width\']特征分布查看
plt.scatter(df[:50][\'sepal length\'], df[:50][\'sepal width\'], label=\'0\') //绘制散点图
plt.scatter(df[50:100][\'sepal length\'], df[50:100][\'sepal width\'], label=\'1\')
plt.xlabel(\'sepal length\') //给图加上图例
plt.ylabel(\'sepal width\')
plt.legend()

⑤
data = np.array(df.iloc[:100, [0, 1, -1]])#iloc函数:通过行号来取行数据,读取数据前100行的第0,1列和最后一列
⑥
X, y = data[:,:-1], data[:,-1] //X为sepal length,sepal width y为标签
⑦
y = np.array([1 if i == 1 else -1 for i in y]) //将y的标签设置为1或者-1
⑧
# 定义算法
# 此处为一元一次线性方程
class Model:
def __init__(self):
self.w = np.ones(len(data[0])-1, dtype=np.float32) #初始w的值
self.b = 0 #初始b的值为0
self.l_rate = 0.1 #步长为0.1
# self.data = data
def sign(self, x, w, b):
y = np.dot(x, w) + b #dot进行矩阵的乘法运算,y=w*x+b
return y
#随机梯度下降法
def fit(self, X_train, y_train):
is_wrong = False #初始假设有误分点
while not is_wrong:
wrong_count = 0 #误分点个数初始为0
for d in range(len(X_train)):
X = X_train[d] #取X_train一组及一行数据
y = y_train[d] #取y_train一组及一行数据
if y * self.sign(X, self.w, self.b) <= 0: #为误分点
self.w = self.w + self.l_rate*np.dot(y, X) #对w和b进行更新
self.b = self.b + self.l_rate*y
wrong_count += 1 #误分点个数加1
if wrong_count == 0: #误分点个数为0,算法结束
is_wrong = True
return \'Perceptron Model!\'
def score(self):
pass
⑨
perceptron = Model()
perceptron.fit(X, y)//感知机模型
结果截图

⑩
#绘制模型图像,定义一些基本的信息
x_points = np.linspace(4, 7,10)//x轴的划分
y_ = -(perceptron.w[0]*x_points + perceptron.b)/perceptron.w[1]
plt.plot(x_points, y_)//绘制模型图像(数据、颜色、图例等信息)
plt.plot(data[:50, 0], data[:50, 1], \'bo\', color=\'blue\', label=\'0\')
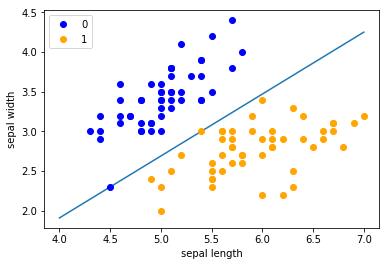
plt.plot(data[50:100, 0], data[50:100, 1], \'bo\', color=\'orange\', label=\'1\')
plt.xlabel(\'sepal length\')
plt.ylabel(\'sepal width\')
plt.legend()
结果截图
⑪
from sklearn.linear_model import Perceptron//定义感知机(下面将使用感知机)
⑫
clf = Perceptron(fit_intercept=False, max_iter=1000, shuffle=False)
clf.fit(X, y)//使用训练数据拟合

⑬
# Weights assigned to the features.
print(clf.coef_)//输出感知机模型参数
⑭
# 截距 Constants in decision function.
print(clf.intercept_)//输出感知机模型参数
⑮
x_ponits = np.arange(4, 8) //确定x轴和y轴的值
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_) //确定拟合的图像的具体信息(数据点,线,大小,粗细颜色等内容)
plt.plot(data[:50, 0], data[:50, 1], \'bo\', color=\'blue\', label=\'0\')
plt.plot(data[50:100, 0], data[50:100, 1], \'bo\', color=\'orange\', label=\'1\')
plt.xlabel(\'sepal length\')
plt.ylabel(\'sepal width\')
plt.legend()
结果截图

实验小结
本次是关于感知器的实验,感知机是根据输入实例的特征向量对其进行二类分类的线性分类模型。其中,感知机学习的策略是极小化损失函数。通过这次实验,理解了感知器算法原理,能实现一些有关感知器算法。
以上是关于机器学习——实验一的主要内容,如果未能解决你的问题,请参考以下文章