服务器性能监控tips
Posted 897807300
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务器性能监控tips相关的知识,希望对你有一定的参考价值。
一、tops
第一行

当前时间/已运行时间/登录用户数/最近 5 10 15分钟平均负载(平均进程数 cat /proc/loadavg)

除了前3个数字表示平均进程数量外,后面的1个分数,分母表示系统进程总数,分子表示正在运行的进程数;最后一个数字表示最近运行的进程ID。
系统平均负载-进阶解释
只是上面那一句话的解释,基本等于没解释。写这篇文章的缘由就是因为看到了一篇老外写的关于Load Average的文章,觉得解释的很好,所以才打算摘取一部分用自己的话翻译一下。
@scoutapp Thanks for your article Understanding Linux CPU Load, I just translate and share it to Chinese audiences.
为了更好地理解系统负载,我们用交通流量来做类比。
1、单核CPU - 单车道 - 数字在0.00-1.00之间正常
路况管理员会告知司机,如果前面比较拥堵,那司机就要等待,如果前面一路畅通,那么司机就可以驾车直接开过。

具体来说:
0.00-1.00 之间的数字表示此时路况非常良好,没有拥堵,车辆可以毫无阻碍地通过。
1.00 表示道路还算正常,但有可能会恶化并造成拥堵。此时系统已经没有多余的资源了,管理员需要进行优化。
1.00-*** 表示路况不太好了,如果到达2.00表示有桥上车辆一倍数目的车辆正在等待。这种情况你必须进行检查了。
2、多核CPU - 多车道 - 数字/CPU核数 在0.00-1.00之间正常

多核CPU的话,满负荷状态的数字为 "1.00 * CPU核数",即双核CPU为2.00,四核CPU为4.00。
3、安全的系统平均负载
作者认为单核负载在0.7以下是安全的,超过0.7就需要进行优化了。
4、应该看哪一个数字,1分钟,5分钟还是15分钟?
作者认为看5分钟和15分钟的比较好,即后面2个数字。
5、怎样知道我的CPU是几核呢?
使用以下命令可以直接获得CPU核心数目
grep \'model name\' /proc/cpuinfo | wc -l

解释:2核CPU,过去一分钟1.25/2,过载62.5%;过去5分钟,CPU不过载,过去15分钟,0.74/2=37%的CPU空闲。看 5分钟和15分钟的比较准确
误解:load average
在load average高的情况下分析系统瓶颈
1.3:如何判断系统是否已经Over Load?
对一般的系统来说,根据cpu数量去判断。如果平均负载始终在1.2一下,而你有2颗cup的机器。那么基本不会出现cpu不够用的情况。也就是Load平均要小于Cpu的数量
1.4:Load与容量规划(Capacity Planning)
一般是会根据15分钟那个load 平均值为首先。
1.5:Load误解:
1:系统load高一定是性能有问题。
真相:Load高也许是因为在进行cpu密集型的计算
2:系统Load高一定是CPU能力问题或数量不够。
真相:Load高只是代表需要运行的队列累计过多了。但队列中的任务实际可能是耗Cpu的,也可能是耗i/0奶子其他因素的。
3:系统长期Load高,首先增加CPU
真相:Load只是表象,不是实质。增加CPU个别情况下会临时看到Load下降,但治标不治本。
2:在Load average 高的情况下如何鉴别系统瓶颈。
是CPU不足,还是io不够快造成或是内存不足?
2.1:查看系统负载vmstat
procs
r 列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
cpu 表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比
system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
memory
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示)
buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si 由内存进入内存交换区数量。
so由内存交换区进入内存数量。
IO
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。
bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
2.2:查看磁盘负载iostat
每隔2秒统计一次磁盘IO信息,直到按Ctrl+C终止程序,-d 选项表示统计磁盘信息, -k 表示以每秒KB的形式显示,-t 要求打印出时间信息,2 表示每隔 2 秒输出一次。第一次输出的磁盘IO负载状况提供了关于自从系统启动以来的统计信息。随后的每一次输出则是每个间隔之间的平均IO负载状况。

# iostat -x 1 10
Linux 2.6.18-92.el5xen 02/03/2009
avg-cpu: %user %nice %system %iowait %steal %idle
1.10 0.00 4.82 39.54 0.07 54.46
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 3.50 0.40 2.50 5.60 48.00 18.48 0.00 0.97 0.97 0.28
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sde 0.00 0.10 0.30 0.20 2.40 2.40 9.60 0.00 1.60 1.60 0.08
sdf 17.40 0.50 102.00 0.20 12095.20 5.60 118.40 0.70 6.81 2.09 21.36
sdg 232.40 1.90 379.70 0.50 76451.20 19.20 201.13 4.94 13.78 2.45 93.16
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘
可能存在瓶颈。
idle小于70% IO压力就较大了,一般读取速度有较多的wait.
同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
另外还可以参考
一般:
svctm < await (因为同时等待的请求的等待时间被重复计算了),
svctm的大小一般和磁盘性能有关:CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。
await: await的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。
如果 svctm 比较接近 await,说明I/O 几乎没有等待时间;
如果 await 远大于 svctm,说明 I/O队列太长,应用得到的响应时间变慢,
如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
别人一个不错的例子.(I/O 系统 vs. 超市排队)
举一个例子,我们在超市排队 checkout 时,怎么决定该去哪个交款台呢? 首当是看排的队人数,5个人总比20人要快吧?除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星期食品的大妈,那么可以考虑换个队排了。还有就是收银员的速度了,如果碰上了连钱都点不清楚的新手,那就有的等了。另外,时机也很重要,可能 5分钟前还人满为患的收款台,现在已是人去楼空,这时候交款可是很爽啊,当然,前提是那过去的 5 分钟里所做的事情比排队要有意义(不过我还没发现什么事情比排队还无聊的)。
I/O 系统也和超市排队有很多类似之处:
r/s+w/s 类似于交款人的总数
平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
平均服务时间(svctm)类似于收银员的收款速度
平均等待时间(await)类似于平均每人的等待时间
平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
I/O 操作率 (%util)类似于收款台前有人排队的时间比例。
我们可以根据这些数据分析出 I/O 请求的模式,以及 I/O 的速度和响应时间。
下面是别人写的这个参数输出的分析
# iostat -x 1
avg-cpu: %user %nice %sys %idle
16.24 0.00 4.31 79.44
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/cciss/c0d0
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p1
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p2
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
上面的 iostat 输出表明秒有 28.57 次设备 I/O 操作: 总IO(io)/s = r/s(读) +w/s(写) = 1.02+27.55 = 28.57 (次/秒) 其中写操作占了主体 (w:r = 27:1)。
平均每次设备 I/O 操作只需要 5ms 就可以完成,但每个 I/O 请求却需要等上 78ms,为什么? 因为发出的 I/O 请求太多 (每秒钟约 29 个),假设这些请求是同时发出的,那么平均等待时间可以这样计算:
平均等待时间 = 单个 I/O 服务时间 * ( 1 + 2 + ... + 请求总数-1) / 请求总数
应用到上面的例子: 平均等待时间 = 5ms * (1+2+...+28)/29 = 70ms,和 iostat 给出的78ms 的平均等待时间很接近。这反过来表明 I/O 是同时发起的。
每秒发出的 I/O 请求很多 (约 29 个),平均队列却不长 (只有 2 个 左右),这表明这 29 个请求的到来并不均匀,大部分时间 I/O 是空闲的。
一秒中有 14.29% 的时间 I/O 队列中是有请求的,也就是说,85.71% 的时间里 I/O 系统无事可做,所有 29 个 I/O 请求都在142毫秒之内处理掉了。
delta(ruse+wuse)/delta(io) = await = 78.21 => delta(ruse+wuse)/s=78.21 * delta(io)/s = 78.21*28.57 =2232.8,表明每秒内的I/O请求总共需要等待2232.8ms。所以平均队列长度应为 2232.8ms/1000ms = 2.23,而iostat 给出的平均队列长度 (avgqu-sz) 却为 22.35,为什么?! 因为 iostat 中有 bug,avgqu-sz值应为 2.23,而不是 22.35。
第二行

任务:第二行显示的是任务或者进程的总结。进程可以处于不同的状态。这里显示了全部进程的数量。除此之外,还有正在运行、睡眠、停止、僵尸进程的数量(僵尸是一种进程的状态)。这些进程概括信息可以用\'t\'切换显示。
第三行

CPU状态
us, user: 运行(未调整优先级的) 用户进程的CPU时间
sy,system: 运行内核进程的CPU时间
ni,niced:运行已调整优先级的用户进程的CPU时间
wa,IO wait: 用于等待IO完成的CPU时间
id, 空闲CPU百分比
hi:处理硬件中断的CPU时间
si: 处理软件中断的CPU时间
st:这个虚拟机被hypervisor偷去的CPU时间
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
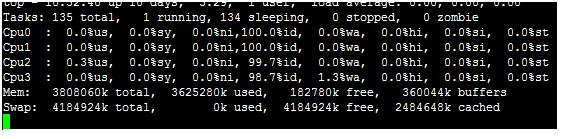
观察上图,服务器有4个逻辑CPU,实际上是1个物理CPU。
如果不按1,则在top视图里面显示的是所有cpu的平均值。
第四行

物理内存显示如下:
1,total:物理内存实际总量
2,used:这块千万注意,这里可不是实际已经使用了的内存哦,这里是总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用。
3,free:未被分配的内存
4,shared:共享内存
5,buffers:系统分配的,但未被使用的buffer剩余量。注意这不是总量,而是未分配的量
6,cached:系统分配的,但未被使用的cache 剩余量。buffer 与cache 的区别见后面。
7,buffers/cache used:这个是buffers和cache的使用量,也就是实际内存的使用量,这个非常重要了,这里才是内存的实际使用量哦
8, buffers/cache free:未被使用的buffers 与cache 和未被分配的内存之和,这就是系统当前实际可用内存。千万注意,这里是 三者之和,也就是第一排的 free+buffers+cached,可不仅仅是未被使用的buffers 与cache的和哦,还要加上free(未分配的和)
9,swap,这个我想大家都理解,交换分区总量,使用量,剩余量
全部可用内存、已使用内存、空闲内存、缓冲内存。相似地:交换部分显示的是:全部、已使用、空闲和缓冲交换空间。
Mem: 3881920k total 物理内存总量
3130516k used 使用的物理内存总量
288948 free 空闲内存总量
462456k buffers 用作内核缓存的内存量
Swap: 524284k total 交换区总量
132188k used 使用的交换区总量
392096k free 空闲交换区总量
450648k cached 缓冲的交换区总量。
内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,
该数值即为这些内容已存在于内存中的交换区的大小。
相应的内存再次被换出时可不必再对交换区写入。
内存显示可以用\'m\'命令切换。
5.字段
在横向列出的系统属性和状态下面,是以列显示的进程。不同的列代表下面要解释的不同属性。
默认上,top显示这些关于进程的属性:
PID 进程ID,进程的唯一标识符
USER 进程所有者的实际用户名。
PR 进程的调度优先级。这个字段的一些值是\'rt\'。这意味这这些进程运行在实时态。
NI 进程的nice值(优先级)。越小的值意味着越高的优先级。
VIRT 进程使用的虚拟内存。
RES 驻留内存大小。驻留内存是任务使用的非交换物理内存大小。
SHR 进程使用的共享内存。
S 这个是进程的状态。它有以下不同的值:
D - 不可中断的睡眠态。
R – 运行态
S – 睡眠态
T – 被跟踪或已停止
Z – 僵尸态
%CPU
自从上一次更新时到现在任务所使用的CPU时间百分比。
%MEM
进程使用的可用物理内存百分比。
TIME+
任务启动后到现在所使用的全部CPU时间,精确到百分之一秒。
COMMAND
运行进程所使用的命令。
top命令的补充
top命令是Linux上进行系统监控的首选命令,但有时候却达不到我们的要求,比如当前这台服务器,top监控有很大的局限性。这台服务器运行着websphere集群,有两个节点服务,就是【top视图 01】中的老大、老二两个java进程,top命令的监控最小单位是进程,所以看不到我关心的java线程数和客户连接数,而这两个指标是java的web服务非常重要的指标,通常我用ps和netstate两个命令来补充top的不足。
监控java线程数:
ps -eLf | grep java | wc -l
监控网络客户连接数:
netstat -n | grep tcp | grep 侦听端口 | wc -l
上面两个命令,可改动grep的参数,来达到更细致的监控要求。
在Linux系统“一切都是文件”的思想贯彻指导下,所有进程的运行状态都可以用文件来获取。系统根目录/proc中,每一个数字子目录的名字都是运行中的进程的PID,进入任一个进程目录,可通过其中文件或目录来观察进程的各项运行指标,例如task目录就是用来描述进程中线程的,因此也可以通过下面的方法获取某进程中运行中的线程数量(PID指的是进程ID):
ls /proc/PID/task | wc -l
在linux中还有一个命令pmap,来输出进程内存的状况,可以用来分析线程堆栈:
pmap PID
大家都熟悉Linux下可以通过top命令来查看所有进程的内存,CPU等信息。除此之外,还有其他一些命令,可以得到更详细的信息,例如进程相关
cat /proc/your_PID/status
通过top或ps -ef | grep \'进程名\' 得到进程的PID。该命令可以提供进程状态、文件句柄数、内存使用情况等信息。
内存相关
vmstat -s -S M
该可以查看包含内存每个项目的报告,通过-S M或-S k可以指定查看的单位,默认为kb。结合watch命令就可以看到动态变化的报告了。
也可用 cat /proc/meminfo
要看cpu的配置信息可用
cat /proc/cpuinfo
它能显示诸如CPU核心数,时钟频率、CPU型号等信息。
要查看cpu波动情况的,尤其是多核机器上,可使用
mpstat -P ALL 10
该命令可间隔10秒钟采样一次CPU的使用情况,每个核的情况都会显示出来,例如,每个核的idle情况等。
只需查看均值的,可用
iostat -c
IO相关
iostat -P ALL
该命令可查看所有设备使用率、读写字节数等信息。
另外,htop ,有时间可以用一下。
Linux查看物理CPU个数、核数、逻辑CPU个数
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
以上是关于服务器性能监控tips的主要内容,如果未能解决你的问题,请参考以下文章
性能监控之 Golang 应用接入 Prometheus 监控
性能测试分析与性能调优诊断--史上最全的服务器性能分析监控调优篇