一致性哈希算法
Posted Acx7
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一致性哈希算法相关的知识,希望对你有一定的参考价值。
Hash算法
Hash算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式——百度百科
通俗点说就是让任意长度的数据映射成为长度固定的值。
Hash算法的作用
一、就是数据的快速存储以及插入、删除、查找。一般使用数据结构Map(Dictionary/Hashtable)。它是根据key来直接访问value的数据结构。将key通过一定的Hash函数计算变成通用一致的格式(索引),就可以实现类似数组的快速查找。
二、Hash算法也可以看做是一种加密算法,但是这个加密算法只有加密的过程没有解密的过程,是不可逆的。各种加密货币中的密钥体系或多或少都用到了Hash算法,其中比较有名的像:MD4,MD5,SHA-1,SHA-2,SHA-3等。除了加密货币,Hash的加密算法在文件校验,数字签名,鉴权协议等方面都有非常重要的作用。
Hash算法在分布式应用中的不足
在分布式系统中,如果数据是存储在很多个节点中,由于节点的状态是不稳定的,可能新增节点也可能随时有节点下线,节点的个数和在线时间都是不稳定的。要将数据存储到具体的节点上,如果我们采用普通的Hash算法进行路由,将数据映射到具体的节点上,如key % N,key是数据的key,N是节点数,如果有一个节点加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。如何在这样的不稳定的环境中保证数据的正确命中,不会因为节点个数的增减而导致大部分数据的失效,这就是一致性Hash算法需要解决的问题。
一致性哈希算法
一致性哈希提出了在动态变化的Cache环境中,哈希算法应该满足的4个适应条件——百度百科
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,即均匀分布。这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
一致性哈希算法原理:
一致性Hash算法是在1997年由麻省理工学院提出的一种分布式Hash实现算法。
环形Hash空间
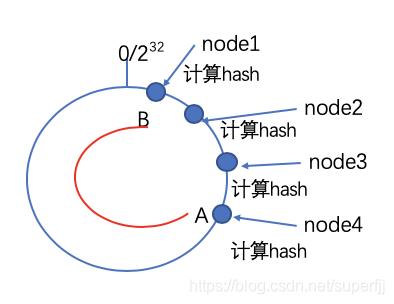
一致性哈希算法核心就是使用常用的Hash算法将key映射到一个具有2^32次方个桶空间中,即0-(2^32-1)的数字空间中。我们可以将这些数字头尾相连,想象成一个闭合的环形。圆环上面有2^32个节点位置。算法首先计算出存储节点在圆环上的位置。具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。这一点是为了保证算法的分散性:节点的位置跟具体多少个节点没关系,只跟节点的内在特性有关系。
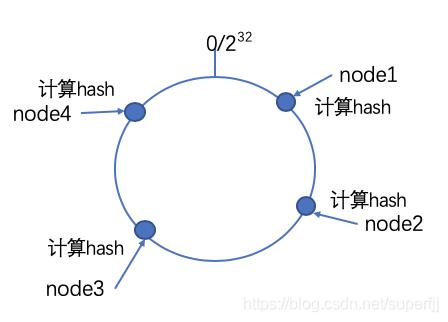
将数据通过Hash算法映射到环上
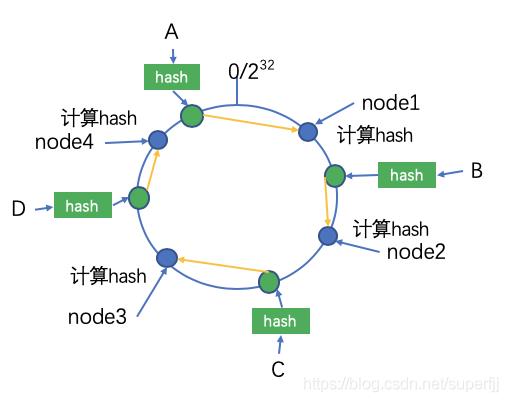
我们假设有4个节点:node1,node2,node3,node4。计算好他们的位置之后,接下来我们就需要就计算出各个不同的key的存储位置,将key用同样的算法计算出Hash值,从而确定其在数据环上的位置,然后从此位置沿着顺时针寻找,遇到的第一个服务器就是该数据应该存储的节点。
如下图所示,有A,B,C,D四个数据对象,经过Hash计算之后,其在图中的位置和应该存在的节点位置如下:其中A存储在node1节点,B存储在node2节点,C存储在node3节点,D存储在node4节点。
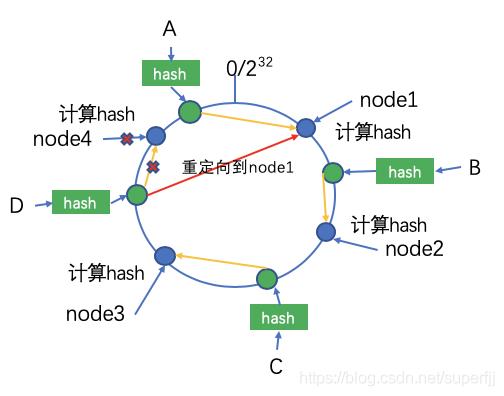
节点的删除
下面我们考虑下节点挂掉的情况,如下图所示,当node4节点挂掉之后,按照一致性hash算法的原则,A,B,C存储节点不做任何变化,只有D节点会重新存储到node1上。如下图所示:
节点的增加
同样的,假如我们添加了一个node5节点,其hash值在C和node3之间,则只有C的存储位置需要转移。如下图所示:
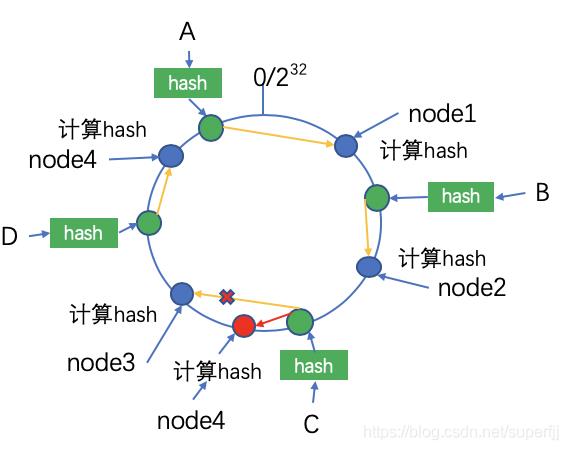
由此可见,一致性hash算法在系统节点变化的时候,只需要重定向一小部分数据的存储位置,具有较强的容错性和可扩展性。
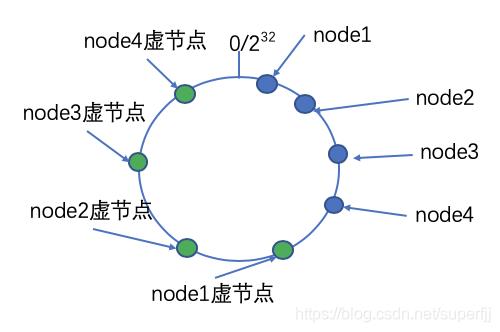
虚拟节点
当系统中节点很少的情况下,或者现有的节点计算出来的Hash值比较接近的情况下,如上图所示,所有A-B这一段路径上的数据都会存储在node1上面,很明显这会导致node1上面数据过多,不满足系统分散性的需求。
解决办法就是我们可以创建一些虚拟节点,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,这样就可以解决数据倾斜的问题。如下图所示:
以上是关于一致性哈希算法的主要内容,如果未能解决你的问题,请参考以下文章