k8s 高可用reboot之后 NotReady 问题解决
Posted 王玊玉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s 高可用reboot之后 NotReady 问题解决相关的知识,希望对你有一定的参考价值。
前奏参见:二进制安装部署k8s高可用集群V1.20 - 运维人在路上 - 博客园 (cnblogs.com)
首先感谢“运维人在路上”的分享。
按照文档搭建的环境搭建好
2天后发现环境重启之后出现 NotReady的问题。
检查服务一切ok VIP就是不能漂到backup服务器
Reboot之后再开机出现

这是我的服务器一览表
|
名称 |
IP |
组件 |
|
Master1 |
192.168.1.20 |
Kube-apiserver Kube-controller-manager Kube-scheduler Etcd Docker Kubelet Kube-proxy keepalived |
|
Master2 |
192.168.1.23 |
Kube-apiserver Kube-controller-manager Kube-scheduler Etcd Docker Kubelet Kube-proxy Nginx Keepalived |
|
Node1 |
192.168.1.21 |
Etcd Docker Kubelet Kube-proxy |
|
Node2 |
192.168.1.22 |
Etcd Docker Kubelet Kube-proxy |
|
vip |
192.168.1.26 |
Lb均衡器 |
[root@master ~]# kubectl get node NAME STATUS ROLES AGE VERSION master NotReady <none> 3d1h v1.20.6 master2 NotReady <none> 28h v1.20.6 node01 NotReady <none> 3d1h v1.20.6 node02 NotReady <none> 3d1h v1.20.6 [root@master ~]# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR scheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true"} etcd-2 Healthy {"health":"true"} etcd-1 Healthy {"health":"true"} [root@master ~]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-97769f7c7-z4vhv 1/1 Running 1 3d1h calico-node-k6zgl 1/1 Running 1 28h calico-node-ldlmm 1/1 Running 1 3d1h calico-node-x4sbz 1/1 Running 1 3d1h calico-node-xls58 1/1 Running 1 3d1h coredns-6cc56c94bd-jtrln 1/1 Running 1 3d
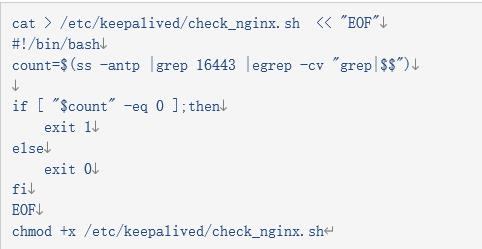
经过很长时间查找问题最后发现是check_nginx 脚本有点逻辑问题
ss -antp |grep 16443 |egrep -cv "grep|$$" 里面由大量 TIME_WAIT 信息导致脚本逻辑不能正常执行网上提供方法需要优化内核
https://blog.csdn.net/qq_40460909/article/details/80563284 没有尝试感觉不太适合
关闭master nginx之后发现VIP没有到backup 服务器
[root@master ~]# systemctl stop nginx [root@master ~]# ip a s eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:1f:3e:c7 brd ff:ff:ff:ff:ff:ff inet 192.168.1.20/24 brd 192.168.1.255 scope global noprefixroute eth0 valid_lft forever preferred_lft forever inet 192.168.1.26/24 scope global secondary eth0 valid_lft forever preferred_lft forever inet6 fe80::e021:da77:a9b6:f716/64 scope link noprefixroute valid_lft forever preferred_lft forever
检查keepalived服务,正在运行。
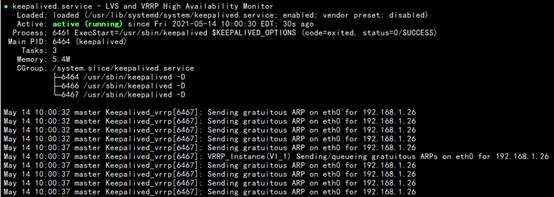
检查完脚本之后运行里面的命令
[root@master ~]# ss -antp |grep 16443 |egrep -cv "grep|$$" 79
这样逻辑上 $count > 0 返回0 系统就默认正常从而导致keepalived不能漂到backup服务器,那么apiserver就无法链接导致了NotReady
要满足 $count=0 那么只有两台同时关闭了nginx keepalived 才能满足
[root@master ~]# ss -antp |grep 16443 |egrep -cv "grep|$$" 0 [root@master2 ~]# ss -antp |grep 16443 |egrep -cv "grep|$$" 0
后来就尝试修改了一下脚本,如下。多次reboot之后也没有发现问题。
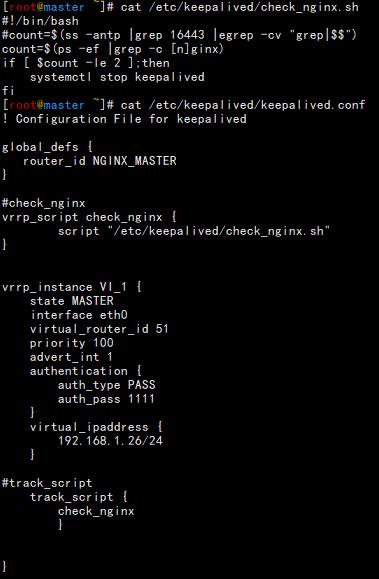
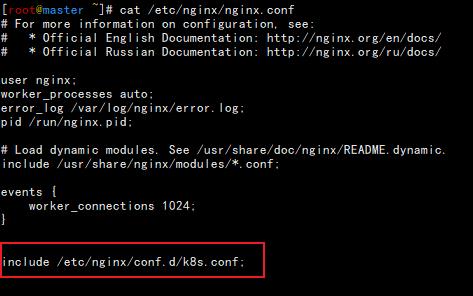
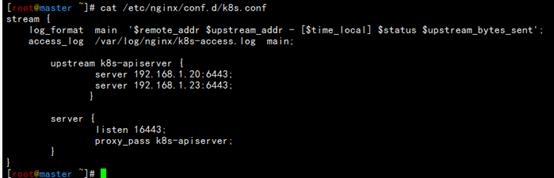
Nginx 部分采用的是默认配置nginx.conf文件里面唯一修改的地方是把
include /etc/nginx/conf.d/k8s.conf 移动到http 前面。
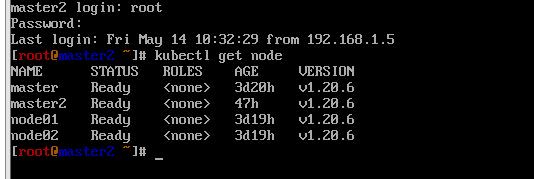
最后reboot 一切正常 高可用也没有问题。

以上是关于k8s 高可用reboot之后 NotReady 问题解决的主要内容,如果未能解决你的问题,请参考以下文章