kafka API
Posted hdc520
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka API相关的知识,希望对你有一定的参考价值。
(1)Producer的API
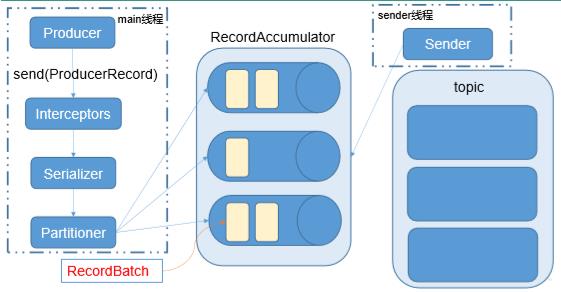
1、发送流程:Kafka 的 Producer 发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程,以及一个线程共享变量——RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka broker。 如下图所示;
batch.size:只有数据积累到 batch.size 之后,sender 才会发送数据。
linger.ms:如果数据迟迟未达到 batch.size,sender 等待 linger.time 之后就会发送数据。
ProducerRecord:每条数据都要封装成一个ProducerRecord对象
2、Producer的异步发送:分带回调函数调用API和不带回调函数API
回调函数会在producer收到ack时调用,为异步调用,该方法有两个参数,分别是RecordMetadata和Exception,如果Exception为null,说明消息发送成功,如果Exception不为null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
3、producer的同步发送:同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回 ack。
(2)consumer的API:Consumer 消费数据时的可靠性是很容易保证的,因为数据在 Kafka 中是持久化的,故不用担心数据丢失问题。由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。 所以 offset 的维护是 Consumer 消费数据是必须考虑的问题。
1、提交offset的方式
1)自动提交offset:在创建一个消费者时,默认是自动提交偏移量,这种方式也被称为【at most once】,fetch到消息后就可以更新offset,无论是否消费成功。
2)手动提交:对偏移量实行更加精确的管理,以保证消息不被重复消费以及消息不被丢失。这种方式称为【at least once】。fetch到消息后,等消费完成再调用方法consumer.commitSync(),手动更新offset;如果消费失败,则offset也不会更新,此条消息会被重复消费一次。手动提交又可以分为两种
手动提交 offset 的方法有两种:分别是 commitSync(同步提交)和 commitAsync(异步提交)。两者的相同点是,都会将本次 poll 的一批数据最高的偏移量提交;不同点是,commitSync 阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而 commitAsync 则没有失败重试机制,故有可能提交失败。
a、同步提交:同步模式下提交失败时一直尝试提交,直到遇到无法重试的情况下才会结束,同时,同步方式下消费者线程在拉取消息时会被阻塞,直到偏移量提交操作成功或者在提交过程中发生错误。
b、虽然同步提交 offset 更可靠一些,但是异步方式下消费者线程不会被阻塞,可能在提交偏移量操作的结果还未返回时就开始进行下一次的拉取操作,在提交失败时也不会尝试提交。
3)数据漏消费和重复消费分析:无论是同步提交还是异步提交 offset,都有可能会造成数据的漏消费或者重复消费。先提交 offset 后消费,有可能造成数据的漏消费;而先消费后提交 offset,有可能会造成数据的重复消费。
(3)kafka的拦截器:一共有两种:Kafka Producer端的拦截器和Kafka Consumer端的拦截器。主要的是Kafka Producer端的拦截器,它主要用来对消息进行拦截或者修改,也可以用于Producer的Callback回调之前进行相应的预处理。
以上是关于kafka API的主要内容,如果未能解决你的问题,请参考以下文章