ResNeXtAggregated Residual Transformations for Deep Neural Networks (2017) 全文翻译
Posted 魏晓蕾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ResNeXtAggregated Residual Transformations for Deep Neural Networks (2017) 全文翻译相关的知识,希望对你有一定的参考价值。
作者
Saining Xie 1 Ross Girshick 2 Piotr Dollar 2 Zhuowen Tu 1 Kaiming He 2
1 UC San Diego s9xie,ztu@ucsd.edu
2 Facebook AI Research rbg,pdollar,kaiminghe@fb.com
摘要
我们提出了一个简单、高度模块化的图像分类网络体系结构。我们的网络是通过重复一个构建块来构建的,该构建块聚合了具有相同拓扑结构的一组转换。我们简单的设计结果是一个同质的、多分支的体系结构,它只需要设置几个超参数。这个策略暴露了一个新的维度,我们称之为“基数”(转换集的大小),作为深度和宽度维度之外的一个基本因素。在ImageNet-1K数据集上,我们的经验表明,即使在保持复杂性的限制条件下,增加基数也能提高分类精度。此外,当我们增加容量时,增加基数比深入或扩大更有效。我们的模型,名为ResNeXt,是我们进入ILSVRC 2016分类任务的基础,我们获得了第二名。我们在ImageNet-5K集和COCO检测集上进一步研究ResNeXt,也显示出比ResNet对应集更好的结果。代码和模型在网上公开(https://github.com/facebookresearch/ResNeXt)。
引言
视觉识别的研究正经历着从“特征工程”到“网络工程”的转变[25,24,44,34,36,38,14]。与传统的手工设计特征(如SIFT[29]和HOG[5])不同,由神经网络从大规模数据中学习的特征[33]在训练过程中需要最少的人工参与,并且可以转移到各种识别任务[7,10,28]。然而,人类的努力已经转移到为学习表示设计更好的网络架构上。
随着超参数(宽度(宽度是指层中的通道数)、过滤器大小、跨距等)数量的增加,设计体系结构变得越来越困难,尤其是在有许多层的情况下。VGG网络[36]展示了一种简单而有效的构建深度网络的策略:堆叠相同形状的构建块。这种策略由ResNets[14]继承,ResNets将同一拓扑结构的模块堆叠起来。这个简单的规则减少了超参数的自由选择,深度作为神经网络的一个基本维度被揭示出来。此外,我们认为该规则的简单性可能会降低超参数过度适应特定数据集的风险。VGG网络和resnet的鲁棒性已经被各种视觉识别任务[7,10,9,28,31,14]和涉及语音[42,30]和语言[4,41,20]的非视觉任务所证明。
与VGG网络不同,初始模型家族[38、17、39、37]已经证明,精心设计的拓扑能够以较低的理论复杂度实现令人信服的精确度。初始模型是随着时间的推移而发展的[38,39],但是一个重要的共同属性是分割-转换-合并策略。在初始模块中,输入被分成几个低维的嵌入部分(通过1×1卷积),通过一组特殊的滤波器(3×3、5×5等)进行变换,然后通过级联进行合并。结果表明,该体系结构的解空间是在高维嵌入上操作的单个大层(如5×5)解空间的严格子空间。初始模块的分离-转换-合并行为有望接近大型密集层的表示能力,但计算复杂度要低得多。
尽管精度很高,但初始模型的实现伴随着一系列复杂的因素——过滤器的数量和尺寸是为每个单独的转换而定制的,模块是逐步定制的。尽管这些组件的仔细组合会产生优秀的神经网络配方,但通常不清楚如何使初始架构适应新的数据集/任务,尤其是在需要设计许多因素和超参数的情况下。
本文提出了一种简单的体系结构,采用VGG/ResNets的重复层策略,并以一种简单、可扩展的方式利用了分割-变换-合并策略。我们网络中的一个模块执行一组转换,每一个都在低维嵌入上,其输出通过求和来聚合。我们追求这个想法的一个简单实现-要聚合的转换都是相同的拓扑(例如,图1(右))。这种设计允许我们扩展到任何数量的转换,而无需专门的设计。
有趣的是,在这种简化的情况下,我们发现我们的模型有另外两种等价形式(图3)。图3(b)中的重新表述似乎类似于初始ResNet模块[37],因为它连接了多个路径;但是我们的模块与所有现有的初始模块不同,因为我们的所有路径共享相同的拓扑结构,因此可以很容易地将路径数作为要研究的因素隔离开来。在更简洁的重新表述中,我们的模块可以通过Krizhevsky等人的分组卷积[24](图3(c))进行重塑,然而,这是作为工程折衷方案而开发的。
我们从经验上证明,即使在保持计算复杂度和模型大小的限制条件下,我们的聚合变换仍优于原始的ResNet模块,例如,图1(右)的设计是为了保持图1(左)的FLOPs复杂性和参数数量。我们强调,虽然通过增加容量(深入或更广)来提高精度相对容易,但在保持(或降低)复杂性的同时提高准确性的方法在文献中并不多见。
我们的方法表明,除了宽度和深度维度之外,基数(变换集的大小)是一个具体的、可测量的维度,它是最重要的。实验表明,增加基数是获得精度的一种更有效的方法,而不是更深入或更广,特别是当深度和宽度开始给现有模型的回报递减时。
我们的神经网络名为ResNeXt(表示下一个维度),在ImageNet分类数据集上的表现优于ResNet-101/152[14]、ResNet-200[15]、Inception-v3[39]和Inception-ResNet-v2[37]。特别是,101层ResNeXt能够获得比ResNet-200[15]更好的精度,但复杂性只有50%。此外,ResNeXt展示了比所有初始模型更简单的设计。RESBAST是我们提交ILSRC 2016分类任务的基础,我们获得了第二位。本文在更大的ImageNet-5K集和COCO对象检测数据集[27]上进一步评估ResNeXt,显示出始终比ResNet对应的精度更好。我们希望ResNeXt也能很好地推广到其他视觉(和非视觉)识别任务。

图1. 左图:一块ResNet[14]。右:一个基数为32的ResNeXt块,其复杂度大致相同。图层显示为(#输入通道,过滤器大小,#输出通道)
2. 相关工作
多分支卷积网络。 Inception模型[38、17、39、37]是成功的多分支架构,每个分支都经过精心定制。ResNets[14]可以看作是两个分支网络,其中一个分支是身份映射。深层神经决策森林[22]是具有学习分裂函数的树状多分支网络。
分组卷积。 分组卷积的使用可以追溯到AlexNet的论文[24],如果不是更早的话。Krizhevsky等人给出的动机。[24]用于将模型分发到两个GPU上。分组卷积由Caffe[19]、Torch[3]和其他库支持,主要是为了与AlexNet兼容。据我们所知,很少有证据表明利用分组卷积来提高精度。分组卷积的一个特例是信道卷积,其中组的数目等于信道的数目。信道卷积是[35]中可分离卷积的一部分。
压缩卷积网络。 分解(在空间[6,18]和/或信道[6,21,16]级)是一种广泛采用的技术,用于减少深卷积网络的冗余并加速/压缩它们。Ioannou等人。[16] 为了减少计算量,提出了一种“根”型网络,根中的分支通过分组卷积实现。这些方法[6,18,21,16]已经显示出精确性与较低复杂性和较小模型尺寸之间的优雅折衷。我们的方法不是压缩,而是一种在经验上显示出更强的表现力的架构。
集成。 对一组独立训练的网络求平均值是提高精度的有效方法[24],在识别比赛中被广泛采用[33]。Veit等人[40]将单个ResNet解释为浅层网络的集合,这是ResNet加性行为的结果[15]。我们的方法利用加法来聚合一组转换。但我们认为,将我们的方法视为集合是不精确的,因为要聚合的成员是联合训练的,而不是独立训练的。
3. 方法
3.1 模板
我们采用了一个高度模块化的设计,遵循VGG/resnet。我们的网络由一堆剩余的块组成。这些块具有相同的拓扑结构,并受VGG/ResNets启发的两个简单规则的约束:(i)如果生成相同大小的空间地图,则块共享相同的超参数(宽度和过滤器大小),以及(ii)每次将空间地图向下采样时,块的宽度乘以因子2。第二条规则确保所有块的计算复杂度(浮点运算,乘法加运算)大致相同。
根据这两个规则,我们只需设计一个模板模块,就可以确定网络中的所有模块。所以这两条规则极大地缩小了设计空间,让我们可以关注一些关键因素。由这些规则构造的网络如表1所示。

表1.(左)ResNet-50。(右)使用32×4d模板的ResNeXt-50(使用图3(c)中的重新公式)。括号内是剩余块的形状,括号外是舞台上堆叠的块数。“C=32”表示分组卷积[24],共32组。这两种模型的参数数目和触发器数目相似
3.2 重温简单神经元
人工神经网络中最简单的神经元执行内积(加权和),这是由完全连接和卷积层完成的基本变换。内积可以看作是一种聚合转化的形式:
∑
i
=
1
D
w
i
x
i
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(
1
)
\\sum_i=1^Dw_ix_i.....................(1)
i=1∑Dwixi.....................(1)
其中
x
=
[
x
1
,
x
2
,
…
,
x
D
]
x=[x_1, x_2, …, x_D]
x=[x1,x2,…,xD]是神经元的D通道输入向量,
w
i
w_i
wi是第i个通道的滤波器权重。这种操作(通常包括一些输出非线性)被称为“神经元”。见图2。
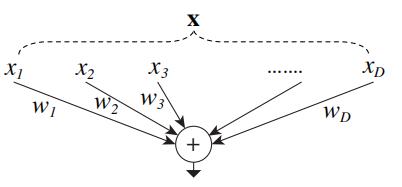
图2. 执行内积的简单神经元
上面的操作可以改写为拆分、转换和聚合的组合。(i)分裂:向量X被切成低维嵌入,在上面,它是一维维子空间 x i x_i xi。(二)变换:对低维表示进行变换,在上面,它被简单地缩放: w i x i w_ix_i wixi。(iii)聚合:所有嵌入中的转换按 ∑ i = 1 D \\sum_i=1^D ∑i=1D聚合。
3.3 聚合转换
鉴于以上对简单神经元的分析,我们考虑用一个更通用的函数代替初等变换(
w
i
x
i
w_ix_i
wixi),它本身也可以是一个网络。与“网络中的网络”[26]相比,我们发现我们的“神经元网络”沿着一个新的维度扩展。
在形式上,我们将聚合转换表示为:
F
(
x
)
=
∑
i
=
1
C
T
i
(
x
)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(
2
)
F(x)=\\sum_i=1^CT_i(x).......................(2)
F(x)=i=1∑CTi(x).......................(2)
其中
T
i
(
x
)
T_i(x)
Ti(x)可以是任意函数。类似于一个简单的神经元,
T
i
T_i
Ti应该将
x
x
x投射到(可选的低维)嵌入中,然后对其进行变换。
在等式(2)中,C是要聚合的一组转换的大小。我们称C为基数[2]。在等式(2)中,C的位置类似于等式(1)中的D,但C不必等于D,并且可以是任意数。虽然宽度维度与简单转换(内积)的数量有关,但我们认为基数维度控制更复杂的转换数量。我们通过实验证明基数是一个必要的维度,比宽度和深度维度更有效。
在本文中,我们考虑了一种设计转换函数的简单方法:所有
T
i
T_i
Ti都具有相同的拓扑结构。这扩展了VGG样式的策略,即重复相同形状的层,这有助于隔离一些因素并扩展到任何大量的转换。我们将单个转换
T
i
T_i
Ti设置为瓶颈形状的体系结构[14],如图1(右图)所示。在这种情况下,每个Ti中的第一个1×1层产生低维嵌入。
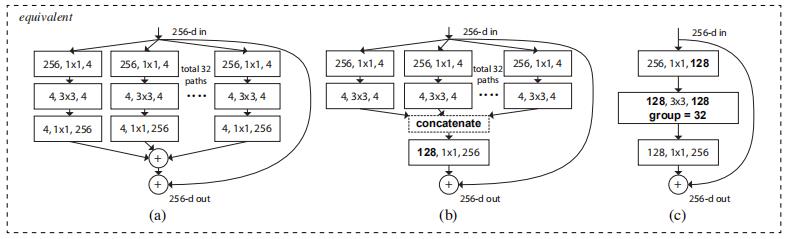
图3. ResNeXt的等效构建块。(a) :聚合剩余变换,与右图1相同。(b) :相当于(A)的块,作为早期连接实现。(c) :相当于(A,b)的块,实现为分组卷积[24]。粗体文本中的符号突出显示重新制定的更改。层表示为(#输入通道,滤波器大小,#输出通道)
等式(2)中的聚合变换用作残差函数[14](图1右):
y
=
x
+
∑
i
=
1
C
T
i
(
x
)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(
3
)
y=x+\\sum_i=1^CT_i(x)......................(3)
y=x+i=1∑CTi(x)......................(3)
其中y是输出。
与Inception-ResNet的关系。 一些张量操作表明,图1(右)(也在图3(a)中示出)中的模块等效于图3(b)(一个非正式但描述性的证据如下。注意等式:
A
1
B
1
+
A
2
B
2
=
[
A
1
,
A
2
]
[
B
1
;
B
2
]
A_1B_1+A_2B_2=[A_1, A_2][B_1;B_2]
A1B1+A2B2=[A1,A2][B1;B2],其中[,]是水平连接,[;]是垂直连接。设
A
i
A_i
Ai为最后一层的权重,
B
i
B_i
Bi为块中最后第二层的输出响应。在
C
=
2
C=2
C=2的情况下,图3(a)中的元素加法是
A
1
B
1
+
A
2
B
2
A_1B_1+A_2B_2
A1B1+A2B2,图3(b)中最后一层的权重是
[
A
1
,
A
2
]
[A_1,A_2]
[A1,A2],图3(b)中最后第二层的输出的级联是
[
B
1
;
B
2
]
[B_1;B_2]
[B1;B2])。图3(b)与初始ResNet[37]块相似,因为它涉及剩余函数中的分支和连接。但与所有Inception或Inception ResNet模块不同,我们在多个路径中共享相同的拓扑。我们的模块需要最小的额外努力来设计每个路径。
与分组卷积的关系。 使用分组卷积的表示法,上述模块变得更加简洁[24](在分组卷积层[24]中,输入和输出信道被分成C组,并且在每个组中分别执行卷积)。图3(c)说明了这种重新表述。所有低维嵌入物(前1×1层)可由单个更宽的层代替(如图3(c)中的1×1128-d)。当分组卷积层将其输入信道分成组时,基本上是由分组卷积层完成的。图3(c)中的分组卷积层执行32组卷积,其输入和输出信道是4维的。分组卷积层将它们连接起来作为层的输出。图3(c)中的块看起来像图1(左)中的原始瓶颈残余块,除了图3(c)是更宽但稀疏连接的模块。
我们注意到,只有当块的深度≥3时,重构才会产生非平凡拓扑。如果块的深度为2(例如,[14]中的基本块),则重新公式将导致一个简单的宽而密的模块。如图4所示。

图4.(左):聚合深度为2的变换。(右):一个等效的块,它稍微宽一点
讨论。 我们注意到,尽管我们呈现呈现呈现串联(图3(b))或分组卷积(图3©)的重新表述,但是这种重新表述并不总是适用于等式(3)的一般形式,例如,如果变换Ti采用任意形式并且是异质的。在本文中,我们选择使用同质形式,因为它们更简单且可扩展。在这种简化的情况下,图3©形式的分组卷积有助于简化实现。
3.4 模型容量
我们在下一节中的实验将表明,我们的模型在保持模型复杂性和参数数量的情况下提高了精度。这不仅在实践中很有趣,而且更重要的是,参数的复杂性和数量代表了模型的固有能力,因此通常被视为深层网络的基本属性[8]。 以上是关于ResNeXtAggregated Residual Transformations for Deep Neural Networks (2017) 全文翻译的主要内容,如果未能解决你的问题,请参考以下文章
当我们在保持复杂度的同时计算不同的基数C时,我们希望最小化对其他超参数的修改。我们选择调整瓶颈的宽度(例如图1(右图)中的4-d),因为它可以与块的输入和输出隔离开来。该策略对其他超参数(块的深度或输入/输出宽度)没有任何改变,有助于我们关注基数的影响。
在图1(左图)中,原始ResNet瓶颈块[14]具有
256
⋅
64
+
3
⋅
3
⋅
64
⋅
64
+
64
⋅
256
≈
70
k
256·64+3·3·64·64+64·256≈70k
256⋅64+3⋅3⋅64⋅64+64⋅256≈70k参数和比例触发器(在相同的特征映射大小上)。对于瓶颈宽度d,图1(右)中的模板具有:
C
⋅
(
256
⋅
d
+
3
⋅
3
⋅
d
⋅
d
+
d
⋅
256