对于简单的反扒
Posted name=韩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对于简单的反扒相关的知识,希望对你有一定的参考价值。
print("----------反扒-------------") #(headers req 反扒) url = \'https://www.cnblogs.com/\'
# 用户代理 headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE"}
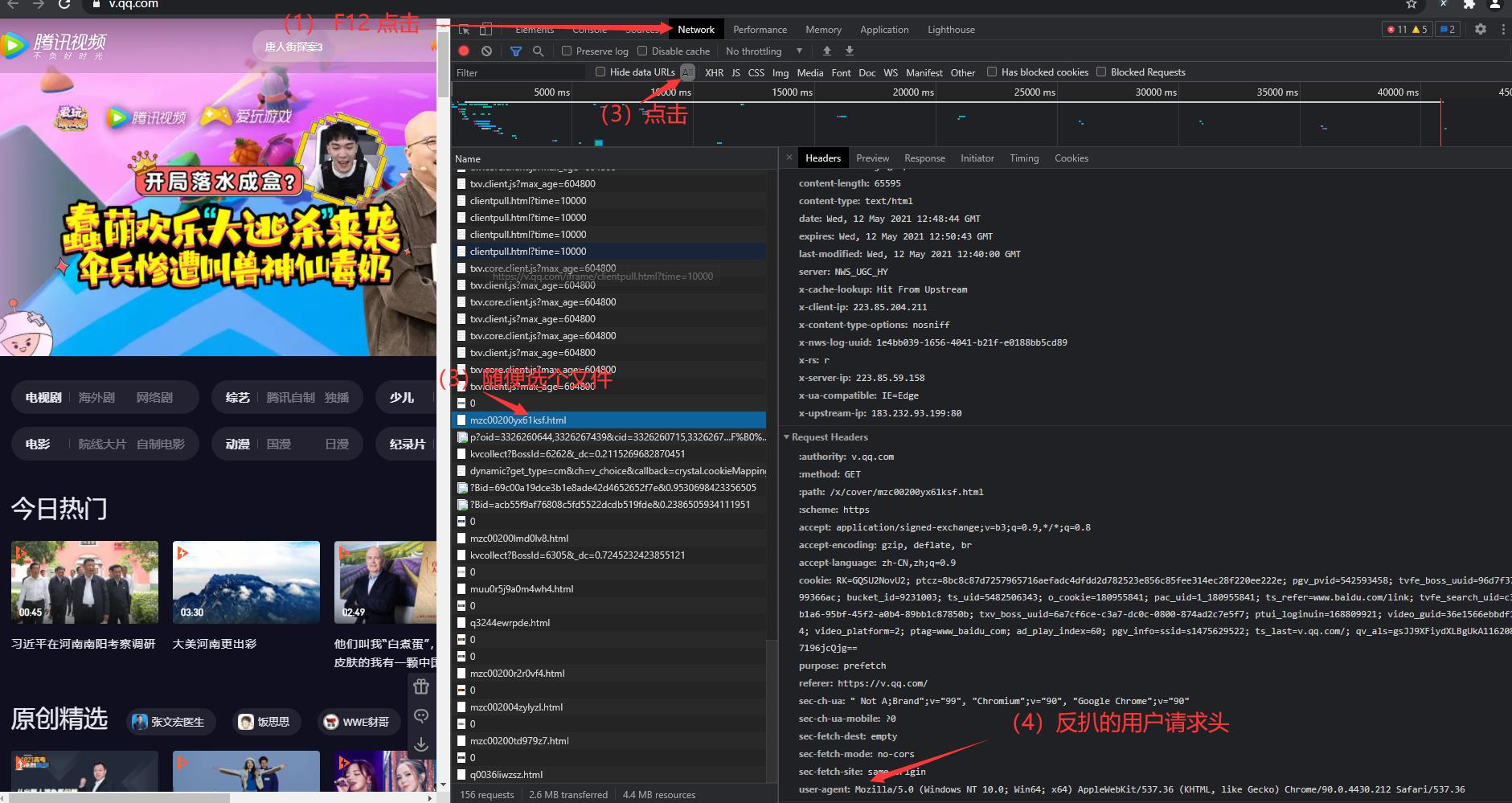
# 构建请求对象 req=urllib.request.Request(url=url,headers=headers) # 用urlopen打开 resp = urllib.request.urlopen(req) # 从响应中获取数据 并且更改编码格式 html = resp.read().decode(\'utf-8\') # 输出 print(html)
以上是关于对于简单的反扒的主要内容,如果未能解决你的问题,请参考以下文章