上篇丨数据融合平台DataPipeline的应用场景
Posted DataPipeline数见科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了上篇丨数据融合平台DataPipeline的应用场景相关的知识,希望对你有一定的参考价值。

距离2020年还有不到一周的时间,在过去的一年里DataPipeline经历了几次产品迭代。就最新的2.6版本而言,你知道都有哪些使用场景吗?接下来将分为上下篇为大家一 一解读,希望这些场景中能出现你关心的那一款。
场景一:应对生产数据结构的频繁变更场景
1. 场景说明
在同步生产数据时,因为业务关系,源端经常会有删除表,增减字段情况。希望在该情况下任务可以继续同步。并且当源端增减字段时,目的地可以根据设置选择是否同源端一起增减字段。
2. 场景适用说明
源/目的地:关系型数据库
读取模式:不限制
3. 操作步骤
-
不限制DataPipeline版本
-
在DataPipeline的任务设置,数据目的地设置下的高级选项下有【数据源变化设置】选项,可根据提示自行选择

场景二:数据任务结束后调用Jenkins任务
1. 场景说明
数据任务同步结束,立即启动已定义的Jenkins任务。保证执行的顺序性,以及依赖性。
2. 场景适用说明
源/目的地:传统性数据库(其它需要脚本)
读取模式:批量全量或增量识别字段
3. 操作步骤
- 在DataPipeline任务流中创建任务流
- 创建定时数据同步任务
- 添加【远程命令执行】,添加服务器IP,编写python脚本并放置在服务器指定目录
- 详细操作细节请与DataPipeline人员沟通
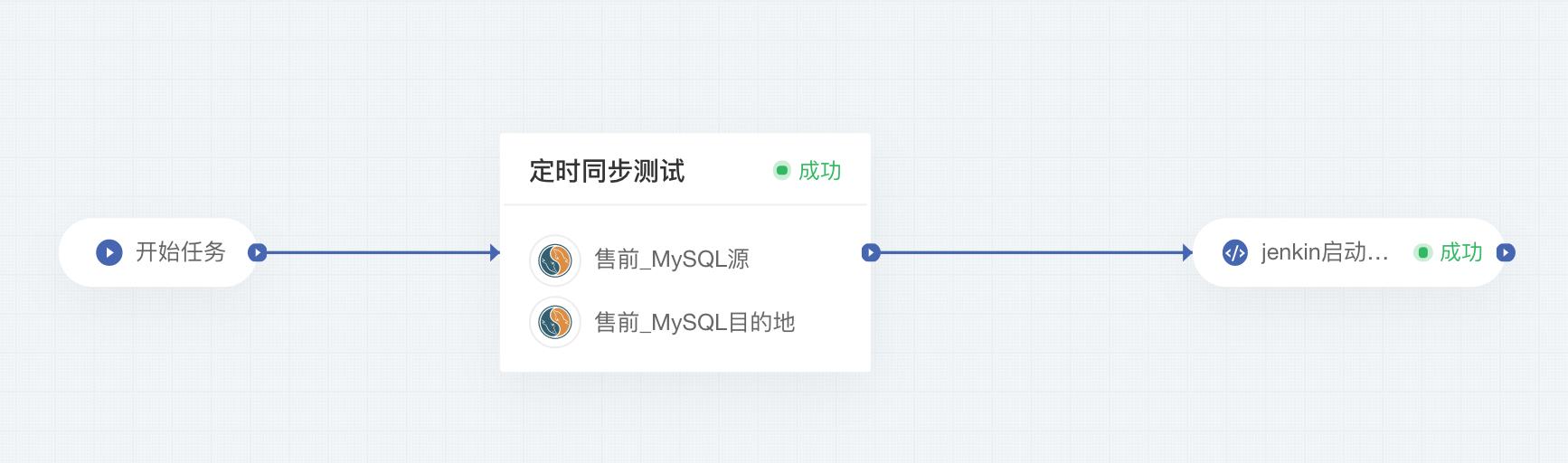
场景三:生产数据同步给测试使用
1. 场景说明
mysql->MySQL实时同步,在同步时,可能测试组想要对任务中的几张表目的地进行测试,在测试过程中,目的地会有INSERT/UPDATE/DELETE操作。希望在测试前,能以自动化方式执行脚本暂停某几张表的同步。测试结束后以自动化方式执行脚本重新同步这几张表,并且目的地数据需要与线上数据保持一致(即测试所产生的脏数据需要被全部清理掉)。
2. 场景适用说明
源/目的地:关系型数据库目的地
读取模式:不限制(全量/增量识别字段模式可能需要开启【每次定时执行批量同步前,允许清除目标表数据】功能)
3. 操作步骤
-
要求DataPipeline版本>=2.6.0
-
在对目的地表进行测试前,执行DataPipeline所提供的脚本
-
目的地结束测试后,再执行脚本添加测试表
-
启动脚本,对测试的几张表进行重新同步,保证测试后的数据可以和线上数据继续保持一致
-
参考DataPipeline swagger接口列表,目前已有脚本模板可供参考
场景四:Hive->GP列存储同步速率提高方案
1. 场景说明
Hive->GP,如果GP目的地表为手动创建的列存储表,那么在DataPipeline上同步时速率会非常慢。这是因为GP列存储本身存在的限制。而目的地若为DataPipeline创建的行表,再通过脚本将行表转换为列表,则效率提高几十倍。
2. 场景适用说明
源/目的地:Hive源/GP目的地
读取模式:增量/全量
3. 操作步骤
-
目的地表为DataPipeline自动创建的行表
-
编写脚本将行表转换为列表
-
数据任务同步完成后,通过DataPipeline任务流调用行转列脚本
-
再将列表数据提供给下游使用
场景五:对数据进行加密脱敏处理场景
1. 场景说明
因为涉及用户隐私或其它安全原因,需要对数据部分字段进行脱敏或加密处理。通过DataPipeline的高级清洗功能可以完全满足此类场景。
2. 场景适用说明
源/目的地:不限制
读取模式:不限制
3. 操作步骤
-
不限制DataPipeline版本
-
正常配置任务即可,只需开启高级清洗功能
-
将已写好的加密代码或脱敏代码打成jar包,上传到服务器执行目录下,直接调用即可
-
高级清洗代码可联系DataPipeline提供模板
注意事项:所写的jar包需要分别上传webservice、sink、manager所在容器的服务器的/root/datapipeline/code_engine_lib(一般默认)目录。
场景六:通过错误队列,明确上下游数据问题责任及原因
1. 场景说明
作为数据部门,需要接收上游数据,并根据下游部门需求将数据传输给对应部门。因此当存在脏数据或者数据问题时,有时很难定位问题原因,划分责任。
并且大多时候都是将脏数据直接丢弃,上游无法追踪脏数据产生的原因。通过DP的高级清洗功能可自定义将不符合的数据放入错误队列中。
2. 场景适用说明
源/目的地:不限制
读取模式:不限制
3. 操作步骤
- 不限制DataPipeline版本
- 正常配置任务即可,只需开启高级清洗功能
- 在高级清洗中对对应字段根据业务进行逻辑判断,将不想要的数据扔到DP错误队列中
- 高级清洗代码可联系DataPipeline提供模板
场景七:更便捷地支持目的地手动增加字段
1. 场景说明
由Oracle->SQLServer,想在目的地手动添加一列TIMESTAMP类型,自动赋予默认值,记录数据INSERT时间。
2. 场景适用说明
源/目的地:关系型数据库目的地
读取模式:不限制
3. 操作步骤
-
要求DataPipeline版本>=2.6.0
-
在DataPipeline映射页面配置时,添加一列,字段名称和目的地手动添加名称一致(标度类型任意给,无需一致)勾选该字段蓝色按钮(开启表示同步该字段数据,关闭表示该字段不传任何数据),点击保存。如下图所示

-
手动在目的地添加该列
本篇将集中介绍以上7种场景,其它应用场景将会在下周发布,如果你在工作中遇到了同样的问题,欢迎与我们交流。
以上是关于上篇丨数据融合平台DataPipeline的应用场景的主要内容,如果未能解决你的问题,请参考以下文章
DataPipeline数据融合重磅功能丨一对多实时分发批量读取模式
DataPipeline丨瓜子二手车基于Kafka的结构化数据流
六种 主流ETL 工具的比较(DataPipeline,Kettle,Talend,Informatica,Datax ,Oracle Goldengate)