web页面元素的8种定位方法
Posted YLG001
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了web页面元素的8种定位方法相关的知识,希望对你有一定的参考价值。
一、web页面元素定位工具介绍
1、打开google浏览器,按F12进入开发者模式,如下图:
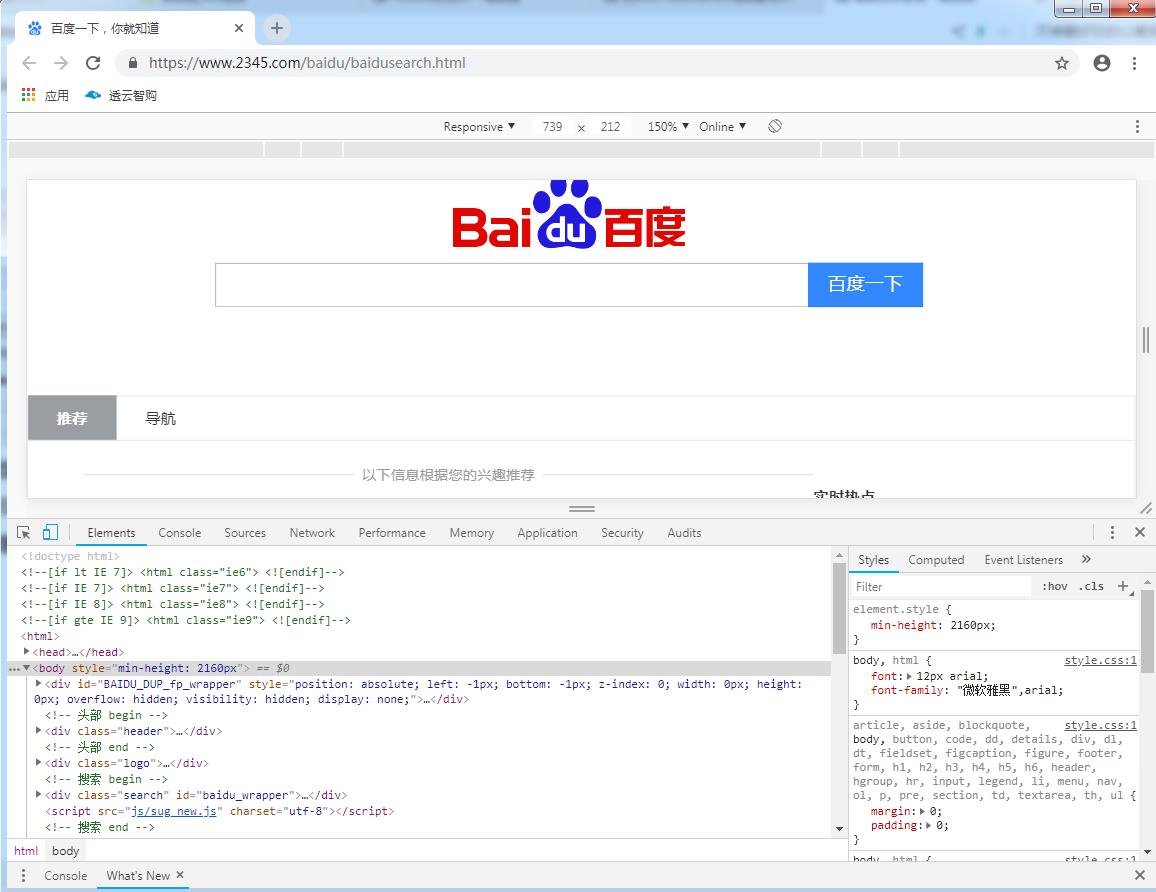
2、用鼠标点击下图红色框中的箭头——然后鼠标移动到web页面的元素上(此处为百度框),会自动定位到对应的html代码,如下图:
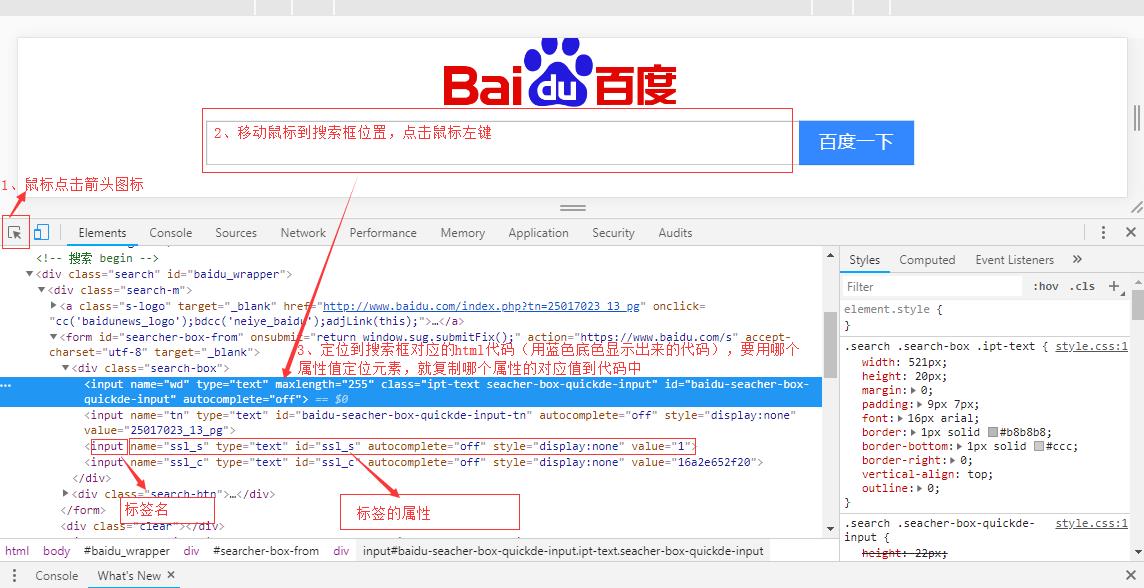
二、web页面元素的8种定位方法:
1、通过元素的id属性来定位元素——id是唯一标识(每个id都是不一样的)
driver.find_element_by_id("kw")
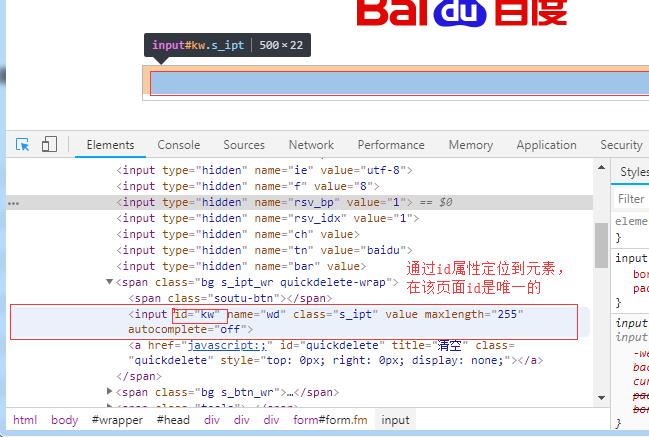


1 from selenium import webdriver 2 driver=webdriver.Chrome() 3 driver.get("https://www.baidu.com/") 4 5 # 通过元素的id属性来定位——id是唯一的 6 search=driver.find_element_by_id("kw") 7 8 search.send_keys("selenium")
2、通过元素的name属性来定位元素,name属性不是绝对唯一的(一个页面内可能存在多个元素的name属性是相同的)
如果name属性的值wd是唯一的,用find_element_by_name定位元素,返回值是一个值
driver.find_element_by_name("wd")
如果name属性的值wd不是唯一的,用find_elements_by_name定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表
driver.find_elements_by_name("wd")
1 from selenium import webdriver 2 driver=webdriver.Chrome() 3 driver.get("https://www.baidu.com/") 4 5 #通过元素的name属性来定位元素,name属性不是绝对唯一的(一个页面内可能存在多个元素的name属性是相同的) 6 7 # 如果name属性的值kw是唯一的,用find_element_by_name定位元素,返回值是一个值 8 search=driver.find_element_by_name("wd") 9 10 # 如果name属性的值kw不是唯一的,用find_elements_by_name定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表 11 search=driver.find_elements_by_name("wd") 12 13 14 search.send_keys("python")
3、通过元素的class属性来定位元素,class属性不是绝对唯一的(一个页面内可能存在多个元素的class属性是相同的)
如果class属性的值s_ipt是唯一的,用find_element_by_class_name定位元素,返回值是一个值
driver.find_element_by_class_name("s_ipt")
如果class属性的值s_ipt不是唯一的,用find_elements_by_class_name定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表
driver.find_elements_by_class_name("s_ipt")
1 from selenium import webdriver 2 driver=webdriver.Chrome() 3 driver.get("https://www.baidu.com/") 4 5 #通过元素的class属性来定位元素,class属性不是绝对唯一的(一个页面内可能存在多个元素的class属性是相同的) 6 7 # 如果class属性的值s_ipt是唯一的,用find_element_by_class定位元素,返回值是一个值 8 search=driver.find_element_by_class_name("s_ipt") 9 10 # 如果class属性的值s_ipt不是唯一的,用find_elements_by_class定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表 11 search=driver.find_elements_by_class_name("s_ipt") 12 13 14 search.send_keys("java")
4、通过元素的标签名tag来定位元素,标签名不是绝对唯一的(一个页面内可能存在多个相同的标签名)
如果标签名是唯一的,用find_element_by_tag_name定位元素,返回值是一个值
driver.find_element_by_tag_name("input")
如果标签名不是唯一的,用find_elements_by_tag_name定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表
driver.find_elements_by_tag_name("input")
要找的元素是第8个input标签,所以通过列表查找时下标是7
search2[7].send_keys("java")
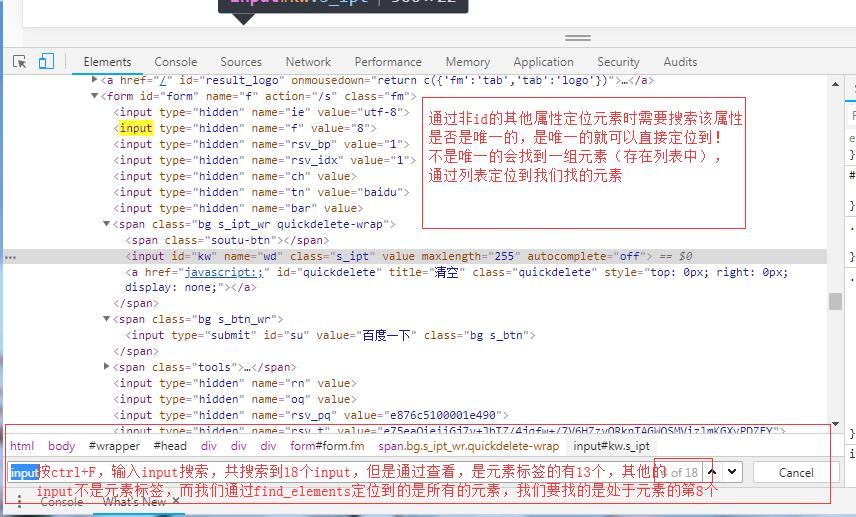
备注:上图找到的是15个标签,不是13个
1 from selenium import webdriver 2 driver=webdriver.Chrome() 3 driver.get("https://www.baidu.com/") 4 5 #通过元素的标签名来定位元素,标签名不是绝对唯一的(一个页面内可能存在多个相同的标签名) 6 7 # 如果标签名是唯一的,用find_element_by_tag_name定位元素,返回值是一个值 8 #search=driver.find_element_by_tag_name("input") 9 10 # 如果标签名不是唯一的,用find_elements_by_tag_name定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表 11 search2=driver.find_elements_by_tag_name("input") 12 13 #打印出15个元素 14 print(search2) 15 16 #要找的元素是第8个input标签,所以通过列表查找时下标是7 17 search2[7].send_keys("java")
5&6、通过链接元素的文本内容来精确匹配和模糊匹配定位元素,不是绝对唯一的(一个页面内可能存在多个链接元素的文本内容是相同的)
1、精确匹配——文本内容为“新闻”
如果文本内容时唯一的,用find_element_by_link_text定位元素,返回值是一个值
driver.find_element_by_link_text("新闻")
如果文本内容不是唯一的,用elements_by_link_text定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表
driver.find_elements_by_link_text("新闻")
2、模糊匹配——通过文本内容的部分内容,例如“hao123”,通过“hao”定位
如果文本内容时唯一的,用find_element_by_partial_link_text定位元素,返回值是一个值
driver.find_element_by_partial_link_text("hao123")
如果文本内容不是唯一的,用find_elements_by_partial_link_text定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表
driver.find_elements_by_partial_link_text("hao123")
1 # 1、精确匹配——文本内容为“新闻” 2 # 如果文本内容时唯一的,用find_element_by_link_text定位元素,返回值是一个值 3 search=driver.find_element_by_link_text("新闻") 4 5 # 如果文本内容不是唯一的,用elements_by_link_text定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表 6 search=driver.find_elements_by_link_text("新闻") 7 8 search.click() 9 10 # 2、模糊匹配——通过文本内容的部分内容,例如“hao123”,通过“hao”定位 11 # 如果文本内容时唯一的,用find_element_by_partial_link_text定位元素,返回值是一个值 12 aa=driver.find_element_by_partial_link_text("hao123") 13 14 # 如果文本内容不是唯一的,用find_elements_by_partial_link_text定位元素,返回符合条件的多个值,保存在列表中,即返回的是列表 15 16 aa=driver.find_elements_by_partial_link_text("hao123")
7、通过Xpath定位
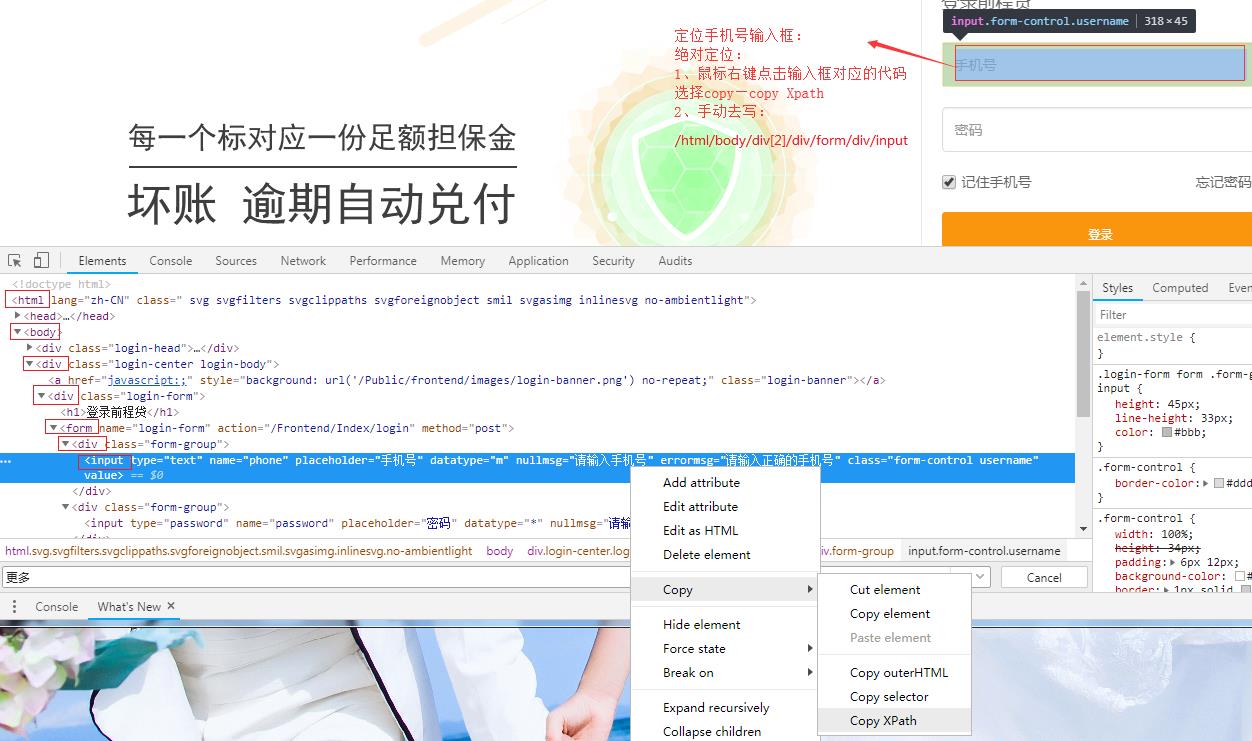
1、绝对路径定位方法如下图:
find_element_by_xpath("/html/body/div[2]/div/form/div/input")——以/开头,从根目录逐级查找(父子关系),这种方式太依赖元素的位置和顺序,稍微调整就会找不到,后期维护成本太高,所以一般不会用绝对定位
2、相对定位——以//开头,在整个页面中寻找符合定位表达式的元素,不在乎元素的顺序和位置
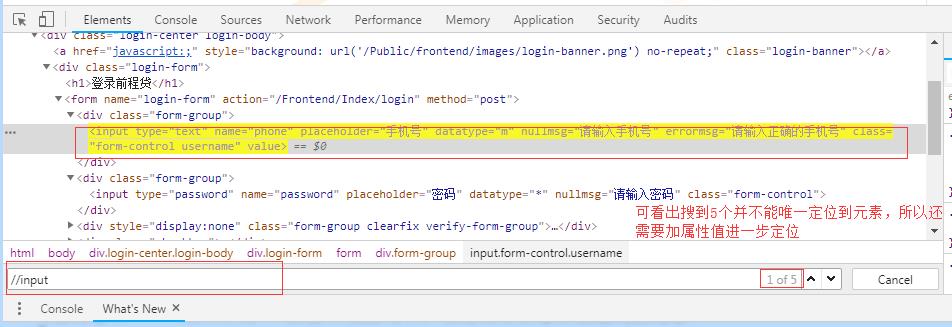
单属性定位: //标签名[@属性名称=值]
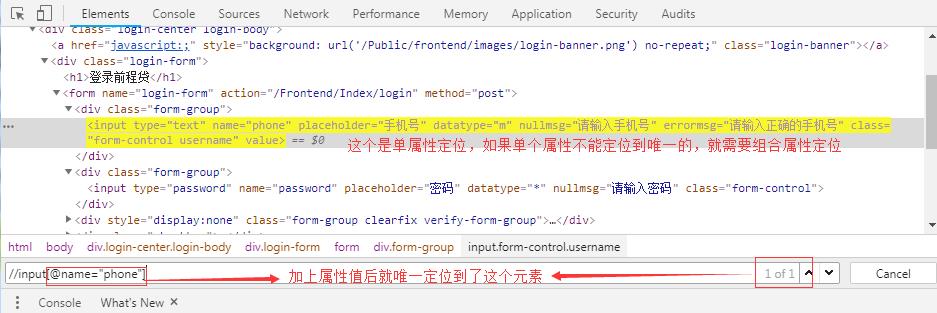
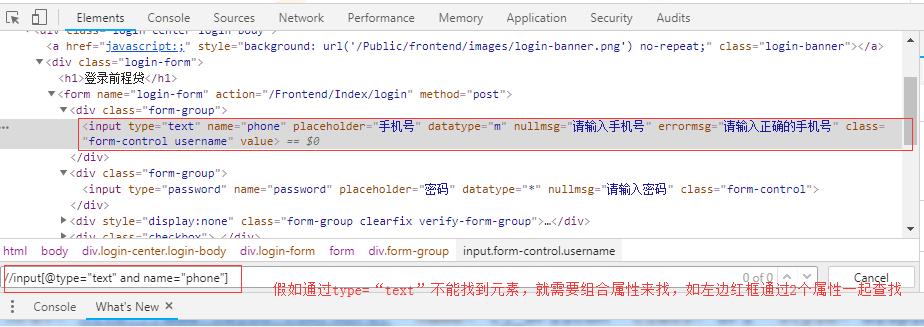
如果单属性定位不到,就需要组合属性定位://标签名[@属性名称=值 and @属性名称=值 and @属性名称=值]
如果页面存在2个一模一样的元素,只是位置不同,定位方式如下图:从父类开始找,父类还不能唯一确定,继续从父类的父类就找
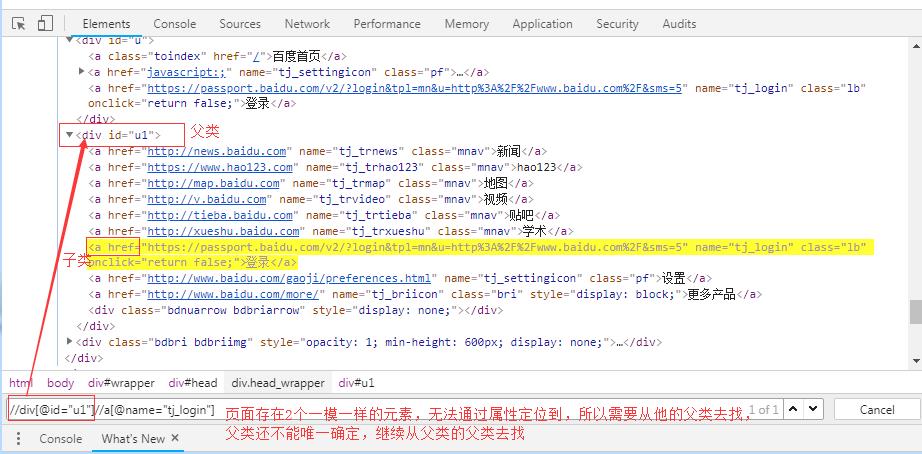
另外的方式:通过父类去找:
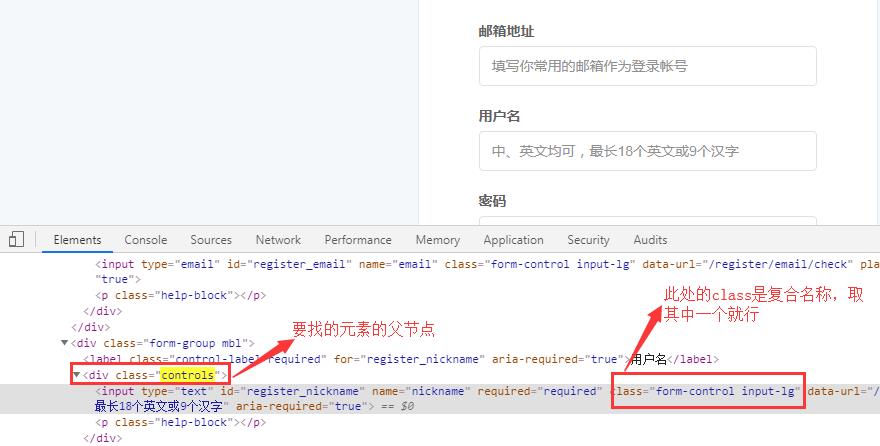
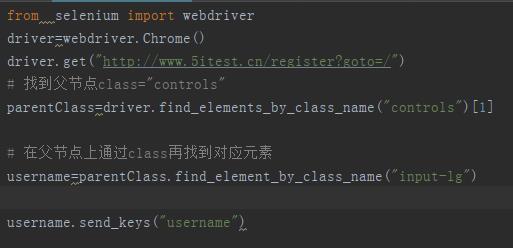
xpath模糊匹配:
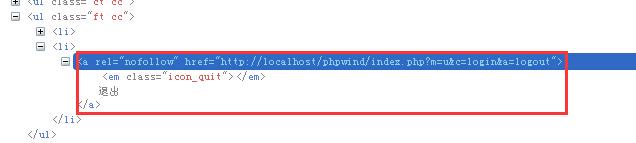
a. 用contains关键字,寻找页面中href属性值包含有logout这个单词的所有a元素,由于这个退出按钮的href属性里肯定会包含logout,所以这种方式是可行的,也会经常用到。其中@后面可以跟该元素任意的属性名,定位代码如下:
driver.find_element_by_xpath("//a[contains(@href, ‘logout’)]")
这句话的意思是
b. 用start-with:寻找rel属性以nofo开头的a元素。其中@后面的rel可以替换成元素的任意其他属性,定位代码如下
driver.find_element_by_xpath(("//a[starts-with(@rel, ‘nofo’)]")
c. 用Text关键字,寻找包含“退出”文本的所有a元素,定位代码如下:
driver.find_element_by_xpath("//a[contains(text(), ’退出’)]")
3.XPath 关于网页中的动态属性的定位,例如,ASP.NET 应用程序中动态生成 id 属性值,可以有以下三种方法:
a.starts-with 例子: input[starts-with(@id,\'ctrl\')] 解析:匹配以 ctrl开始的属性值
b.ends-with 例子:input[ends-with(@id,\'userName\')] 解析:匹配以 userName 结尾的属性值
c.contains() 例子:Input[contains(@id,\'userName\')] 解析:匹配含有 userName 属性值
G.xpath文本精准定位
//a[text()=\'新闻\'] #精准定位到本文属性,contains则是模糊定位
以上是关于web页面元素的8种定位方法的主要内容,如果未能解决你的问题,请参考以下文章