引导读者从最基础的小程序网络请求封装到网络请求封装的最优解
在使用原生小程序网络api时,有以下两个缺点:
- 多个页面往往代表发送多个网络请求,这样对服务器的压力过大 -> 降压
- 基于原因1,防止未来微信官方废弃了wx.request这个api而换了另外一个api时造成的重复操作 ->降低依赖,防止重复
1. wx原生网络请求

微信原生请求看似很清晰,但成功与失败的函数都是在 wx.request内部,假设读者对jQuery有所了解,就会发觉跟jquery很像:

但这种方法已经濒临灭绝了,接下来使用基于promise对微信原生网络请求进行层层封装
2. 简单封装
// ../../request/one.js
export default function reqeust(params) {
return new Promise((resolve, reject) => {
wx.request({
url: params.url,
method: params.method || \'get\',
data: params.data || {},
success: res => {
resolve(res)
},
fail: err => {
reject(err)
}
})
})
}
如果对pomise相当了解,也可以使用进化版:
// ../../request/one.js
export default function reqeust(params) {
return new Promise((resolve, reject) => {
wx.request({
url: params.url,
method: params.method || \'get\',
data: params.data || {},
success: resolve,
fail: reject
})
})
}
页面内使用:
//页面内导入
import reqeust from \'../../request/one.js\'
// 页面的onload函数内使用
onLoad: function () {
reqeust({
url: \'https://xxxxxxxxxxxxxxxxxxxxxxxxxxx\',
})
.then(res => {
console.log(res)
})
.catch(err => console.log(err))
}
结果也是一样的
3. 进化版封装
回顾下es6的导入导出知识:
// 常量的导出
//public.js
const demo = \'使用export导出的常量,不可以重命名该常量,需要用大括号\';
export {
demo
}
//常量的导入
//getdemo.js
import { demo } from \'./public\'
console.log(demo ) // \'使用export导出的常量,不可以重命名该常量,需要用大括号\'
//函数的导出与导入
//函数的导出
//fn.js
export function fn() {
console.log("使用export导出的fn,不可以重命名该函数,需要用大括号")
}
//函数的导入
//getFn.js
import { fn } from \'./fn.js\'
fn(); // "使用export导出的fn,不可以重命名该函数,需要用大括号"
//全部导出与导入
//导出
//allData.js
export default function allData() {
console.log("使用export default 导出的数据,可以重命名该函数,不需要用大括号")
}
//getAllData.js
//导入
import reName_AllData from \'./allData.js\'
reName_AllData()//"使用export default 导出的数据,可以重命名该函数,不需要用大括号"
假设请求的url有一部分是相同的
- 将url分为两部分:第一部分作为公共的请求地址publicURL,单独抽离成一个文件,另一部分作为单个页面请求的网络地址PageUrl
- 在requers.js里将公共的请求地址publicURL添加进url里
- 页面导入request.js 发起请求
//抽取公共url到单独文件
//publicData.js
const baseURL = \'https://jiazhuang/zheshi/yige/gonggongurl\';
export {
baseURL
}
//封装的网络请求文件,导入上述文件
//network1-0.js
import { baseURL } from \'./public\'
export function request(params) {
return new Promise((resolve, reject) => {
wx.request({
url: baseURL + params.url,
method: params.method || \'get\',
data: params.data || {},
success: resolve,
fail: reject
});
})
}
//页面使用时仅填入对应的网络地址即可
//页面导入封装好的network1-0.js
import { request } from \'../../req/newwork1-5\'
//onLoad函数内使用
onLoad: function () {
request({
url: \'public/v1/home/swiperdata\'
}).then(res => {
console.log(res)
})
.catch(err => console.log(err))
}
以上就是第二层封装.
但是这样还是有不太方便的一面:
单个页面需要发送的请求太多,代码的可读性并不太好
那么就有了终极版封装:
4. 网络请求的究极封装
这一步时,我们的目的就是为了分层:
基于页面分层,封装单个页面需要发送的请求为一个文件getPage.js由page.js负责向request.js发送真正的网络请求,而页面要做的就是调用page.js里的单个请求方法
以下为图示:
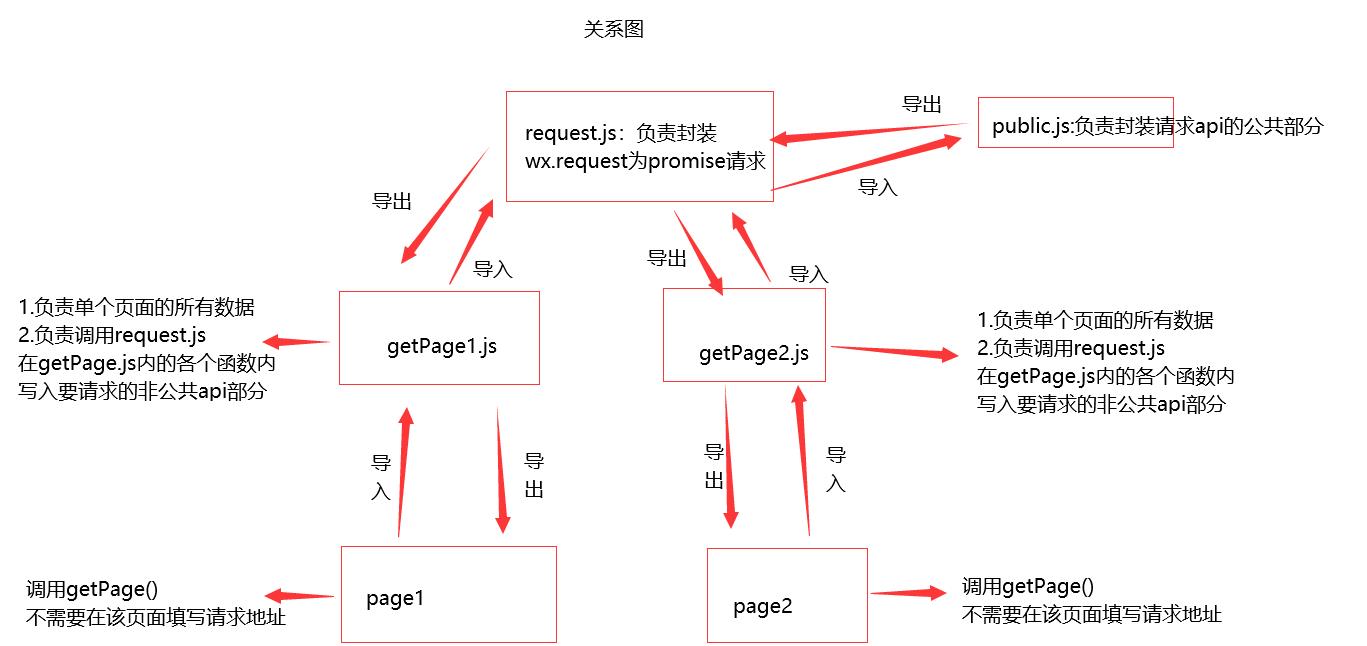
解释:
- request.js负责将公共api与getPage.js里传入的api进行拼接,整合后向后台发送数据
- getPage.js向上负责向request.js发送请求,向下作为发送请求函数等待被调用,函数内部存储非公共api
- page作为页面,仅调用getPage.js内部的函数即可
整演示例
//publicData.js 作为api的公共部分
const baseUrl= \'https://jiazhuang-shiyige-api/api/\';
export {
baseUrl
}
//request.js 作为真正发送网络请求的文件
import { publicUrl } from \'./publicData\'
export default function reqeust(params) {
return new Promise((resolve, reject) => {
wx.request({
url: publicUrl + params.url,
method: params.method || \'get\',
data: params.data || {},
success: resolve,
fail: reject
})
})
}
// getIndexData.js : 向上负责调用request.js,向下负责该page页面的发送网络请求的所有函数,函数的内部存储了非公共部分的请求地址
import reqeust from \'./request\'
export function getBannerData() {
return reqeust({
url: \'wo/zhen-de/shi/api/banner\',
})
}
//index页面导入所属的getIndexData.js,在onload函数内调用所属页面的方法
import { getBannerData} from \'../../request/getIndexData\'
onload(){
getBannerData().then(res => {
console.log(res)
//这里就可以对数据进行操作了
}).catch(err => console.log(err))
}
在这个例子里,一步步解释了流程,或许有些冗余,但这些更符合了规范化,page页面不关心发送网络请求,只负责调用,getPageData.js只负责将对应的url发送给request.js处理,而request.js负责拼接整合url以及其他,最终发送向网络请求.如果愿意,还可以单个页面再细分,所作的一切都是为了服务于开发.
以上就是将小程序的原生网络请求一步步封装达到最优解.
