Linux 系统调用
Posted fellow_jing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux 系统调用相关的知识,希望对你有一定的参考价值。
用户空间的程序无法直接执行内核代码。它们不能直接调用内核空间中的函数,因为内核驻留在受保护的地址空间上。如果进程可以直接在内核的地址空间上读写的话,系统安全就会失去控制。所以,应用程序应该以某种方式通知系统,告诉内核自己需要执行一个系统调用,希望系统切换到内核态,这样内核就可以代表应用程序来执行该系统调用了。
通知内核的机制是靠软件中断实现的。首先,用户程序为系统调用设置参数。其中一个参数是系统调用编号。参数设置完成后,程序执行“系统调用”指令。x86系统上的软中断由int产生。这个指令会导致一个异常:产生一个事件,这个事件会致使处理器切换到内核态并跳转到一个新的地址,并开始执行那里的异常处理程序。此时的异常处理程序实际上就是系统调用处理程序。它与硬件体系结构紧密相关。
下图是系统调用过程示意图 :
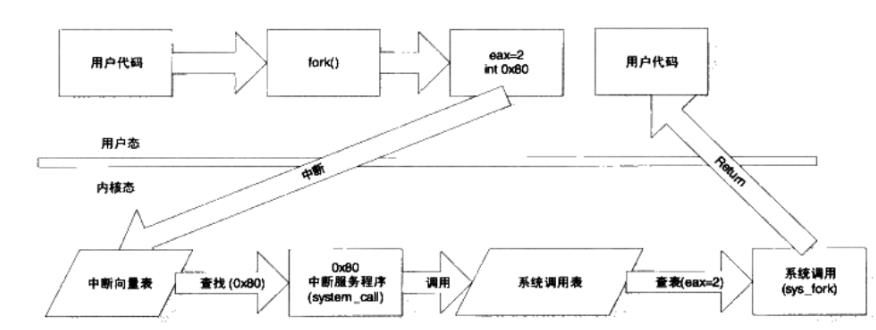
下面我们以open为例,来看看kernel的调用过程的。
系统调用号与系统调用程序的对应关系定义在include/uapi/asm-generic/unistd.h
#define __NR_open 1024
__SYSCALL(__NR_open, sys_open)
include/linux/syscall.h重定义了系统调用相关的宏
#define SYSCALL_DEFINE0(sname) \\
SYSCALL_METADATA(_##sname, 0); \\
asmlinkage long sys_##sname(void)
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
#define SYSCALL_DEFINEx(x, sname, ...) \\
SYSCALL_METADATA(sname, x, __VA_ARGS__) \\
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \\
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \\
__attribute__((alias(__stringify(SyS##name)))); \\
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \\
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \\
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \\
{ \\
long ret = SYSC##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \\
__MAP(x,__SC_TEST,__VA_ARGS__); \\
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \\
return ret; \\
} \\
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__))
在fs/open.c中,
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)//由上面的宏,可看出此处是sys_open的实现地方。
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op;
int fd = build_open_flags(flags, mode, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);//获取文件名称
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(flags);//获取可用的fd
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);//创建struct file结构,打开文件
if (IS_ERR(f)) {
put_unused_fd(fd);//打开文件失败,释放fd
fd = PTR_ERR(f);
} else {
fsnotify_open(f);//将文件加到监控系统中,监控文件打开关闭。
fd_install(fd, f);//将struct file 指针加到以fd为idx的array中,以便后续对文件操作。
}
}
putname(tmp);
return fd;
}
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct nameidata nd;
int flags = op->lookup_flags;
struct file *filp;
set_nameidata(&nd, dfd, pathname);
filp = path_openat(&nd, op, flags | LOOKUP_RCU);//open文件。
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(&nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(&nd, op, flags | LOOKUP_REVAL);
restore_nameidata();
return filp;
}
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
const char *s;
struct file *file;
int opened = 0;
int error;
file = get_empty_filp();//分配struct file
if (IS_ERR(file))
return file;
file->f_flags = op->open_flag;
if (unlikely(file->f_flags & __O_TMPFILE)) {
error = do_tmpfile(nd, flags, op, file, &opened);
goto out2;
}
if (unlikely(file->f_flags & O_PATH)) {
error = do_o_path(nd, flags, file);//如果文件打开的flag是O_PATH,可能是directory.在函数里会调用vfs_open
if (!error)
opened |= FILE_OPENED;
goto out2;
}
s = path_init(nd, flags);
if (IS_ERR(s)) {
put_filp(file);
return ERR_CAST(s);
}
while (!(error = link_path_walk(s, nd)) &&//解析文件名,转换成dentry
(error = do_last(nd, file, op, &opened)) > 0) {//open的最后一步,通过dentry查找inode,并最后调用vfs_open
nd->flags &= ~(LOOKUP_OPEN|LOOKUP_CREATE|LOOKUP_EXCL);
s = trailing_symlink(nd);
if (IS_ERR(s)) {
error = PTR_ERR(s);
break;
}
}
terminate_walk(nd);
out2:
if (!(opened & FILE_OPENED)) {
BUG_ON(!error);
put_filp(file);
}
if (unlikely(error)) {
if (error == -EOPENSTALE) {
if (flags & LOOKUP_RCU)
error = -ECHILD;
else
error = -ESTALE;
}
file = ERR_PTR(error);
}
return file;
}
int vfs_open(const struct path *path, struct file *file,
const struct cred *cred)
{
struct dentry *dentry = d_real(path->dentry, NULL, file->f_flags);
if (IS_ERR(dentry))
return PTR_ERR(dentry);
file->f_path = *path;
return do_dentry_open(file, d_backing_inode(dentry), NULL, cred);//打开文件
}
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *),
const struct cred *cred)
{
static const struct file_operations empty_fops = {};
int error;
f->f_mode = OPEN_FMODE(f->f_flags) | FMODE_LSEEK |
FMODE_PREAD | FMODE_PWRITE;
path_get(&f->f_path);
f->f_inode = inode;
f->f_mapping = inode->i_mapping;
if (unlikely(f->f_flags & O_PATH)) {//如果flag包含O_PATH.则struct file_operations是空的
f->f_mode = FMODE_PATH;
f->f_op = &empty_fops;
return 0;
}
if (f->f_mode & FMODE_WRITE && !special_file(inode->i_mode)) {
error = get_write_access(inode);
if (unlikely(error))
goto cleanup_file;
error = __mnt_want_write(f->f_path.mnt);
if (unlikely(error)) {
put_write_access(inode);
goto cleanup_file;
}
f->f_mode |= FMODE_WRITER;
}
/* POSIX.1-2008/SUSv4 Section XSI 2.9.7 */
if (S_ISREG(inode->i_mode) || S_ISDIR(inode->i_mode))
f->f_mode |= FMODE_ATOMIC_POS;
f->f_op = fops_get(inode->i_fop);//获取inode对应的struct file_operations结构
if (unlikely(WARN_ON(!f->f_op))) {
error = -ENODEV;
goto cleanup_all;
}
error = security_file_open(f, cred);
if (error)
goto cleanup_all;
error = break_lease(inode, f->f_flags);
if (error)
goto cleanup_all;
if (!open)
open = f->f_op->open;//inode所对应的open函数,如果是设备文件,则是驱动程序的open函数。
if (open) {
error = open(inode, f);//调用inode所对应的open函数。
if (error)
goto cleanup_all;
}
if ((f->f_mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ)
i_readcount_inc(inode);
if ((f->f_mode & FMODE_READ) &&likely(f->f_op->read || f->f_op->read_iter))
f->f_mode |= FMODE_CAN_READ;
if ((f->f_mode & FMODE_WRITE) &&likely(f->f_op->write || f->f_op->write_iter))
f->f_mode |= FMODE_CAN_WRITE;
f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC);
file_ra_state_init(&f->f_ra, f->f_mapping->host->i_mapping);
return 0;
cleanup_all:
fops_put(f->f_op);
if (f->f_mode & FMODE_WRITER) {
put_write_access(inode);
__mnt_drop_write(f->f_path.mnt);
}
cleanup_file:
path_put(&f->f_path);
f->f_path.mnt = NULL;
f->f_path.dentry = NULL;
f->f_inode = NULL;
return error;
}
以上是关于Linux 系统调用的主要内容,如果未能解决你的问题,请参考以下文章