〇、一件事儿
以下分析是站在Java工程师的角度来分析的。
一、CPU分析
分析CPU的繁忙程度,两个指标:系统负载和CPU利用率
CPU利用率反映的是CPU被使用的情况,当CPU长期处于被使用而没有得到足够的时间休息间歇,那么对于CPU硬件来说是一种超负荷的运作,需要调整使用频度。而Load Average却从另一个角度来展现对于CPU使用状态的描述,Load Average越高说明对于CPU资源的竞争越激烈,CPU资源比较短缺。对于资源的申请和维护其实也是需要很大的成本,所以在这种高Average Load的情况下CPU资源的长期“热竞争”也是对于硬件的一种损害。
1、系统负载分析
系统负载:在Linux系统中表示,一段时间内正在执行进程数和CPU运行队列中就绪等待进程数,以及非常重要的休眠但不可中断的进程数的平均值(具体load值的计算方式,有兴趣可以自行深究,这里不深究)。说白了就是,系统负载与R(Linux系统之进程状态)和D(Linux系统之进程状态)状态的进程有关,这两个状态的进程越多,负载越高。
查看系统负载,见top命令:第1部分。
-
怎么看load average的值?
通常先看15分钟的load值,如果load很高,再看1分钟和5分钟的load值,查看是否有下降趋势。短时间内load值高,无须太担心;但是如果长时间内load值持续过高,那么就要赶紧看看发生了什么。 -
需要警惕的load average的值(以单核CPU为例):
- load值持续大于0.7,必须开始找问题出在哪里,防止情况恶化;
- load值持续大于1.0,解决问题已迫在眉睫;
- load值持续大升高达到5.0,表示各种请求几乎得不到响应,机器几近崩溃;
对于多核机器,则需要根据CPU个数来判断系统负载是否过高。如,若认为0.7算是单核机器负载的安全线的话,则四核机器的负载最好保持在3(4*0.7 = 2.8)以下。
2、CPU利用率分析
- 看CPU的空闲率,用户进程CPU使用率和系统进程CPU使用率。
- 看个别进程的CPU利用率是否明显高于其他进程:
- 死循环?
- 复杂计算?
- 超大对象耗时读写?
查看CPU利用率,见top命令:第3部分和第5部分。
3、综合两个分析
- CPU利用率高,系统负载低
- 死循环?
- 复杂计算?
- 超大对象耗时读写?
- 系统负载高,CPU利用率低
- 大量进程执行IO操作 -> 中断和上下文切换
- 磁盘IO -> 使用阻塞IO时,进程状态为D
- 网络IO -> 使用阻塞IO时,进程状态为D
- 频繁中断,上下文切换
- 大量进程执行IO操作 -> 中断和上下文切换
- 系统负载高,CPU利用率高
- 大量进程出现死循环?
- 大量进程进行复杂计算?
- 大量进程对超大对象耗时读写?
- 内存不足,频繁GC? -> 硬件无法支撑应用,升级机器?
三、内存分析
- 看总内存的使用情况;
- 是否有个别进程内存消耗明显高?
- JVM内存设置是否合理?
- 是否有大对象长时间未释放?
四、I/O分析
- 如果avgqu-sz比较大,表示相当量的io在等待;
- 如果svctm比较接近await,说明I/O几乎没有等待时间;如果 await远大于svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化;
- 如果%util接近 100%(70%为安全线),说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈;
- 如果I/O存在瓶颈,可以用pidstat命令找到I/O读写高的进程;
查看I/O读写状况,见iostat命令。
五、网络分析
netstat或ss分析:
- 分析连接状态
- 若服务端出现了大量TIME_WAIT状态的连接,说明该服务器经常主动发起连接关闭操作,并且连接还未及时关闭;这一方面会产生大量的无用连接,无故增加tcp的连接数,另一方面就是服务端主动关闭连接也不正常
这种情况可以选择性调优(内核参数修改):
1)net.ipv4.tcp_tw_reuse = 1 # 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
2)net.ipv4.tcp_tw_recycle = 1 # 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
3)另外的办法就是改小tcp_max_tw_buckets,超过这个数的TIME_WAIT都会被干掉,不过这也会导致报time wait bucket table overflow的错
注意:过多的TIME_WAIT在短连接频繁的场景比较容易出现- 若一个系统频繁出现CLOSE_WAIT状态的连接,说明该系统并未立即处理连接关闭请求;这一方面会产生大量的无用连接,无故增加tcp的连接数,另一方面就是服务端可能阻塞了
定位问题,可以先过滤CLOSE_WAIT的连接找到,CLOSE_WAIT连接多的进程,进而通过jstack来分析定位问题
- 分析Send-Q和Recv-Q
Recv-Q:(Established)The count of bytes not copied by the user program connected to this socket. (Listening)Since Kernel 2.6.18 this column contains the current syn backlog.
Send-Q:(Established)The count of bytes not acknowledged by the remote host. (Listening)Since Kernel 2.6.18 this column contains the maximum size of the syn backlog.- Listening状态下分析
下图是TCP三次握手连接过程,其中参杂了一些关键api,具体过程不再赘述
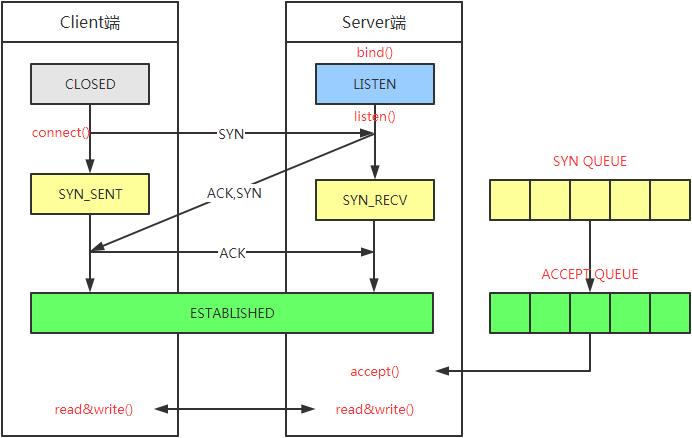
- SYN QUEUE(半连接队列):这个队列的具体值可以不用特别在意,官方帮助文档描述,Listening状态下用netstat命令可以查看,但是实测结果和理论不相符;要想关注这一项看下面的溢出情况统计即可。其值为max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。
若SYN QUEUE溢出,则会报连接超时异常。
- ACCEPT QUEUE(全连接队列):溢出情况也可以通过下面的方法统计,其值为min(backlog,/proc/sys/net/core/somaxconn),其中backlog为创建socket时传入的值。另外,ACCEPT QUEUE队列满了之后可以通过设个参数来改变具体行为
- /proc/sys/net/ipv4/tcp_abort_on_overflow为0:如果三次握手第三步的时候ACCEPT QUEUE满了,那么server扔掉client发过来的ack
- /proc/sys/net/ipv4/tcp_abort_on_overflow为1:如果三次握手第三步的时候ACCEPT QUEUE满了,那么server发送一个RST(reset)包给client,废掉现有的连接,重置连接,意味着日志里可能会有很多 connection reset/connection reset by peer
可以通过
ss -lnt查看具体值,其中Recv-Q为ACCEPT QUEUE的当前值,Send-Q为ACCEPT QUEUE的最大值。如果Recv-Q持续增长,以致大于Send-Q,溢出,说明服务器无法适应当前连接的建立速度,不能及时accept新的连接。

半连接队列和全连接队列的溢出情况可以用
netstat -s | egrep \'listen|LISTEN\'统计:

- SYN QUEUE(半连接队列):这个队列的具体值可以不用特别在意,官方帮助文档描述,Listening状态下用netstat命令可以查看,但是实测结果和理论不相符;要想关注这一项看下面的溢出情况统计即可。其值为max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。
- Established状态(确切说应该是非Listening状态,因为还有其他状态,不过数据传输极少,可以忽略)下分析
- Recv-Q有值,说明应用程序未能及时处理外部发来的请求;
- Send-Q有值,说明应用程序发包速度过快或者对端接收数据包慢,发送数据包未能及时发出,堆积在队列里;
1)这两个值通常应该为0,如果不为0可能是有问题的;数据包在两个队列里都不应该有堆积;可接受短暂的非0情况。
2)用ss和netstat都可以查看,状态为非LISTEN
- Listening状态下分析
- RST(reset)异常分析
RST包表示连接重置,用于关闭一些无用的连接,通常表示异常关闭,区别于四次挥手。在实际开发中,我们往往会看到connection reset/connection reset by peer错误,这种情况就是RST包导致的。- 端口不存在:如果向不存在的端口发出建立连接SYN请求,那么服务端发现自己并没有这个端口则会直接返回一个RST报文,用于中断连接。
- 主动代替FIN终止连接:一般来说,正常的连接关闭都是需要通过FIN报文实现,然而我们也可以用RST报文来代替FIN,表示直接终止连接。实际开发中,可设置SO_LINGER数值来控制,这种往往是故意的,来跳过TIMED_WAIT,提供交互效率,不闲就慎用。
- 客户端或服务端有一边发生了异常,该方向对端发送RST以告知关闭连接:我们上面讲的TCP队列溢出发送RST包其实也是属于这一种。这种往往是由于某些原因,一方无法再能正常处理请求连接了(比如程序崩了,队列满了),从而告知另一方关闭连接。
- 接收到的TCP报文不在已知的TCP连接内:比如,一方机器由于网络实在太差TCP报文失踪了,另一方关闭了该连接,然后过了许久收到了之前失踪的TCP报文,但由于对应的TCP连接已不存在,那么会直接发一个RST包以便开启新的连接。一方长期未收到另一方的确认报文,在一定时间或重传次数后发出RST报文这种大多也和网络环境相关了,网络环境差可能会导致更多的RST报文。
怎么确定有RST包的存在呢?当然是使用tcpdump命令进行抓包,并使用wireshark进行简单分析,见下面
tcpdump分析:
tcpdump通过抓指定端口的数据包,可以分析指定进程的数据包流量。
通过抓包工具tcpdump及网络状态查看命令netstat可以帮助定位客户端、服务端相关网络问题,在日志匮乏或性能统计信息不足以分析服务器问题时,可以辅助分析服务器相关模块性能。
六、磁盘分析
就是线上机器磁盘快满了,看看是否有无用的文件占用磁盘空间。
- df -h,看看磁盘的使用情况
- 看看日志目录,是不是有不需要的
- find / -size +100M | xargs ls -lh,找找大于100M的大文件
- du -h > xx.log,看看各个目录占用磁盘的大小,看看是不是哪个目录有大量的小文件
七、排查思路
- 系统负载、CPU利用率、内存、I/O、网络、磁盘等因素综合考虑,才是解决问题的关键。
- 先整体分析哪块问题,再定位特征进程(例如CPU利用率明显高于其他进程的进程),进而结合jstack定位到线程和代码。