Nginx反爬虫: 禁止某些User Agent抓取网站
Posted 爱你爱自己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Nginx反爬虫: 禁止某些User Agent抓取网站相关的知识,希望对你有一定的参考价值。
1、在/usr/local/nginx/conf目录下(因Nginx的安装区别,可能站点配置文件的路径有所不同)新建文件deny_agent.config配置文件:

#forbidden Scrapy
if ($http_user_agent ~* (Scrapy|Curl|HttpClient))
{
return 403;
}
#forbidden UA
if ($http_user_agent ~ "Bytespider|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|^$" )
{
return 403;
}
#forbidden not GET|HEAD|POST method access
if ($request_method !~ ^(GET|HEAD|POST)$)
{
return 403;
}
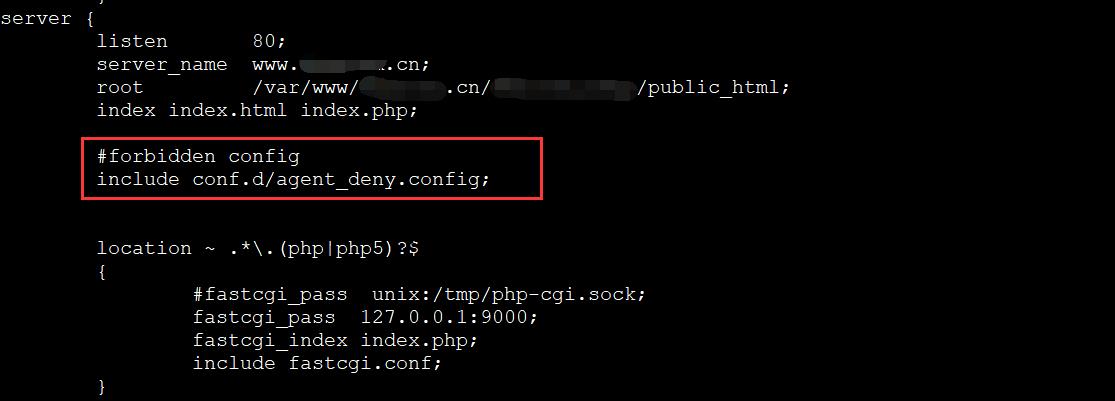
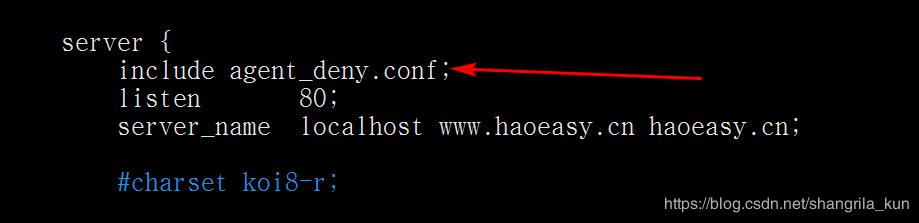
2、在对应站点配置文件中包含deny_agent.config配置文件(注意是在server里面):
3、重启Nginx,建议通过nginx -s reload平滑重启的方式。重启之前请先使用nginx -t命令检测配置文件是否正确。
4、通过curl命令模拟访问,看配置是否生效(返回403 Forbidden,则表示配置OK):

附录:UA收集
FeedDemon 内容采集 BOT/0.1 (BOT for JCE) sql注入 CrawlDaddy sql注入 Java 内容采集 Jullo 内容采集 Feedly 内容采集 UniversalFeedParser 内容采集 ApacheBench cc攻击器 Swiftbot 无用爬虫 YandexBot 无用爬虫 AhrefsBot 无用爬虫 YisouSpider 无用爬虫(已被UC神马搜索收购,此蜘蛛可以放开!) jikeSpider 无用爬虫 MJ12bot 无用爬虫 ZmEu phpmyadmin 漏洞扫描 WinHttp 采集cc攻击 EasouSpider 无用爬虫 HttpClient tcp攻击 Microsoft URL Control 扫描 YYSpider 无用爬虫 jaunty wordpress爆破扫描器 oBot 无用爬虫 Python-urllib 内容采集 Indy Library 扫描 FlightDeckReports Bot 无用爬虫 Linguee Bot 无用爬虫
#添加如下内容即可防止爬虫
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou spider|Sogou web spider|MSNBot|ia_archiver|Tomato Bot")
{
return 403;
}
#禁止Scrapy等工具的抓取
if ($http_user_agent ~* (Scrapy|Curl|HttpClient)) {
return 403;
}
#禁止指定UA及UA为空的访问
if ($http_user_agent ~ "WinHttp|WebZIP|FetchURL|node-superagent|java/|
FeedDemon|Jullo|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|
CrawlDaddy|Java|Feedly|Apache-HttpAsyncClient|UniversalFeedParser|ApacheBench|
Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|
lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|BOT/0.1|
YandexBot|FlightDeckReports|Linguee Bot|^$" ) {
return 403;
}
限制搜索引擎爬虫频率
#全局配置
limit_req_zone $anti_spider zone=anti_spider:10m rate=15r/m;
#某个server中
limit_req zone=anti_spider burst=30 nodelay;
if($http_user_agent ~ "WinHttp|WebZIP|FetchURL|node-superagent|java/|FeedDemon|Jullo|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|Java|Feedly|Apache-HttpAsyncClient|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms|BOT/0.1|YandexBot|FlightDeckReports|Linguee Bot|^$" ) {
set $anti_spider $http_user_agent;
}
以上是关于Nginx反爬虫: 禁止某些User Agent抓取网站的主要内容,如果未能解决你的问题,请参考以下文章