Linux core dump文件生成与使用
Posted 诸子流
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux core dump文件生成与使用相关的知识,希望对你有一定的参考价值。
一、说明
在前一家公司经常测出一些缓冲区溢出导致进程挂掉的问题,开发经常要求在调试模式进行测试,生成core文件给他们定位问题。
当时的调试模式启动只是修改某些配置文件重新启动即可,所以在很长一段时间内并不知道到底要如何生成core文件及core文件如何使用。
二、配置允许生成core文件
临时配置使用ulimit命令进行操作即可:
# 查看当前用户core文件配置情况 # 0表示允许core文件大小为0,亦即不允许生成 ulimit -c # 限制core文件大小 # 禁止生成core文件 ulmit -c 0 # 限制core文件大小100块 ulimit -c 100 # 不限制core文件大小 ulimit -c unlimited
要永久生效则修改配置文件/etc/security/limits.conf,使用类似如下形式进行配置:
* soft core unlimited
三、直接的core文件生成
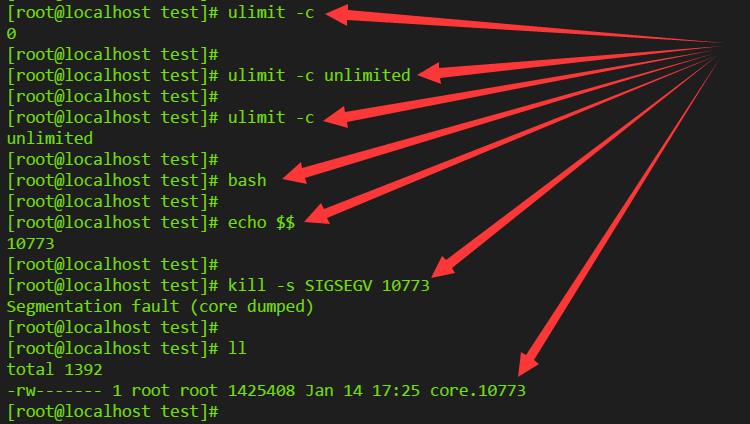
3.1 通过kill触发生成
# 查看当前core文件大小限制
ulimit -c
# 设置成不限制大小
ulimit -c unlimited
# 再次查看core文件大小限制
ulimit -c
# 新启动一个bash进程
bash
# 查看当前bash的pid
echo $$
# 将该进程kill掉,触发core文件生成
kill -s SIGSEGV $$
# 确认core文件确实已经生成
ll
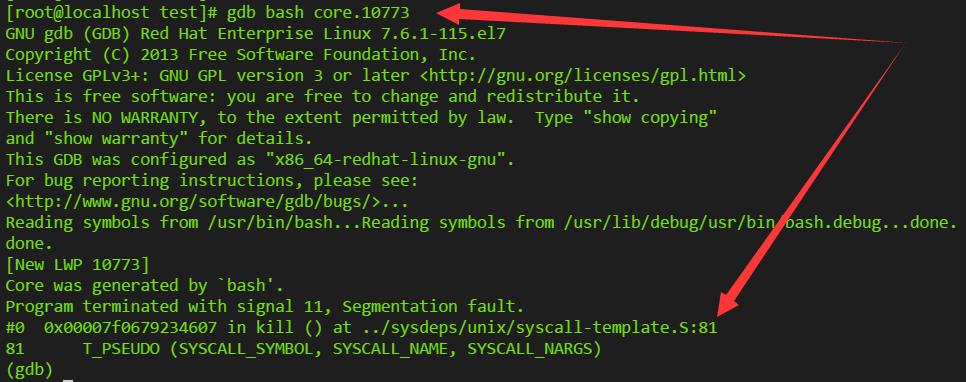
使用gdb查看core文件即可定位到出错行,如下图。
3.2 使用gdb直接生成
# 查看当前bash的pid echo $$ # 通过pid进行gdb调试。为了通用性这里直接使用$$ gdb -p $$ # 生成core文件。在gdb内部输入 generate-core-file # 退出gdb。在gdb内部输入 quit # 确认退出gdb。在gdb内部输入 y # 确认当前目录下有core文件生成 ls -l | grep $$
3.3 使用gcore生成
# 直接生成当前bash进程的core文件 gcore $$ # 确认core文件已在当前目录下生成 ls -l | grep $$

四、自己代码中core文件的使用
第三大节中介绍的几种方法是可以生成core文件,但是像bash这些程序在编译时并没有汇入源代码,所以要定位代码也只能定位到汇编语句定位不到源代码语句。
而对于开发而言,使用core文件的主要目的是为了分析定位程序运行出错的代码位置(然后在此基础上分析出错的原因)。我们这里就以一个简单的C程序进行演示。
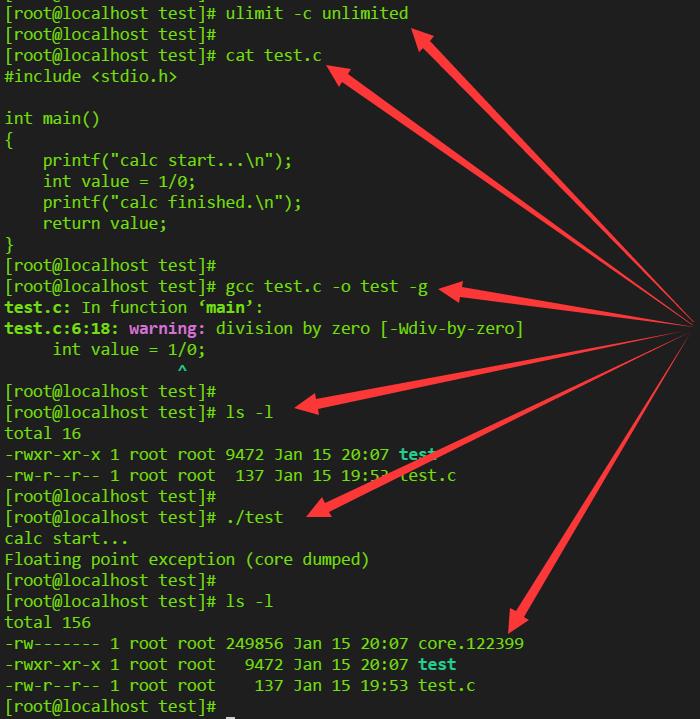
将以下代码保存成test.c:
#include <stdio.h> int main() { printf("calc start...\\n"); int value = 1/0; printf("calc finished.\\n"); return value; }
生成core文件并调试:
# 设置core文件大小限制 ulimit -c unlimited # 编译文件。-g将源代码附加到生成的二进制文件中,这样后边gdb定位出错位置时才能显示源代码行 gcc test.c -o test -g # 查看当前文件 ls -l # 执行程序触发生成core文件 ./test # 查看确认core文件生成 ls -l # 使用gdb进行调试。第一个参数是生成core文件的可执行程序,第二个参数是生成的core文件 gdb test core.xxx
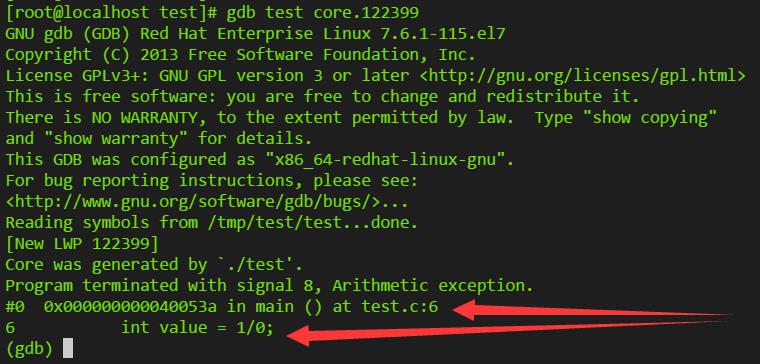
可以看到可以直接定位到导致出错的代码处:
参考:
https://linux-audit.com/understand-and-configure-core-dumps-work-on-linux/
以上是关于Linux core dump文件生成与使用的主要内容,如果未能解决你的问题,请参考以下文章