go任务调度3(etcd协调服务raft协议)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了go任务调度3(etcd协调服务raft协议)相关的知识,希望对你有一定的参考价值。
etcd是将数据存储在集群中的高可用k-v存储。
允许应用实时监听存储中的k-v变化。
能容忍单点故障,能够应对网络分区。



(raft是一个分布式协议,管理的是日志;etcd管理的是k-v,把k-v放到日志里,kv就编程分布式集群了)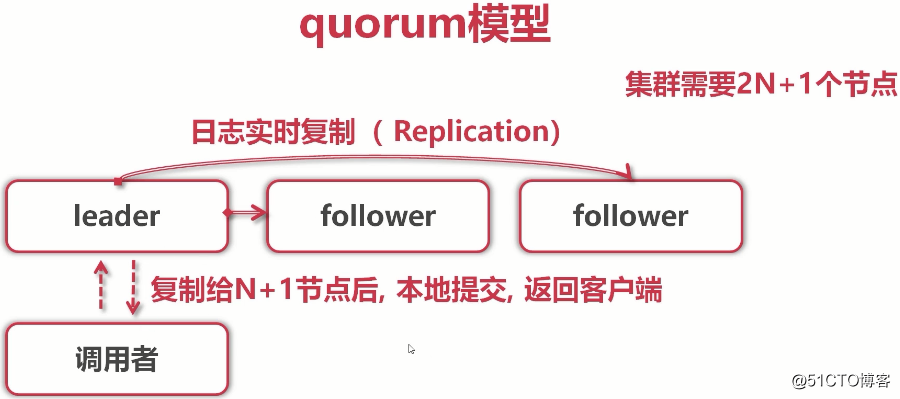
(调用者写入请求发给leader请求写入k-v,leader会将日志实时向follower们复制,leader不会立即返回给调用者,会马上往集群follower做日志拷贝。当日志被复制给N+1个节点后(即大多数),本地提交(也就是告诉客户端提交成功),返回给调用者(客户端),为什么复制给N+1,而不是2N+1后就告诉客户端成功了呢?这就是大多数协议,也就是抽屉理论的重要表现)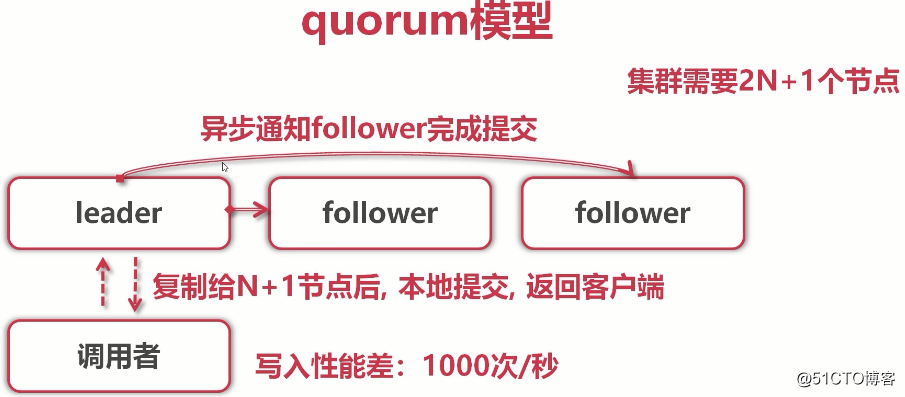
(一旦完成提交,leader会周期性把自己的提交信息告诉所有follower,这样,其他follower也会完成它们的本地提交(这是异步行为,不需要同步,只需要确保日志复制给大多数了就可以)。官方给出的写入性能是:1000次每秒)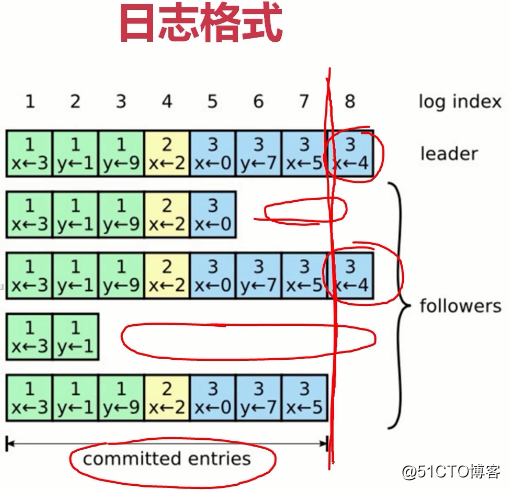
(raft协议本身就是在写日志。第1行是leader节点的日志,后面是4个是follower,也就是总共5个节点。日志是随着请求顺序追加,这里5个节点的大多数是3个节点。其中1-7已经被复制给了3个节点(大多数),这些是一定可以被提交不会丢失的,因为已经复制给大多数了。8总共只有两个节点有,8后面其他的更夸张。有的连3,4,5都没有,这一般是leader和follower之间产生了网络延迟,然而,没关系,只要复制给大多数就不会丢了。所以真个日志的提交已经到了第7个日志)
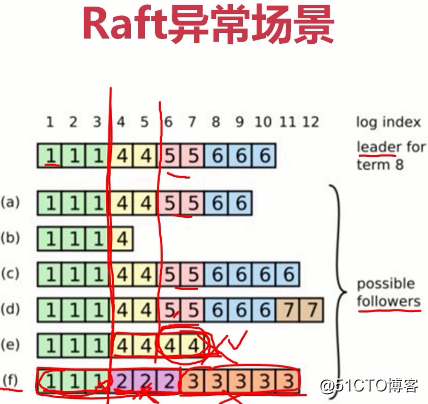
(
第一个leader幸运是f,f写入了3条数据(标识为1的绿色块),并成功复制给了所有节点,然后f宕机了又马上重启。
因为宕机,而f曾经是leader,于是重新选举,踩了狗屎很幸运,f又成了leader。f又提交了3条记录(标识为2的紫色块),但它没有复制给集群中的其他节点(可能f刚成为leader没来得及复制给其他节点又挂掉了)。
f宕机后重启,又踩了狗屎成为了第三任leader,写入5条数据(下标为3的橙色块),没来得及复制有宕了。
然后第四任leader幸运的是e,e写入了4条数据(下标为4的×××块),但它作为leader期间,只把前面两条(下标为4的×××块)数据复制给大多数节点,后两个没来得及复制就宕了......
)
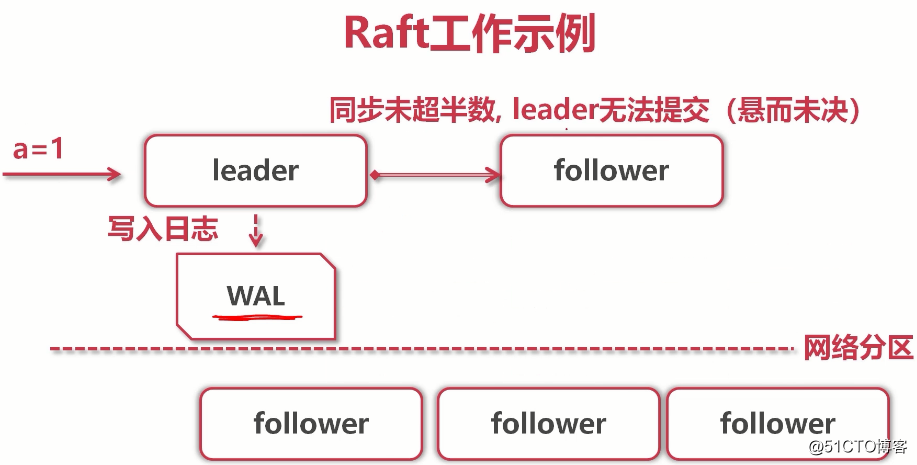
(leader写入数据,但只复制给了一个follower,其他由于网络原因没复制,所以无法提交,无法给客户端应答,客户端继续等待...)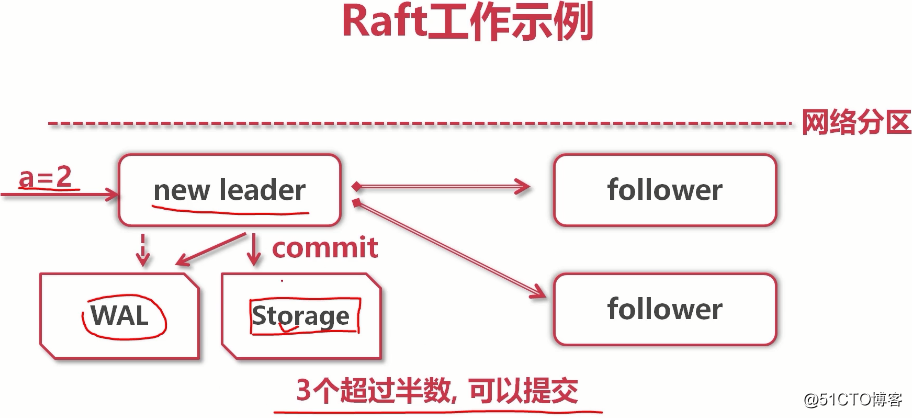
(raft协议是底层原理,etcd将k-v写入storage才是真的。当复制给大多数后,leader就告诉客户端:你的事已经办好了)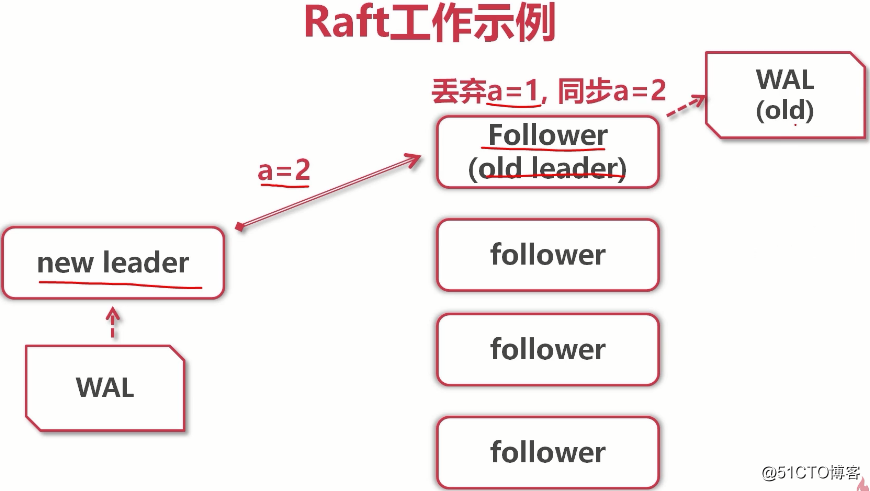
(当old leader重启后,它发现已经有了一个新leader,并且它的数据是落后于new leader的,所以new leader会把a=2复制给old leader,而old leader会发现,原来的a=1没有复制给大多数(未提交状态),而a=2已经完成了大多数复制,所以a=2会覆盖掉a=1。所以在集群中a=2而不是1)
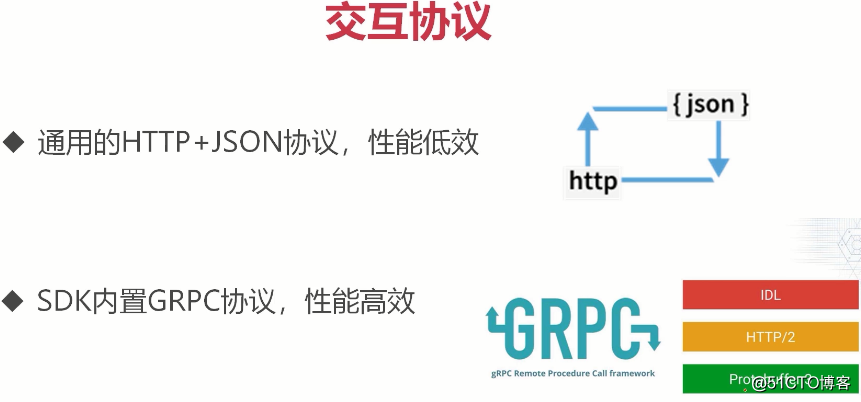
(etcd支持通用的http+json协议,但性能较低。sdk内置GRPC协议,性能很高。GRPC是谷歌开源的RPC协议,是基于http2协议。我们用的etcd就是基于GRPC的。我们通过sdk操作etcd中的k-v)
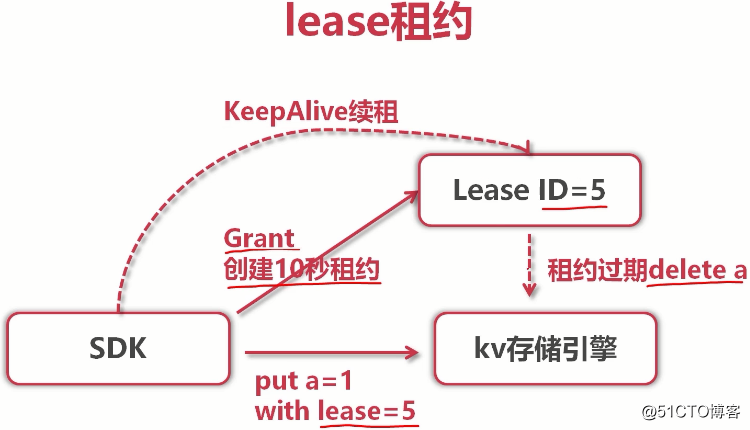
(能实现像redis一样的时间过期)
(用有序的key模拟出目录的效果。也就是只要定位到/feature-flags,就能根据它找到类似该目录下的所有目录(其实是key))
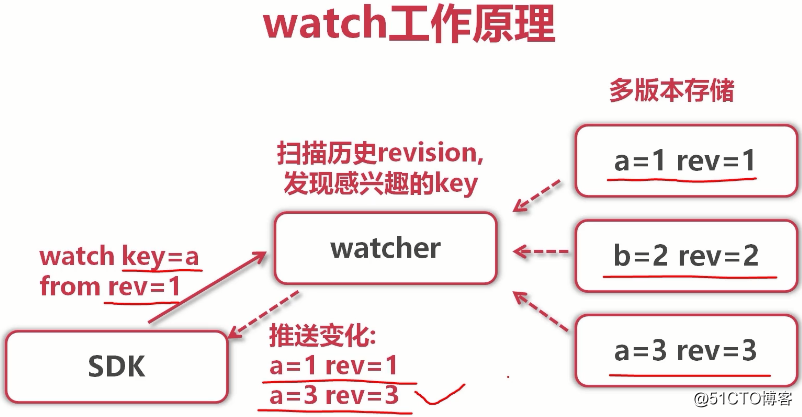
(即便key1=value3覆盖了之前的key1=value1,在etcd中也会有key1=value1这个历史版本(也就是revision=1)。然而我们只关心最新的数据,可以用compact命令完成删减)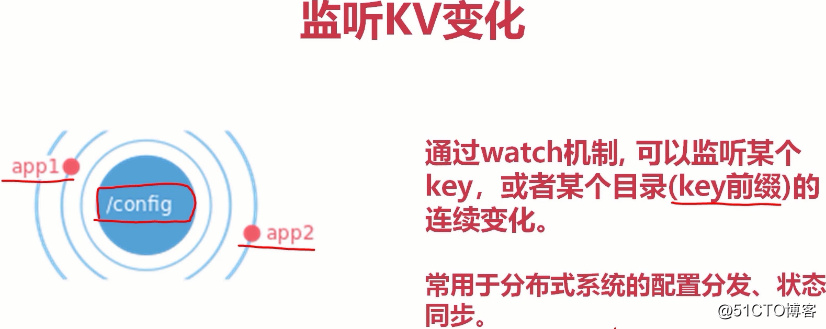
以上是关于go任务调度3(etcd协调服务raft协议)的主要内容,如果未能解决你的问题,请参考以下文章