如何高效的监控多台服务器,该做哪些方面的监控?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何高效的监控多台服务器,该做哪些方面的监控?相关的知识,希望对你有一定的参考价值。
这次主要给大家介绍一下从几十台到几千台服务器的运维过程中,监控系统的变迁经历。常说一千个人心中有一千个哈姆雷特,一千个运维的心中有一千种运维的方法,没有一个方法是万能的、可以适用所有的场景,具体问题还得具体分析
一、 服务器数量小于200台的阶段
这个时期一般需要满足基础监控需求,我们主要考虑的是简单易用、 稳定运行、 监控报警三个方面。
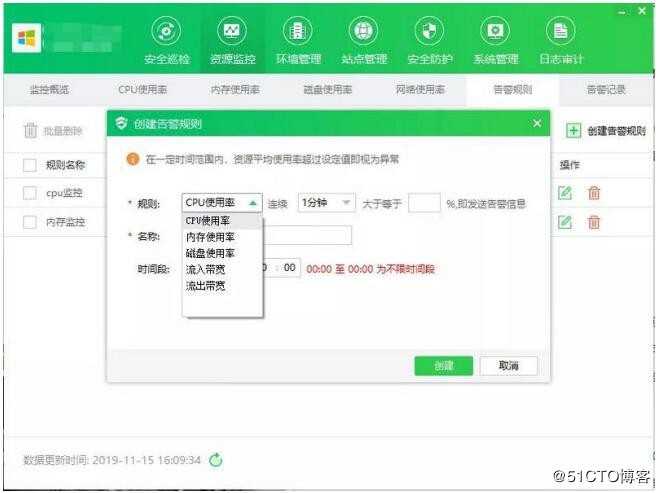
云帮手资源监控系统全程可视化界面,一键傻瓜式操作,新手小白也能快速上手;能够从CPU、内存、磁盘、网络四个方面对服务器进行24小时不间断基础监控,并可自主设置告警规则,在状态异常时第一时间产生告警,帮助用户快速定位问题解决问题。
二、服务器数量200到1000的阶段
随着服务器数量的增加,用户需求开始变得复杂,我们需要做到以下几点:
统一监控内容:云帮手将基础监控进行统一,默认每个机器都包含CPU,内存,磁盘空间等基础信息监控。
覆盖式监控:云帮手支持多IP服务器纳入监控,所有服务器统一可视化管理,功能覆盖整个业务流程,避免多系统繁杂管理,保障业务高效运行。
及时通知,确保无漏报:云帮手会在系统触发告警规则后第一时间产生告警,且告警记录可查询,坚决做到不迟报不漏报。
三、服务器数量超过1000台的阶段
需要监控的服务器越来越多,告警信息出现爆发式增长,每天收到上千条报警信息。我们需要将告警进行整理,化繁为简,减少重复告警。
分离告警和显示:云帮手将CPU使用率、内存使用率、磁盘使用率等各监控模块进行告警规则独立设置,告警时间段分离推送,告警记录分离展示。重要的告警处理是分秒必争的,云帮手能够效避免同一时间重复告警、影响运维效率。
快速定位、及时分析:云帮手针对每个服务器进行独立可视化管理,我们根据告警推送快速查看到哪里流量达到了预警值,哪个服务器出现了问题,方便运维人员及时解决,并根据告警记录进行分析,避免同样问题的发生。
最后贴个下载地址(云帮手),希望能帮助到您!
以上是关于如何高效的监控多台服务器,该做哪些方面的监控?的主要内容,如果未能解决你的问题,请参考以下文章