1、ES基本操作
Elasticsearch的概念
-
索引 ->类似于mysql中的数据库
-
类型 ->类似于Mysql中的数据表
-
文档 ->存储数据
ES&kibana
测试Web接口
-
浏览器访问
-
Kibana操作:
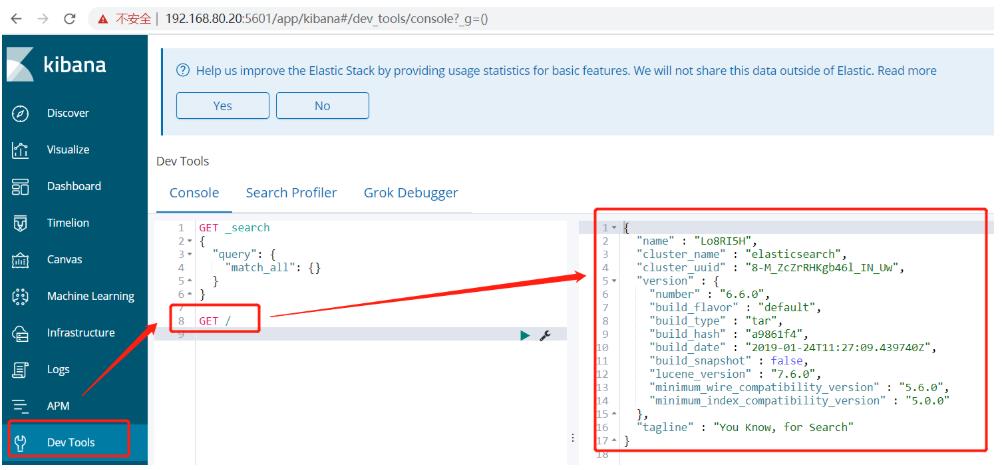
GET /出现下图所示的效果,说明kibana和ES联动成功。
索引操作
//创建索引
PUT /zhang
//删除索引:
DELETE /zhang
//获取所有索引:
GET /_cat/indices?v
增删改查
ES插入数据
PUT /zhang/users/1
{
"name":"zhanghe",
"age": 23
}
ES查询数据
GET /zhang/users/1
GET /zhang/_search?q=*
修改数据、覆盖
PUT /zhang/users/1
{
"name": "justdoit",
"age": 21
}
ES删除数据
DELETE /zhang/users/1
修改某个字段、不覆盖
POST /zhang/users/1/_update
{
"doc": {
"age": 22
}
}
修改所有的数据
POST /zhang/_update_by_query
{
"script": {
"source": "ctx._source[\'age\']=30"
},
"query": {
"match_all": {}
}
}
增加一个字段
POST /zhang/_update_by_query
{
"script":{
"source": "ctx._source[\'city\']=\'hangzhou\'"
},
"query":{
"match_all": {}
}
}
我们运维人员操作时并不会大量的使用上述方法,大多数只要知道即可。
3、nginx
自定义提取字段
nginx的日志在kibana上显示是一整条,没有切割,我们要通过正表达式来对nginx的日志进行切割,要求我们熟悉正则表达式和nginx的日志内容,这些都是基础内容,这些不再赘述。
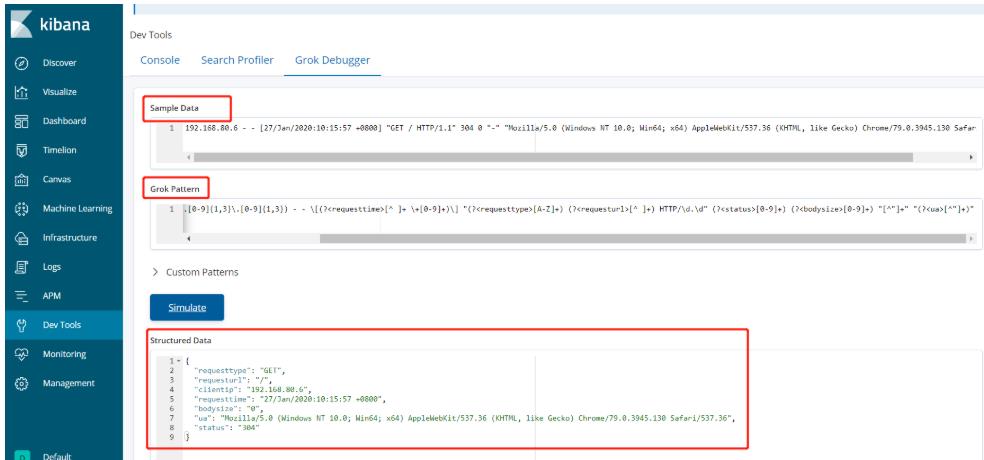
Grok提取Nginx日志
1、 Grok使用(?
2、 提取客户端IP: (?
3、 提取时间: [(?
Grok提取Nginx日志
(?<clientip>[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}) - - \\[(?<requesttime>[^ ]+ \\+[0-9]+)\\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\\d.\\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"
提取Tomcat等日志使用类似的方法
Logstash正则提取Nginx日志
input {
file {
path => "/var/log/nginx/access.log"
}
}
filter {
grok {
match => {
"message" => \'(?<clientip>[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}) - - \\[(?<requesttime>[^ ]+ \\+[0-9]+)\\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\\d.\\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"\'
}
}
}
output {
elasticsearch {
hosts => ["http://192.168.80.20:9200"]
}
}
Logstash正则提取出错就不输出到ES
echo "shijiange" >> /usr/local/nginx/logs/access.log
output{
if "_grokparsefailure" not in [tags] and "_dateparsefailure" not in [tags] {
elasticsearch {
hosts => ["http://192.168.237.50:9200"]
}
}
}
效果截图如下,多了很多自定义的字段:
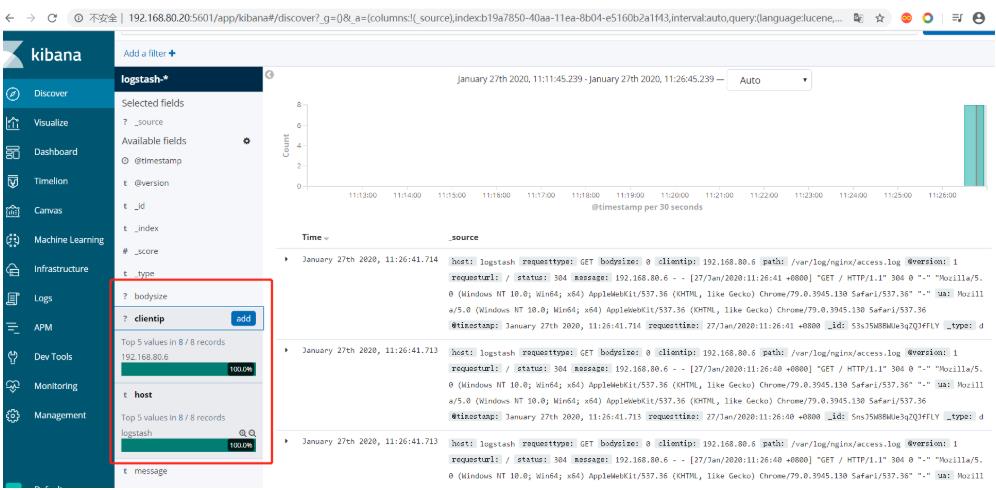
去除字段
我们在logstash的配置文件当中把message的字段都给拆分完了,而ES端不需要再把完整的message信息存储下来了,我们就可以将其去除。
去除字段注意
-
只能去除_source里的
-
非_source里的去除不了
Logstash配置去除不需要的字段
filter {
grok {
match => {
"message" => \'(?<clientip>[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}) - - \\[(?<requesttime>[^ ]+ \\+[0-9]+)\\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\\d.\\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"\'
}
remove_field => ["message","@version","path"]
}
}
去除字段的好处:
减小ES数据库的大小
提升搜索效率
时间轴
默认ELK时间轴
-
以发送日志的时间为准
-
而Nginx上本身记录着用户的访问时间
-
分析Nginx上的日志以用户的访问时间为准,而不以发送日志的时间
Logstash默认是只是会记录最新出现的的日志,以往的日志并不会发送到ES上,但是如果我们有这个需求,要进行一个全量的分析,也是可以的:
input {
file {
path => "/usr/local/nginx/logs/access.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
记录日志的时间和日志发送到ES的时候是不一致的,而kibana只会根据发送的发送的时间呈现图表,这不方便我们观看,所以我们要用日志里面的时间覆盖日志发送到ES的时间,这样图表呈现出来时才符合我们的需求。
Logstash的filter里面加入配置24/Feb/2019:21:08:34 +0800
filter {
grok {
match => {
"message" => \'(?<clientip>[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}) - - \\[(?<requesttime>[^ ]+ \\+[0-9]+)\\] "(?<requesttype>[A-Z]+) (?<requesturl>[^ ]+) HTTP/\\d.\\d" (?<status>[0-9]+) (?<bodysize>[0-9]+) "[^"]+" "(?<ua>[^"]+)"\'
}
remove_field => ["message","@version","path"]
}
date {
match => ["requesttime", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
统计Nginx的请求和网页显示进行对比
cat /usr/local/nginx/logs/access.log |awk \'{print $4}\'|cut -b 1-19|sort |uniq -c
不同的时间格式,覆盖的时候格式要对应
20/Feb/2019:14:50:06 -> dd/MMM/yyyy:HH:mm:ss
2016-08-24 18:05:39,830 -> yyyy-MM-dd HH:mm:ss,SSS