linux0.11源码内核——系统调用,int80的实现细节
Posted zsbenn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux0.11源码内核——系统调用,int80的实现细节相关的知识,希望对你有一定的参考价值。
linux0.11添加系统调用的步骤
假设添加一个系统调用foo()
1.修改include/linux/sys.h
添加声明
extern int foo();
同时在sys_call_table数组的最后添加一个元素
...,sys_foo
2.修改include/unistd.h
增加一个调用号宏
#define __NR_iam 72
再声明供用户调用的函数
int foo();
3.修改kernel/sys_call.s:
增加调用个数
nr_system_calls = 74
4.新增文件kernel/foo.c,里面包含foo函数,实现系统调用
5.修改kernel/Makefile
补充和foo.c相关的规则
OBJS = ... who.o ...... ### Dependencies: foo.s foo.o: foo.c ../include/unistd.h \\ ../include/asm/segment.h ../include/errno.h ......
到此为止代码的修改已经完成了,下面就是进行make重新生成os镜像:
到linux-0.11目录下make一次计可,生成的Image就可以作为新系统来驱动计算机了
然后需要挂载hdc,把修改过的sys.h和unistd.h覆盖hdc里面那个系统的usr/include/unistd.h和ust/include/linux/sys.h,最后卸载hdc
然后在oslab里运行./run启动新系统,在里面编写测试文件进行测试新的系统调用就可以啦!
系统调用:系统库中为系统调用编写了许多接口函数(API),不同的API对应了不同的真正的(OS内核中)系统调用
系统调用的三个基本步骤:
1.把系统调用编号存到 寄存器eax中
2.把函数参数传到其他通用寄存器中:第一个参数:ebx,第二个:ecx ...
3.触发0x80号中断
在内核加载完毕,切换到用户模式下时,会做一些初始化工作(如main.c里一大堆_init()函数),最后一步启动shell,
用户在shell中可以进行进程调度
int 0x80的触发过程和实现细节
1.一些宏定义和头文件include/unistd,h的细节
先看一个系统调用close()的API
#define __LIBRARY__ #include <unistd.h> _syscall1(int, close, int, fd)
_syscall1是个宏,在include/unistd.h中定义
#define _syscall1(type,name,atype,a) \\ type name(atype a) \\ { \\ long __res; \\ __asm__ volatile ("int $0x80" \\ : "=a" (__res) \\ : "0" (__NR_##name),"b" ((long)(a))); \\ if (__res >= 0) \\ return (type) __res; \\ errno = -__res; \\ return -1; \\ }
close()用该宏展开后就是
int close(int fd) { long __res; __asm__ volatile ("int $0x80" : "=a" (__res) : "0" (__NR_close),"b" ((long)(fd))); if (__res >= 0) return (int) __res; errno = -__res; return -1; }
它先将宏 __NR_close 存入 EAX,将参数 fd 存入 EBX,然后进行 0x80 中断调用。调用返回后,从 EAX 取出返回值,存入 __res,再通过对 __res 的判断决定传给 API 的调用者什么样的返回值
__NR_close就是系统调用close的对应的编号,该宏在include/unistd.h中定义
__NR_name其实就是系统调用name的对应的编号
2.从中断进入内核
OS内核初始化时(init/main.c函数进行初始化),调用了一个sched_init()函数
void main(void) { // …… time_init(); sched_init(); buffer_init(buffer_memory_end); // …… }
sched_init()在kernel/sched.c中定义。作用是将各种编号的中断和中断处理程序的地址进行绑定
而0x80中断则和system_call函数进行绑定
void sched_init(void) { // …… set_system_gate(0x80,&system_call); }
set_system_gate 是个宏,在 include/asm/system.h 中定义:
#define set_system_gate(n,addr) \\ _set_gate(&idt[n],15,3,addr)
_set_gate()函数的第一个参数是中断描述符表,表中的每个指针指向一个中断描述符,n=80时对应的描述符就是int80的描述符
3表示将DPL修改成3,因为用户态的CPL是3,这么修改使CPL>=DPL,从而得以进入内核(只有int80的DPL是3,所以用户态只能通过int80进入内核)
addr是中断处理程序,这里将system_call填到int80的中断描述符中
事实上,_set_gate()函数也是一个被定义的宏,其展开后为
#define _set_gate(gate_addr,type,dpl,addr) \\ __asm__ ("movw %%dx,%%ax\\n\\t" \\ "movw %0,%%dx\\n\\t" \\ "movl %%eax,%1\\n\\t" \\ "movl %%edx,%2" \\ : \\ : "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \\ "o" (*((char *) (gate_addr))), \\ "o" (*(4+(char *) (gate_addr))), \\ "d" ((char *) (addr)),"a" (0x00080000))
这段代码做的就是上述的事
接下去看int80的中断处理函数system_call,定义在 kernel/system_call.s 中,是纯汇编代码
1 !…… 2 ! # 这是系统调用总数。如果增删了系统调用,必须做相应修改 3 nr_system_calls = 72 4 !…… 5 6 .globl system_call 7 .align 2 8 system_call: 9 10 ! # 检查系统调用编号是否在合法范围内 11 cmpl \\$nr_system_calls-1,%eax 12 ja bad_sys_call 13 push %ds 14 push %es 15 push %fs 16 pushl %edx 17 pushl %ecx 18 19 ! # push %ebx,%ecx,%edx,是传递给系统调用的参数 20 pushl %ebx 21 22 ! # 让ds, es指向GDT,内核地址空间 23 movl $0x10,%edx 24 mov %dx,%ds 25 mov %dx,%es 26 movl $0x17,%edx 27 ! # 让fs指向LDT,用户地址空间 28 mov %dx,%fs 29 call sys_call_table(,%eax,4) 30 pushl %eax 31 movl current,%eax 32 cmpl $0,state(%eax) 33 jne reschedule 34 cmpl $0,counter(%eax) 35 je reschedule
system_call 用 .globl 修饰为其他函数可见。
call sys_call_table(,%eax,4):根据寻址方式 展开成 call sys_call_table + 4 * %eax
其中eax是系统调用号,
sys_call_table 是一个指针数组,每个指针指向一个系统调用函数,其定义在 include/linux/sys.h 中
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,...
所以4*%eax的意思其实是eax对应的函数指针在表中的地址
至此已经找到了内核中系统调用函数的那个指针,所以直接调用该指针对应的函数就可以啦!
3.用户态和内核态之间数据的传递过程
指针参数传递的是应用程序所在地址空间的逻辑地址,在内核中如果直接访问这个地址,访问到的是内核空间中的数据,不会是用户空间的。所以这里还需要一点儿特殊工作,才能在内核中从用户空间得到数据
例如,调用open(char *filename, ……),
int open(const char * filename, int flag, ...) { // …… __asm__("int $0x80" :"=a" (res) :"0" (__NR_open),"b" (filename),"c" (flag), "d" (va_arg(arg,int))); // …… }
eax里存了open的调用号,ebx里存了filename字符串指针,即指向了用户态的一串字符串,ecx存了flag...
现在的问题是,内核态要找ebx里的地址对应的字符串时,是在内核态的地址里找的,而ebx里的地址对应的是用户态的
所以要进行一些转换,在system_call函数里:
system_call: //所有的系统调用都从system_call开始 ! …… pushl %edx pushl %ecx pushl %ebx # push %ebx,%ecx,%edx,这是传递给系统调用的参数 movl $0x10,%edx # 让ds,es指向GDT,指向核心地址空间 mov %dx,%ds mov %dx,%es movl $0x17,%edx # 让fs指向的是LDT,指向用户地址空间 mov %dx,%fs call sys_call_table(,%eax,4) # 即call sys_open
可见,在call sys_open前,system对一些寄存器做了处理,
重点来看fs寄存器!
首先ds,es指向了gdt,即指向了内核的gdt,
但是fs指向了ldt,ldt对应的是用户态的地址空间
所以通过fs指向用户态地址,ds,es指向内核态地址来进行用户空间和内核空间的信息传递
不了解gdt和ldt的话看下图,来源:https://www.cnblogs.com/chenwb89/p/operating_system_003.html
其实cs的选择子作用在用户态是体现在ldt上的,即可以通过ldt来寻找某个段的地址
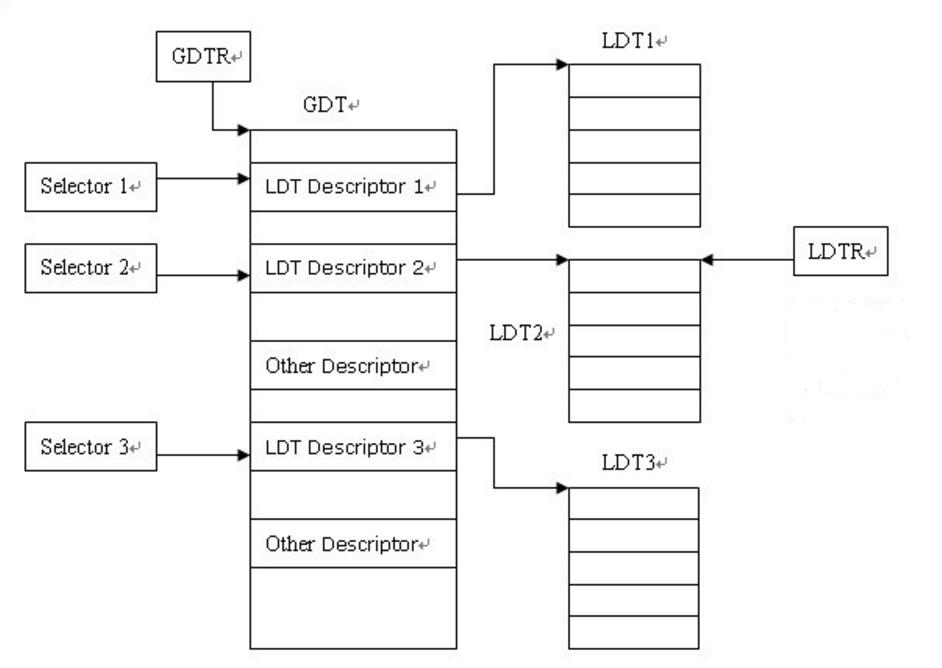
总之,依靠fs可以进行用户态的寻址并获取数据,下面看sys_open,在 fs/open.c 文件中定义
int sys_open(const char * filename,int flag,int mode) //filename这些参数从哪里来? /*是否记得上面的pushl %edx, pushl %ecx, pushl %ebx? 实际上一个C语言函数调用另一个C语言函数时,编译时就是将要 传递的参数压入栈中(第一个参数最后压,…),然后call …, 所以汇编程序调用C函数时,需要自己编写这些参数压栈的代码…*/ { …… if ((i=open_namei(filename,flag,mode,&inode))<0) { …… } …… }
sys_open将最重要的功能交给open_namei(),然后open_namei()再交给dir_namei(),get_dir()
最后get_dir()中调用了一个get_fs_byte()
static struct m_inode * get_dir(const char * pathname) { …… if ((c=get_fs_byte(pathname))==\'/\') { …… } …… }
显然,get_fs_byte(pathname)获得了一个用户空间的fs寄存器指向的字节数据,
那么同理,也有put_fs_byte函数向fs指向的用户空间输出函数
这两个函数被定义在include/asm/segment.h :
extern inline unsigned char get_fs_byte(const char * addr) { unsigned register char _v; __asm__ ("movb %%fs:%1,%0":"=r" (_v):"m" (*addr)); return _v; } extern inline void put_fs_byte(char val,char *addr) { __asm__ ("movb %0,%%fs:%1"::"r" (val),"m" (*addr)); }
事实上,他俩以及所有 put_fs_xxx() 和 get_fs_xxx() 都是用户空间和内核空间之间的桥梁
实验部分:增加iam和whoami两个系统调用
思路:
iam的api里应该有一段包含int80指令的宏_syscall(),把iam对应的系统调用号赋值给eax,其余参数赋值给其余通用寄存器
通过int80切入到内核中,首先要在unist.h里新增系统调用宏_NR_iam 对应的编号
因为int80是通过system_call处理的,system_call里的系统调用宏个数应该+1
sys.h里应该加上sys_iam的系统调用函数声明,同在sys.h里的 sys_call_table应该加上iam个指针,这样才能通过system_call找到这两个函数的地址
然后在kernel里建立who.c,里面实现函数sys_iam
然后还要再修改makefile里的数据
实验做起来还有很多细节的东西,我是参考这篇博客的 https://www.shiyanlou.com/courses/reports/1264940/
以上是关于linux0.11源码内核——系统调用,int80的实现细节的主要内容,如果未能解决你的问题,请参考以下文章