Python-模块-Python笔记7
Posted 假文艺青年。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python-模块-Python笔记7相关的知识,希望对你有一定的参考价值。
random:随机数
内部封装了一些关于随机数的方法
random.random(0.0, 1.0): 获取0.0~1.0之间的随机浮点数random.unifrom(a, b): 获取a~b的随机浮点数random.randint(a, b): 随机获取a~b的整数random.shuffle(iterable): 对传进来的可迭代对象进行洗序(必须是可变的数据类型)random.sample(x, k): 取样x为需要取样的数据,k为在该数据里抽取元素的个数
time:时间
内部封装了获取时间戳和字符串形式的时间的一些方法
讲这个模块之前先提一嘴时间戳是给什么玩意!
-
时间戳 即1970年1月1日 00点00分00秒 开始到指定的时间所经过的秒数,不考虑闰秒。
-
time.time():获取当前时间戳 -
time.gmtime(): 获取格式化时间对象 返回值为 GMT时间 即 格林尼治时间(默认参数是当前系统时间的时间戳) -
time.localtime(): 获取本地格式化时间对象(默认参数是当前系统时间的时间戳) -
time.strftime("%Y-%m-%d %H:%M-%S"): 将格式化形式的时间转换为字符串形式的时间 若没有指定t(格式化时间)默认使用当前系统时间
| 指令 | 含义 | 注释 |
|---|---|---|
| %a | 本地化的缩写星期中每日的名称。 | |
| %A | 本地化的星期中每日的完整名称。 | |
| %b | 本地化的月缩写名称。 | |
| %B | 本地化的月完整名称。 | |
| %c | 本地化的适当日期和时间表示。 | |
| %d | 十进制数 [01,31] 表示的月中日。 | |
| %H | 十进制数 [00,23] 表示的小时(24小时制)。 | |
| %I | 十进制数 [01,12] 表示的小时(12小时制)。 | |
| %j | 十进制数 [001,366] 表示的年中日。 | |
| %m | 十进制数 [01,12] 表示的月。 | |
| %M | 十进制数 [00,59] 表示的分钟。 | |
| %p | 本地化的 AM 或 PM 。 | -1 |
| %S | 十进制数 [00,61] 表示的秒。 | -2 |
| %U | 十进制数 [00,53] 表示的一年中的周数(星期日作为一周的第一天)。 在第一个星期日之前的新年中的所有日子都被认为是在第 0 周。 | -3 |
| %w | 十进制数 [0(星期日),6] 表示的周中日。 | |
| %W | 十进制数 [00,53] 表示的一年中的周数(星期一作为一周的第一天)。 在第一个星期一之前的新年中的所有日子被认为是在第 0 周。 | -3 |
| %x | 本地化的适当日期表示。 | |
| %X | 本地化的适当时间表示。 | |
| %y | 十进制数 [00,99] 表示的没有世纪的年份。 | |
| %Y | 十进制数表示的带世纪的年份。 | |
| %z | 时区偏移以格式 +HHMM 或 -HHMM 形式的 UTC/GMT 的正或负时差指示,其中H表示十进制小时数字,M表示小数分钟数字 [-23:59, +23:59] 。 | |
| %Z | 时区名称(如果不存在时区,则不包含字符)。 | |
| %% | 字面的 \'%\' 字符。 |
这是我从官方文档里复制过来的time.strftiem()参数的相关含义,以防日后需要!
time.strptime(string, format): 将字符串时间转换成格式化时间 传递进来的字符串时间与format格式必须一样即time.strptime("2021 04 03 17:00:28", "%Y %m %d %H:%M:%S")如果字符串时间没有指定月日或时分秒,默认使用 1月 1日 0时0分0秒time.mktime(): 将格式化时间转换成时间戳time.sleep(s): 暂停当前线程, 参数s 传递进去的必须是数字 表示暂停多少秒
datetime 日期时间
里面封装了一些关于日期时间的类
-
date(year, month, day)类d = date(1991, 1, 1)创建对象print(d): 1991-01-01d.year:获取参数year 的值 --- 1991d.month:获取参数month 的值 --- 1d.day:获取参数day 的值 --- 1
-
time类t = time(1, 30, 5)
-
t.hour获取 时 --- 01t.minute获取 分 --- 30t.second获取 秒 --- 05
-
datetime类 -
dt = datetime(1991, 1, 1, 0, 0, 0)上面两个的结合,方法也几乎一样不写了 -
timedelta类 时间变化量-
from datetime import * td = timedelta(days=3) d = datetime(1991, 1, 1) d += td print(d) # 结果 # 1991-01-04 00:00:00
-
os 操作系统相关的操作
- 文件相关操作
os.remove(path): 删除指定文件os.rename(path_filename, new_path_filename):更改文件名称os.removedirs(dir_name): 删除目录(只能删除空目录)如果需要删除带文件的目录可以使用shutil模块的rmtree()方法
- 路径相关操作
- 获取path的上级目录路径:
os.path.dirname(path): # 只是将路径最后\\或/和后面的字符串一起去除,并不会判断路径是否存在 - 获取path的文件名称:
os.path.basname(path)# 只是将路径最后\\或/后面的字符串提取出来,并不会判断文件是否存在 - 把路径名和文件名分开:
os.path.split(path): 返回一个二元组 只是路径名和文件名分开,并不会判断路径和文件是否存在 - 拼接路径:
os.path.join(path)# 并不会判断路径是否存在 - 返回路径 path 的绝对路径:
os.path.abspath(path): # 如果是绝对路径之间返回,如果是/开头的就将当前根目录拼接到path前面,如果只是目录名或文件名开头的就将当前路径添加到path前面。
- 获取path的上级目录路径:
- 路径相关判断
- 判断路径是否是绝对路径 :
os.path.isabs(path)# 并不会判断路径是否存在 - 判断是否是目录:
os.path.isdir(path) - 判断是否是文件:
os.path.isfile(path) - 判断文件或目录是否存在,也可以说是判断路径是否存在:
os.path.exists(path)
- 判断路径是否是绝对路径 :
sys 解释器相关操作
- 脚本执行时,获取脚本后面的参数:
sys.argv -
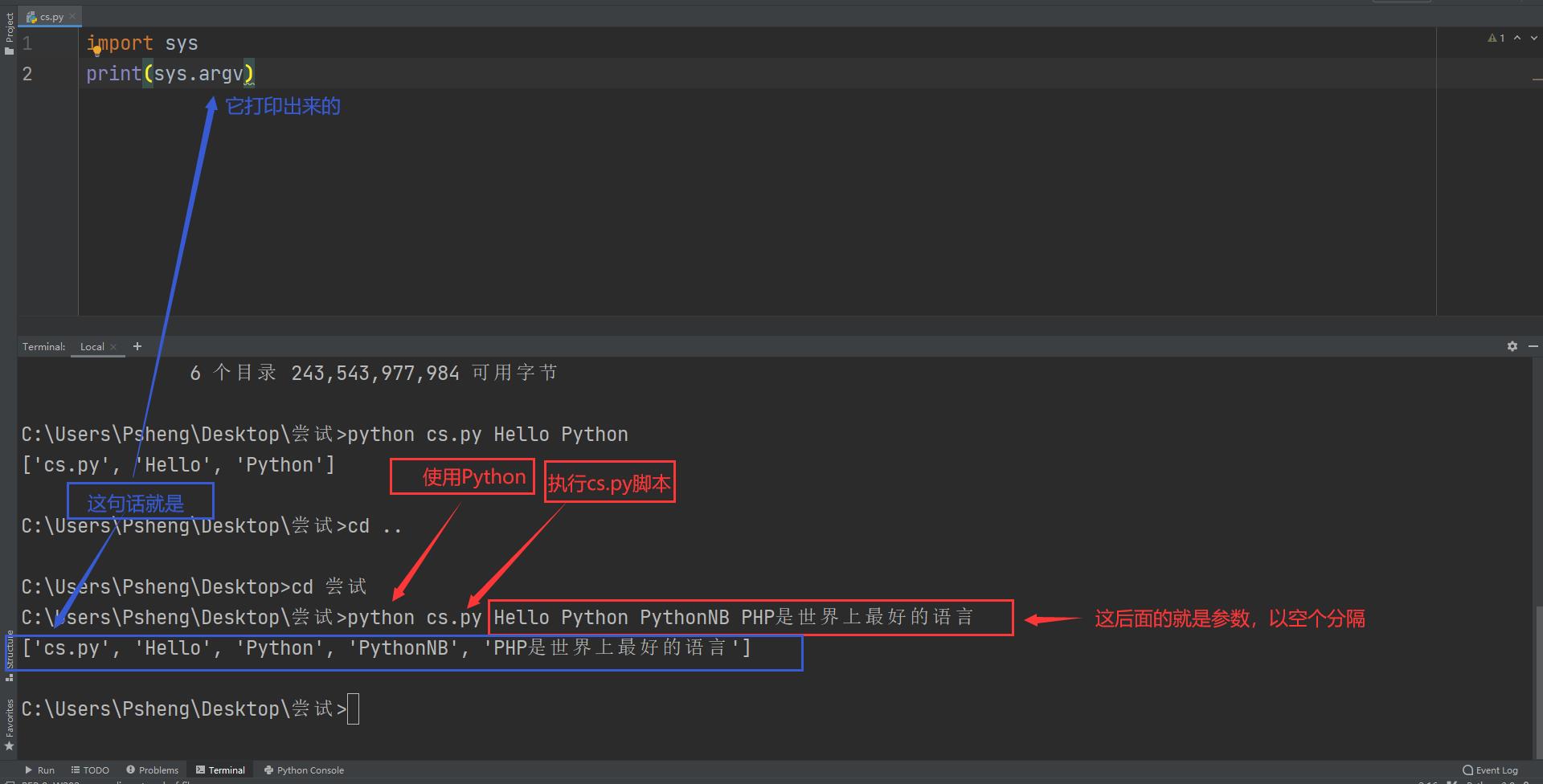
- 解释器寻找模块的路径
sys.path - 返回系统已经加载的模块:
sys.modules返回的是一个字典
json
javascript Object Notation:java脚本对象标记语言
是一种简单的数据交换格式
讲json模块之前我们得先了解一下序列化和反序列化,以及计算机硬盘中储存的数据是以什么形式储存。
-
在我们计算机的存储与传输过程中,都是用字节也就是
bytes类型进行存储或传输的。1bytes = 8bit -
序列化: 序列化是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中。也就是说序列化是将列表或字典整数字符串等等这类数据转换成字符串或者字节,以便于网络传输,或者储存成文件。
-
反序列化:反序列化是指将序列化后字符串或者字节重新转换成数据结构或者对象的过程。
-
序列化与反序列化总结:
- 序列化: 将数据结构或对象转换成二进制串的过程
- 反序列化:将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程
知道了序列化的概念后就开始看json模块的简单使用了
-
json.dumps():序列化-
import json j = json.dumps([1, 2, 3]) print(f"这是序列化后的列表: {j},它的类型是: {type(j)}") print(f"验证是否真的是字符串,我们来切片吧。 切片结果:{j[0]}") # 这里切片如是列表返回的就肯定是 1 如果是字符串就会返回 [ """ 结果: 这是序列化后的列表: [1, 2, 3],它的类型是: <class \'str\'> 验证是否真的是字符串,我们来切片吧。 切片结果:[ """
-
-
json.dump():序列化并写入文件 注:(只能一次写入)-
json.dump的功能 与json.dumps的功能几乎一样,不一样的是json.dump与文件操作结合起来了(序列化后直接写入文件)。 需要传递一个文件句柄的参数。 -
import json with open("json.txt", mode="wt+", encoding="utf-8") as file: json.dump([1, 2, 3], file) # 移动文件指针 file.seek(0) # 读取json.txt里的内容 read_file = file.read() print(f"这是读取的文件内容: {read_file},它的类型是: {type(read_file)}") """ 结果: 这是读取的文件内容: [1, 2, 3],它的类型是: <class \'str\'> """
-
-
json.loads():反序列化,需要传递一个序列化后的对象-
import json # 序列化后的列表 j = json.dumps([1, 2, 3]) # 反序列化 json_lds = json.loads(j) print(f"这是反序列化后的列表: {json_lds},它的类型是: {type(json_lds)}") print(f"验证是否真的是字符串,我们来切片吧。 切片结果:{json_lds[0]}") # 这里切片如是列表返回的就肯定是 1 如果是字符串就会返回 [ """ 结果: 这是序列化后的列表: [1, 2, 3],它的类型是: <class \'list\'> 验证是否真的是字符串,我们来切片吧。 切片结果:1 """
-
-
json.load():读取序列化后的文件,并将读取到的内容反序列化 注:(只能一次读取)-
json.load的功能 与json.loads的功能几乎一样,不一样的是json.load与文件操作结合起来了(读取序列化后的文件,并将读取到的内容反序列化)。 需要传递一个文件句柄的参数。 -
import json with open("json.txt", mode="rt", encoding="utf-8") as file: # 反序列化 json_ld = json.load(file) print(f"这是反序列化后的列表: {json_ld},它的类型是: {type(json_ld)}") """ 结果: 这是反序列化后的列表: [1, 2, 3],它的类型是: <class \'list\'> """
-
-
注意事项:
-
json只能序列化部分数据类型,具体参考以下官方文档-
序列化
JSON(序列化后的类型) Python(Python数据类型) object dict array list, tuple string str number int, float, int- & float-derived Enums true True false False null None -
反序列化
-
JSON(序列化后的类型) Python(反序列化后的Python的数据类型) object dict array list string str number (int) int number (real) float true True false False null None
-
-
通过上面的官方文档我们可以看到,列表和元组序列化后都是
array类型,而array类型反序列化后是列表,也就是说元组序列化后再反序列化回来后数据类型就会变成列表 -
没有在上方表格中的数据结构就是
json不支持序列化的数据结构
-
pickle
pickle模块的使用方法与json 几乎一模一样,不一样的是 pickle支持python的所有数据类型序列化,且序列化后是二进制串也就是bytes类型。
-
pickle.dumps()序列化-
import pickle pk_dumps = pickle.dumps([1, 2, 3]) print(f"这是序列化后的列表: {pk_dumps}") print(f"它的类型是: {type(pk_dumps)}") """ 结果: 这是序列化后的列表: b\'\\x80\\x04\\x95\\x0b\\x00\\x00\\x00\\x00\\x00\\x00\\x00]\\x94(K\\x01K\\x02K\\x03e.\' 它的类型是: <class \'bytes\'> """
-
-
pickle.dump():序列化并写入文件 注:(能进行多次写入)-
import pickle with open("pickle.txt", mode="wb+") as file: pickle.dump([1, 2, 3], file) # 移动文件指针 file.seek(0) # 读取json.txt里的内容 read_file = file.read() print(f"这是序列化后的列表: {read_file}") print(f"它的类型是: {type(read_file)}") """ 结果: 这是读取的文件内容: b\'\\x80\\x04\\x95\\x0b\\x00\\x00\\x00\\x00\\x00\\x00\\x00]\\x94(K\\x01K\\x02K\\x03e.\' 它的类型是: <class \'bytes\'> """
-
-
pickle.loads()反序列化-
import pickle # 序列化后的列表 pk_dumps = pickle.dumps([1, 2, 3]) # 反序列化 pk_loads = pickle.loads(pk_dumps) print(f"这是反序列化后的列表: {pk_loads},它的类型是: {type(pk_loads)}") """ 结果: 这是序列化后的列表: [1, 2, 3],它的类型是: <class \'list\'> """
-
-
pickle.load():读取序列化后的文件,并将读取到的内容反序列化 注:(能进行多次读取,都是读取的次数要与写入的次数一致,否则报错)-
import pickle with open("pickle.txt", mode="rb") as file: # 反序列化 pickle_ld = pickle.load(file) print(f"这是反序列化后的列表: {pickle_ld},它的类型是: {type(pickle_ld)}") """ 结果: 这是反序列化后的列表: [1, 2, 3],它的类型是: <class \'list\'> """
-
hashlib
hashlib 模块里面封装了一些哈希加密算法,哈希加密算法的原理是将一段数据
-
加密的目的用于判断和验证,而并非解密。例如:登录验证,如果帐号秘密加密后的结果与你储存的结果一致则登录验证通过。
-
特点:
- 可以将一段数据进行分段加密,且分段加密后的结果与整体加密的结果一致。
- 单向加密,基本上不可逆。
- 对一个数据进行小改动,改动前和改动后的加密结果将是天差地别,没有规律可循。
-
实例:(整体加密)
-
import hashlib # 导入hashlib模块 # 创建md5加密对象(还可以创建其他加密对象。如 sha256、sha3_256、sha512等等, 具体使用dir(hashlib)方法查看) md5_obj = hashlib.md5() # 调用加密对象的update方法,传入需要加密的数据,只能识别字节需要先将加密数据装换为字节串 md5_obj.update("我是加密数据".encode("utf-8")) # 获取加密结果(有两种方法) str_res = md5_obj.hexdigest() # 获取到的结果类型是字符串 bytes_res = md5_obj.digest() # 获取到的结果类型是字节类型 print(str_res) print(bytes_res) """ 结果: 86f6252ea6697af2da21bd2e7861c4d0 b\'\\x86\\xf6%.\\xa6iz\\xf2\\xda!\\xbd.xa\\xc4\\xd0\' """ -
实例2:(分段加密)
-
import hashlib # 导入hashlib模块 # 创建加密对象 md5_obj = hashlib.md5() # update可以多次调用,进行分段加密,实例2的加密结果与上面实例的结果是一致的。 md5_obj.update("我".encode("utf-8")) md5_obj.update("是".encode("utf-8")) md5_obj.update("加".encode("utf-8")) md5_obj.update("密".encode("utf-8")) md5_obj.update("数据".encode("utf-8")) # 获取加密结果(有两种方法) str_res = md5_obj.hexdigest() # 获取到的结果类型是字符串 bytes_res = md5_obj.digest() # 获取到的结果类型是字节类型 print(str_res) print(bytes_res) """ 结果: 86f6252ea6697af2da21bd2e7861c4d0 b\'\\x86\\xf6%.\\xa6iz\\xf2\\xda!\\xbd.xa\\xc4\\xd0\' """ -
创建加密对象时直接传入需要加密的数据(另外一种加密方法)
-
import hashlib # 导入hashlib模块 # 创建加密对象时直接传入需要加密的数据,结果跟上面两个实例是一样的 md5_obj = hashlib.md5("我是加密数据".encode("utf-8")) # 获取加密结果(有两种方法) str_res = md5_obj.hexdigest() # 获取到的结果类型是字符串 bytes_res = md5_obj.digest() # 获取到的结果类型是字节类型 print(str_res) print(bytes_res) """ 结果: 86f6252ea6697af2da21bd2e7861c4d0 b\'\\x86\\xf6%.\\xa6iz\\xf2\\xda!\\xbd.xa\\xc4\\xd0\' """
-
-
加盐(salt)
-
加盐本质上就是在加密数据是添加一些与加密数据外的数据一起进行加密,可以增加一定的安全性。
-
实例:
-
数据: python_yyds
-
import hashlib # 导入hashlib模块 # 创建加密对象,且加盐 md5_obj = hashlib.md5(b"123456") # 这里也可以先不指定任何数据,在下面调用update方法,结果是一样的。 md5_obj.update(b"python_yyds") # 获取加密结果 str_res = md5_obj.hexdigest() # 获取到的结果类型是字符串 print(str_res) -
如上面的实例,如果其他人得到了你的数据(python_yyds),他通过你的数据不没有办法直接获取到一样的加密结果,需要获取到跟上面实例中一样的加密结果必须获取 所有的加密数据(123456)(python_yyds)且加密的顺序要一致。才能获取到一样的加密结果。
-
collections
-
collections主要封装了一些常用的容器类 -
namedtuple(): 命名元组,可使用定义的每次获取指定的值,增加元组可读性-
import collections Person = collections.namedtuple("Person_class", ["name", "age", "high"]) # 创建人物信息 make = Person("make", 18, 170) # 查看人物信息 print(make.name) print(make.age) print(make.high) """ 结果: make 18 170 """
-
-
defaultdict()默认值字典,指定了默认值的默认值字典,假如调用了不存在该字典中的key并不会报错,而是创建这个键,且值为你指定的默认参数。-
import collections # 创建默认值字典 # 第一个参数可以传递一个拥有返回值的参数,且该返回值会作为该字典的默认值参数, # 后面是 **kwargs 创建键值对 df_dict = collections.defaultdict(lambda: "python", a="this a", b="this b") print(df_dict["a"]) # 这是在上面创建字典时就创建的 print(df_dict["b"]) print(df_dict) """ 结果: this a this b defaultdict(<function <lambda> at 0x7fba2e199ee0>, {\'a\': \'this a\', \'b\': \'this b\'}) """ -
# 接下来尝试打印不存在的键 print(df_dict["c"]) # 打印结果为: python # 再打印整个字典看看 print(df_dict) """ 结果: defaultdict(<function <lambda> at 0x7f3742300ee0>, {\'a\': \'this a\', \'b\': \'this b\', \'c\': \'python\'}) """ -
通过上面的实例我们可以看到,默认值字典可以指定一个有返回值的函数,用这个函数的返回值作为默认值字典的默认值,当我们调用的
key不存在是,默认值字典会自动把我们创建这个key且值为你指定的默认值。
-
-
Counter()计数器-
from collections import Counter # 字符串 str_ = "hello python" # 计算上面这个字符串中每个字母出现的次数 str_count = Counter(str_) # 打印结果 print(str_count) """ 结果: Counter({\'h\': 2, \'l\': 2, \'o\': 2, \'e\': 1, \' \': 1, \'p\': 1, \'y\': 1, \'t\': 1, \'n\': 1}) """
-
以上是关于Python-模块-Python笔记7的主要内容,如果未能解决你的问题,请参考以下文章