爬虫小程序(爬取英雄联盟的英雄皮肤)
Posted su_sir
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫小程序(爬取英雄联盟的英雄皮肤)相关的知识,希望对你有一定的参考价值。
一、爬虫流程:
1、明确目标:url = https://daoju.qq.com/lol/list/17-0-0-0-0-0-0-0-0-0-0-00-0-0-1-1.shtml?ADTAG=innercop.lol.SY.shoppinglist_new_17
2、判断数据类型:动态/静态(这里是动态类型,是通过JS渲染的)
备注:如何来判断数据类型?是通过源码来判断的,如果网页源码中可以找到我们需要爬取的数据,那么就代表是静态,可以通过访问网页后结合正则就可以获取数据,如果网页源码找不到我们需要的数据,则是动态,一般动态都是通过js进行渲染页面
3、利用工具找到数据:可以通过F12或者抓包工具
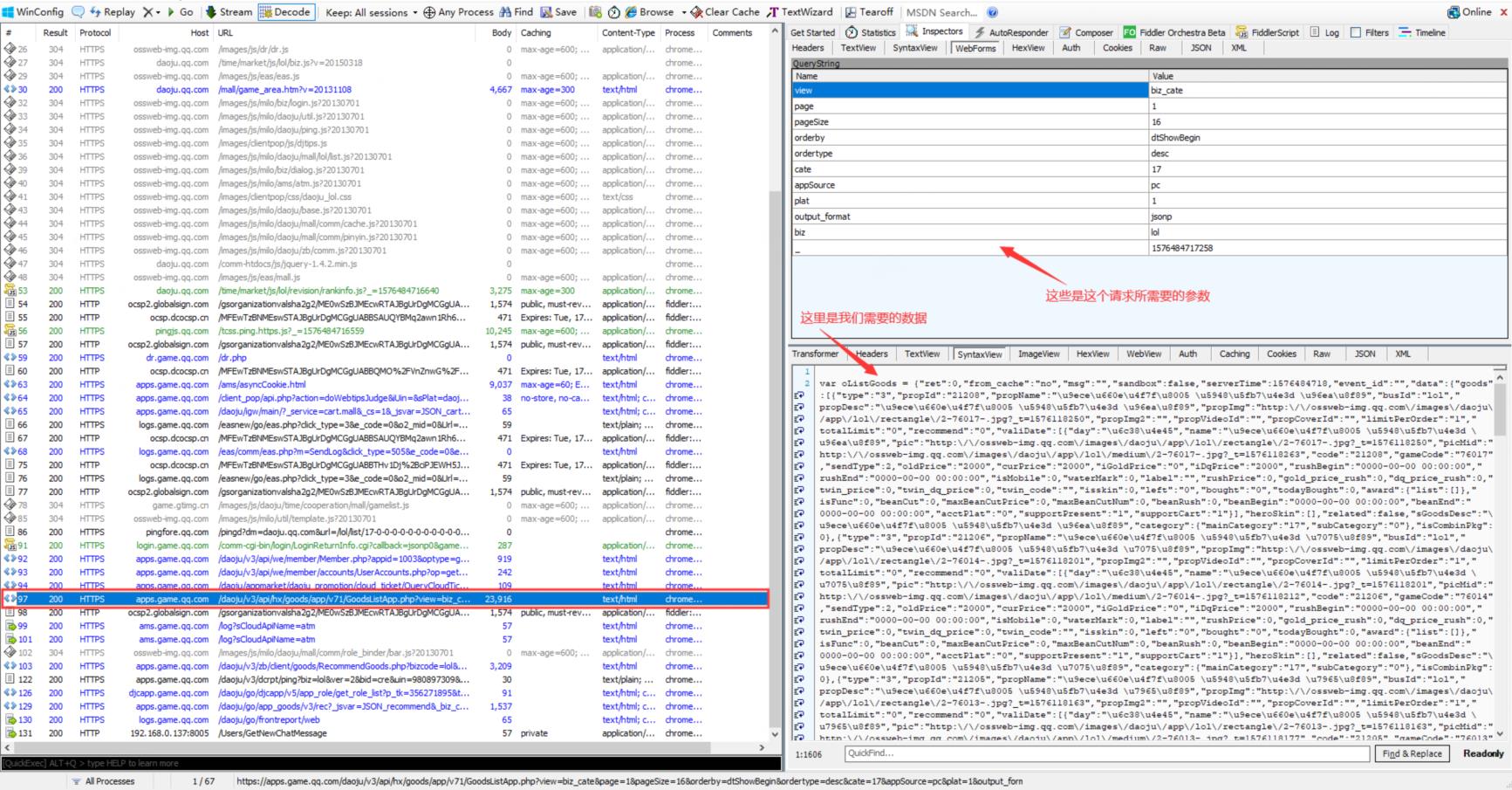
4、解析数据,提取数据
5、保存数据:数据库保存或者文件保存
二、代码示例
1、准备工作:创建一个‘D:\\\\LOL_pic’文件夹,存储数据
下载requests包:py -3.6 -m pip install requests
2、代码编写
import requests import json import time total = 55 # 从网页可以看到有54页 try: for page in range(1,total+1): url = "https://apps.game.qq.com/daoju/v3/api/hx/goods/app/v71/GoodsListApp.php?view=biz_cate&page={}&pageSize=16&orderby=dtShowBegin&ordertype=desc&cate=17&appSource=pc&plat=1&output_format=jsonp&biz=lol&_=1576484717258".format(page) header = {"User-Agent":"使用自己的"} respon = requests.get(url=url, headers=header) content = respon.text # 如果数据是字符串格式使用 .text,如果数据是二进制格式使用 .content,如果数据是JSON格式使用 .json() # print(content) result = content.split("=", 1)[1] # 得到的是一个字符串,把他处理为字典字符串(json),以便转换 data = json.loads(result) # 把数据类型转换为字典 for picture_url in data["data"]["goods"]: img_name = picture_url["propName"] if \'/\' in img_name: img_name = img_name.replace(\'/\', \'-\') # 处理文件名有‘/’的问题 img_url = picture_url["propImg"] picture = requests.get(url=img_url, headers=header).content # 获取图片信息,数据类型是二进制 with open(r\'D:\\LOL_pic\\{}.jpg\'.format(img_name), \'wb\') as f: # 图片使用二进制写 f.write(picture) print("第{}页爬取成功".format(page)) time.sleep(3) # 防止卡死 except Exception as e: print("数据抓取异:{}".format(e)) finally: print("程序执行完毕")
3、执行结果
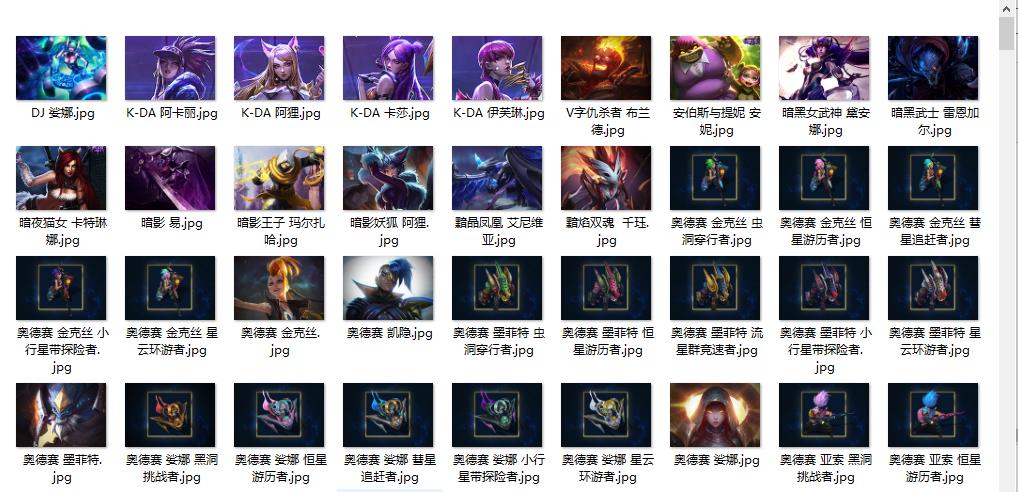
三、python 文件打包
1、安装第三方包:py -3.6 -m pip install pyinstaller
py -3.6 -m pip install cryptography
注意:由于这两个包比较大,请一定保证网速,否则会报错
在安装时遇到的情况如下:

表示超时,网速原因,可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/#genshi网站上去拉取:PyInstaller‑3.5‑py2.py3‑none‑any.whl 这个文件下来,
然后在cmd 执行 py -3.6 -m pip install PyInstaller‑3.5‑py2.py3‑none‑any.whl 命令
因为这两包是多个小包组成的,如果遇到中途有某个包下载不了的情况,可以到上面这个网站去拉取对应的文件下来安装,举个例子:

总之:保证网速会少去很多麻烦
2、在cmd输入命令:pyinstaller -F D:\\test.py # 这个py文件是需要处理成.exe的文件
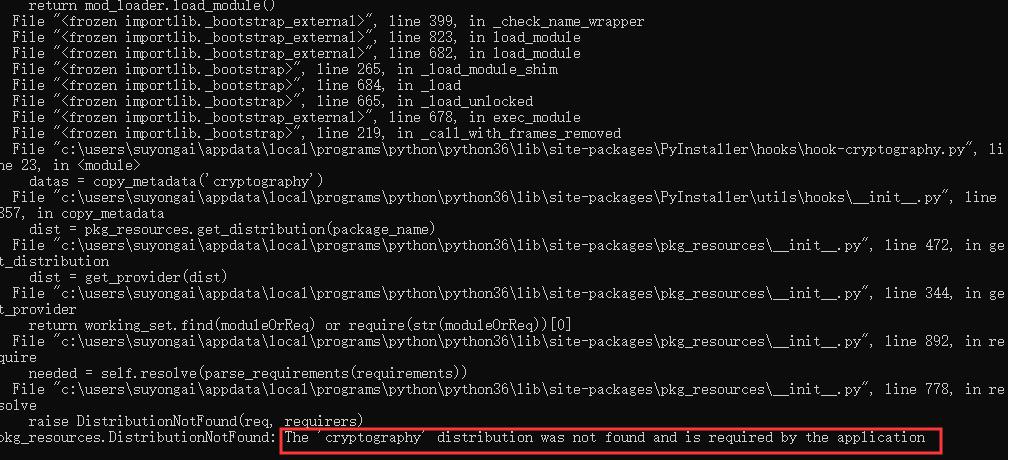
如果在执行的时候遇到下面这个情况,代表你的 cryptography 包未安装或者安装失败导致的,请重新安装
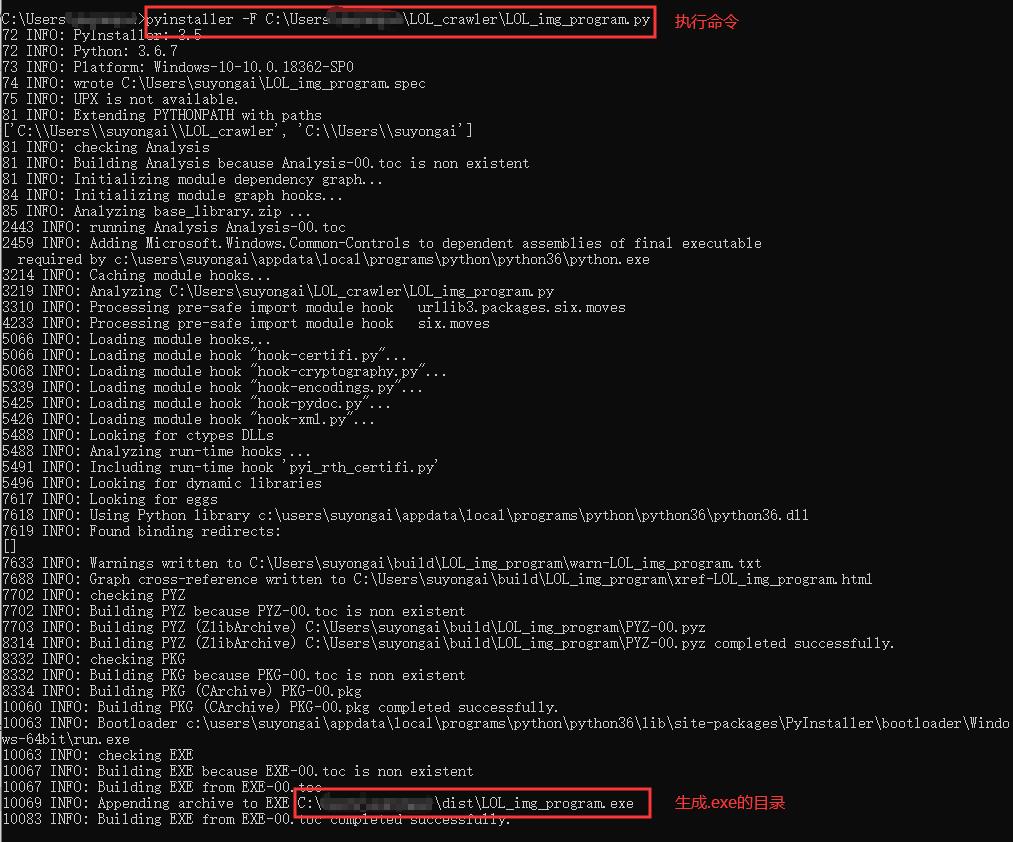
安装成功的图如下所示,请注意生成目录

3、拖至桌面,双击即可运行,如果需要更换图标,操作流程如下所示:
首先:到网上去找一个.ico的图标,免费图标官网的链接 https://www.easyicon.net/
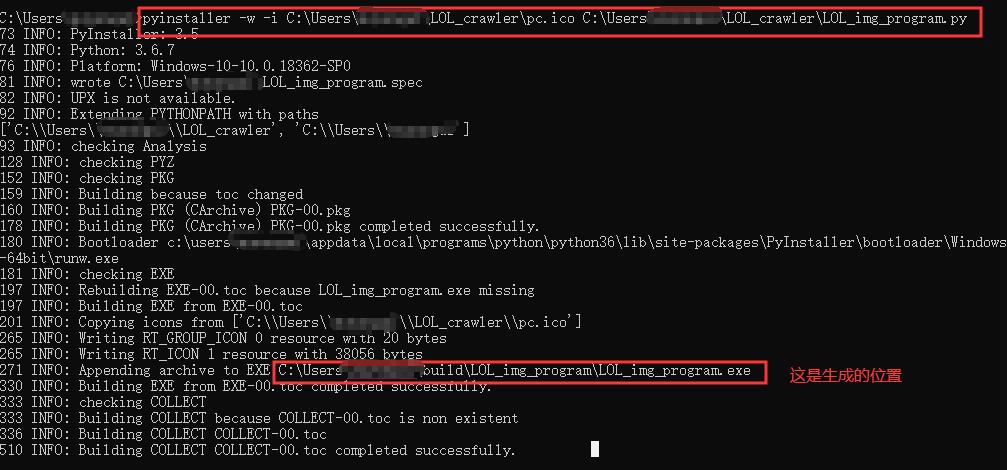
然后:cmd运行命令 pyinstaller -w -i C:\\Users\\xxx\\LOL_crawler\\pc.ico C:\\Users\\xxx\\LOL_crawler\\LOL_img_program.py # 这是绝对路径,用相对路径也是可以的
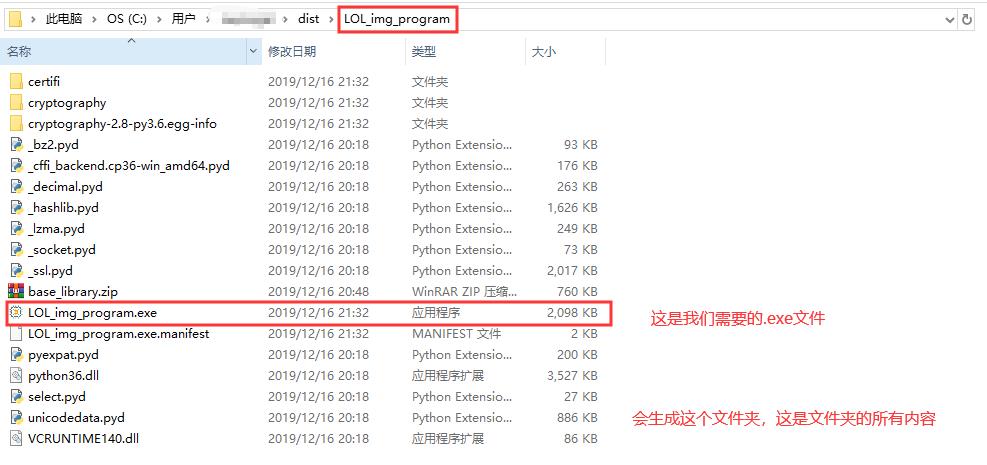
最后:成功后到生成的路径下可看到如下的内容
结束!!!如有疑问请留言!!!
以上是关于爬虫小程序(爬取英雄联盟的英雄皮肤)的主要内容,如果未能解决你的问题,请参考以下文章