Table API
Flink API总览
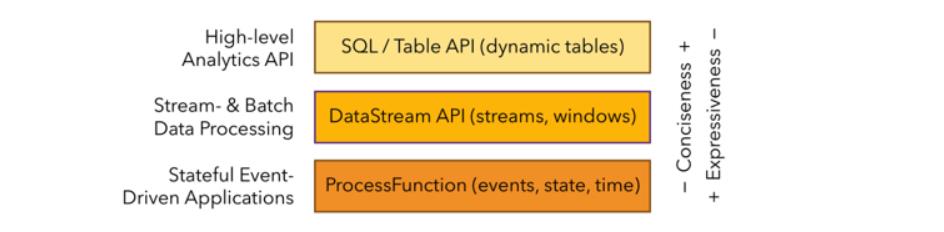
如图,Flink 根据使用的便捷性和表达能力的强弱提供了 3 层 API,由上到下,表达能力逐渐增强,比如 processFunction,是最底层的 API,表达能力最强,我们可以用他来操作 state 和 timer 等复杂功能。Datastream API 相对于 processFunction 来说,又进行了进一步封装,提供了很多标准的语义算子给大家使用,比如我们常用的 window 算子(包括 Tumble, slide,session 等)。那么最上面的 SQL 和 Table API 使用最为便捷,具有自身的很多特点,重点归纳如下:
-
第一,Table API & SQL 是一种声明式的 API。用户只需关心做什么,不用关心怎么做,比如图中的 WordCount 例子,只需要关心按什么维度聚合,做哪种类型的聚合,不需要关心底层的实现。
-
第二,高性能。Table API & SQL 底层会有优化器对 query 进行优化。举个例子,假如 WordCount 的例子里写了两个 count 操作,优化器会识别并避免重复的计算,计算的时候只保留一个 count 操作,输出的时候再把相同的值输出两遍即可,以达到更好的性能。
-
第三,流批统一。上图例子可以发现,API 并没有区分流和批,同一套 query 可以流批复用,对业务开发来说,避免开发两套代码。
-
第四,标准稳定。Table API & SQL 遵循 SQL 标准,不易变动。API 比较稳定的好处是不用考虑 API 兼容性问题。
-
第五,易理解。语义明确,所见即所得。
Table API 特性
第一,Table API 使得多声明的数据处理写起来比较容易。
怎么理解?比如我们有一个 Table(tab),并且需要执行一些过滤操作然后输出到结果表,对应的实现是:tab.where(“a < 10”).inertInto(“resultTable1”);此外,我们还需要做另外一些筛选,然后也对结果输出,即 tab.where(“a > 100”).insertInto(“resultTable2”)。你会发现,用 Table API 写起来会非常简洁方便,两行代码就把功能实现了。
第二,Table API 是 Flink 自身的一套 API,这使得我们更容易地去扩展标准的 SQL。当然,在扩展 SQL 的时候并不是随意的去扩展,需要考虑 API 的语义、原子性和正交性,并且当且仅当需要的时候才去添加。
对比 SQL,我们可以认为 Table API 是 SQL 的超集。SQL 有的操作,Table API 可以有,然而我们又可以从易用性和功能性地角度对 SQL 进行扩展和提升。
接下来将构建连续的 ETL 流水线,以便按账户随时跟踪金融交易。 首先你将报表构建为每晚执行的批处理作业,然后迁移到流式管道。
Table API编程
/**
* 这两行设置运行环境
* 由于创建的是一个定时的批处理报告,所以以批处理环境作为开始
* 然后将其包装进BatchTableEnvironment中从而能够使用所有的Tabel API
*/
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);
/**
* 注册表
* 表将会被注册到运行环境中,这样就可以用它们连接外部系统以读取/写入批数据或流数据
* source提供对存储在外部系统中的数据的访问;例如数据库、键-值存储、消息队列或文件系统
* sink则将表中的数据发送到外部存储系统
* 根据source或sink的类型,它们支持不同的格式,如CSV、JSON、Avro或Parquet
*
* 这里注册了两张表,交易标作为输入表,支出报告表作为输出表
*/
tEnv.registerTableSource("transactions", new BoundedTransactionTableSource());
tEnv.registerTableSink("spend_report", new SpendReportTableSink());
/**
* 注册UDF
* 一个用来处理时间戳的自定义函数随表一起被注册到tEnv中
* 此函数将时间戳向下舍入到最接近的小时
*/
tEnv.registerFunction("truncateDateToHour", new TruncateDateToHour());
/**
* 查询
* 从TableEnvironment中,scan一个输入表读取其中的行,然后用insertInto把这些数据写到输出表中
* 通过 scan 刚才注册好的 TableSource,我们可以拿到一个 Table 对象,并执行相应的一些操作,比如 GroupBy,count。
*/
tEnv
.scan("transactions")
.insertInto("spend_report");
env.execute("Spend Report");
尝试一下
现在有了作业设置的框架,你就可以添加一些业务逻辑了。 目标是建立一个报表来显示每天每小时每个账户的总支出。 就像一个 SQL 查询一样,Flink 可以选取所需的字段并且按键分组。 由于时间戳字段具有毫秒的粒度,你可以使用自定义函数将其舍入到最近的小时。 最后,选取所有的字段,用内建的 sum 聚合函数函数合计每一个账户每小时的支出。
tEnv
.scan("transactions")
.select("accountId, timestamp.truncateDateToHour as timestamp, amount")
.groupBy("accountId, timestamp")
.select("accountId, timestamp, amount.sum as total")
.insertInto("spend_report");
这个查询处理了transactions表中的所有记录,计算报告,并以高效、可扩展的方式输出结果。
# 查询 1 的输出显示了账户 id、时间戳和消费总额。
> 1, 2019-01-01 00:00:00.0, $567.87
> 2, 2019-01-01 00:00:00.0, $726.23
> 1, 2019-01-01 01:00:00.0, $686.87
> 2, 2019-01-01 01:00:00.0, $810.06
> 1, 2019-01-01 02:00:00.0, $859.35
> 2, 2019-01-01 02:00:00.0, $458.40
> 1, 2019-01-01 03:00:00.0, $330.85
> 2, 2019-01-01 03:00:00.0, $730.02
> 1, 2019-01-01 04:00:00.0, $585.16
> 2, 2019-01-01 04:00:00.0, $760.76
添加窗口
根据时间进行分组在数据处理中是一种很常见的方式,特别是在处理无限的数据流时。 基于时间的分组称为窗口 ,Flink 提供了灵活的窗口语义。 其中最基础的是 Tumble window(滚动窗口),它具有固定大小且窗口之间不重叠。
tEnv
.scan("transactions")
.window(Tumble.over("1.hour").on("timestamp").as("w"))
.groupBy("accountId, w")
.select("accountId, w.start as timestamp, amount.sum")
.insertInto("spend_report");
你的应用将会使用基于时间戳字段的一小时的滚动窗口。 因此时间戳是 2019-06-01 01:23:47 的行被放入 2019-06-01 01:00:00 这个时间窗口之中。
在持续的流式应用中,基于时间的聚合结果是唯一的,因为相较于其他属性,时间通常会向前移动。 在批处理环境中,窗口提供了一个方便的API,用于按时间戳属性对记录进行分组。
运行这个更新过的查询将会得到和之前一样的结果。
# 查询 2 的输出显示了账户 id、时间戳和消费总额
> 1, 2019-01-01 00:00:00.0, $567.87
> 2, 2019-01-01 00:00:00.0, $726.23
> 1, 2019-01-01 01:00:00.0, $686.87
> 2, 2019-01-01 01:00:00.0, $810.06
> 1, 2019-01-01 02:00:00.0, $859.35
> 2, 2019-01-01 02:00:00.0, $458.40
> 1, 2019-01-01 03:00:00.0, $330.85
> 2, 2019-01-01 03:00:00.0, $730.02
> 1, 2019-01-01 04:00:00.0, $585.16
> 2, 2019-01-01 04:00:00.0, $760.76
通过流处理的方式再来一次
因为 Flink 的 Table API 为批处理和流处理提供了相同的语法和语义,从一种方式迁移到另一种方式只需要两步。
第一步是把批处理的 ExecutionEnvironment 替换成流处理对应的 StreamExecutionEnvironment,后者创建连续的流作业。 它包含特定于流处理的配置,比如时间特性。当这个属性被设置成 事件时间时,它能保证即使遭遇乱序事件或者作业失败的情况也能输出一致的结果。 滚动窗口在对数据进行分组时就运用了这个特性。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
第二步就是把有界的数据源替换成无限的数据源, 在实践中,这个表可能从一个流式数据源中读取数据,比如Apache Kafka。
tEnv.registerTableSource("transactions", new UnboundedTransactionTableSource());
# 查询 3 的输出显示了账户 id、时间戳消费总额
> 1, 2019-01-01 00:00:00.0, $567.87
> 2, 2019-01-01 00:00:00.0, $726.23
# 这些行是在这一小时中连续计算的
# 并在这一小时结束时立刻输出
> 1, 2019-01-01 01:00:00.0, $686.87
> 2, 2019-01-01 01:00:00.0, $810.06
# 当接收到该窗口的第一条数据时
# Flink 就开始计算了
最终程序
package spendreport;
import org.apache.flink.walkthrough.common.table.SpendReportTableSink;
import org.apache.flink.walkthrough.common.table.TransactionTableSource;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.java.StreamTableEnvironment;
public class SpendReport {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
tEnv.registerTableSource("transactions", new UnboundedTransactionTableSource());
tEnv.registerTableSink("spend_report", new SpendReportTableSink());
tEnv
.scan("transactions")
.window(Tumble.over("1.hour").on("timestamp").as("w"))
.groupBy("accountId, w")
.select("accountId, w.start as timestamp, amount.sum")
.insertInto("spend_report");
env.execute("Spend Report");
}
}
另外再举个wordcount的例子:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.BatchTableEnvironment;
import org.apache.flink.table.descriptors.FileSystem;
import org.apache.flink.table.descriptors.OldCsv;
import org.apache.flink.table.descriptors.Schema;
import org.apache.flink.types.Row;
public class JavaBatchWordCount {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);
String path = JavaBatchWordCount.class.getClassLoader().getResource("words.txt").getPath();
tEnv.connect(new FileSystem().path(path))
.withFormat(new OldCsv().field("word", Types.STRING).lineDelimiter("\\n"))
.withSchema(new Schema().field("word", Types.STRING))
.registerTableSource("fileSource");
Table result = tEnv.scan("fileSource")
.groupBy("word")
.select("word, count(1) as count");
tEnv.toDataSet(result, Row.class).print();
}
}
Table 操作
Table 操作概览
Table 上有很多操作,比如一些 projection 操作 select、filter、where;聚合操作,如 groupBy、flatAggrgate;还有join操作,等等。我们以一个具体的例子来介绍下 Table 上各操作的转换流程。
如上图,当我们拿到一个 Table 后,调用 groupBy 会返回一个 GroupedTable。GroupedTable 里只有 select 方法,对 GroupedTable 调用 select 方法会返回一个 Table。拿到这个 Table 后,我们可以再调用 Table 上的方法。图中其他 Table,如 OverWindowedTable 也是类似的流程。值得注意的是,引入各个类型的 Table 是为了保证 API 的合法性和便利性,比如 groupBy 之后只有 select 操作是有意义的,在编辑器上可以直接点出来。
前面我们提到,可以将 Table API 看成是 SQL 的超集,因此我们也可以对 Table 里的操作按此进行分类,大致分为三类,如下图所示:
- 第一类,是跟 SQL 对齐的一些操作,比如 select, filter, join 等。
- 第二类,是一些提升 Table API 易用性的操作。
- 第三类,是增强 Table API 功能的一些操作。
第一类操作由于和 SQL 类似,比较容易理解,其次,也可以查看官方的文档,了解具体的方法。 后两类操作是 Table API 独有的。
提升易用性相关操作
我们先来看一个问题。 假设我们有一张很大的表,里面有一百列,此时需要去掉一列,那么SQL怎么写?
我们需要 select 剩下的 99 列!显然这会给用户带来不小的代价。为了解决这个问题,我们在Table上引入了一个 dropColumns 方法。利用 dropColumns 方法,我们便可以只写去掉的列。与此对应,还引入了 addColumns, addOrReplaceColumns 和 renameColumns 方法,如下图所示:
解决了刚才的问题后,我们再看下面另一个问题:假设还是一张100列的表,我们需要选第20到第80列,那么我们如何操作呢?为了解决这个问题,我们又引入了 withColumns 和 withoutColumns 方法。对于刚才的问题,我们可以简单地写成 table.select(“withColumns(20 to 80)”)。
增强功能相关操作
该小节会介绍下 TableAggregateFunction 的功能和用法。在引入 TableAggregateFunction 之前,Flink 里有三种自定义函数:ScalarFunction,TableFunction 和 AggregateFunction。我们可以从输入和输出的维度对这些自定义函数进行分类。如下图所示,ScalarFunction 是输入一行,输出一行;TableFunction 是输入一行,输出多行;AggregateFunction 是输入多行输出一行。为了让语义更加完整,Table API 新加了 TableAggregateFunction,它可以接收和输出多行。TableAggregateFunction 添加后,Table API 的功能可以得到很大的扩展,某种程度上可以用它来实现自定义 operator。比如,我们可以用 TableAggregateFunction 来实现 TopN。
TableAggregateFunction 使用也很简单,方法签名和用法如下图所示:
用法上,我们只需要调用 table.flatAggregate(),然后传入一个 TableAggregateFunction 实例即可。用户可以继承 TableAggregateFunction 来实现自定义的函数。继承的时候,需要先定义一个 Accumulator,用来存取状态,此外自定义的 TableAggregateFunction 需要实现 accumulate 和 emitValue 方法。accumulate 方法用来处理输入的数据,而 emitValue 方法负责根据 accumulator 里的状态输出结果