论文|一种基于Embedding和Mapping的跨域推荐方法
Posted 搜索与推荐Wiki
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文|一种基于Embedding和Mapping的跨域推荐方法相关的知识,希望对你有一定的参考价值。
迁移学习(Transfer Learning)作为机器学习的一大分支,已经取得了长足的进步。在人工智能领域,无论是图像识别、NLP、搜索推荐都离不开迁移学习的身影。迁移学习的核心问题是找到源域和目标域的某种相似性,继而将已知的知识应用到目标域中。
迁移学习的一个核心要解决的问题是冷启动、数据稀疏性,当然其前提是同一个公司有不同的业务或者APP数据可以供不同部门进行使用和挖掘,比如阿里、腾讯、美团等,业务模型丰富,可以进行相应的迁移学习。
当迁移学习应用到推荐系统中时就被称为跨域推荐(Cross-Domain Recommendation)。
论文PDF地址:https://www.ijcai.org/proceedings/2017/0343.pdf
1.问题介绍
数据稀疏是推荐系统中最有挑战的问题之一,解决数据稀疏性的一种方法是交叉域推荐,它以协同的方式利用用户在多个领域的打分和feedback来提高推荐的准确性。
目前交叉域推荐分为两种类型:
-
一种是非对称的方式,利用附加域中的数据来解决目标域的数据稀疏性,具体来说是把在附加域中学到的知识或者某种模式直接应用到目标域中充当先验或者正则。这种方法的关键之处是需要从附加域数据中识别出可以应用到目标域的知识。然而因为没有完全利用附加域和目标域的数据,所以是有很大局限的。
-
另外一种是对称的方式,假设附加域和目标域都有数据稀疏的问题,并且它们可以互相应用对方的数据知识。以这种方式来看,这两个域是可以同等对待的,两个域都以协同的方式应对数据稀疏问题。通常这种方式会在域之间学习一个mapping函数,把域独有的因子和域间共享的因子明确区分开来,主要的缺点是学习域独有的因子和域间共享的因子本身就放大了数据的稀疏性问题。
这篇论文作者从embedding和mapping的角度研究交叉域学习问题,也就是对称的方式。作者研究了交叉域推荐的2个主要问题:
- 怎样表示交叉域的mapping函数,linear or nonlinear?
- 是所有的数据还是只有部分数据用来学习mapping函数呢?
虽然非线性函数可以学习到更复杂的交叉域mapping关系,但是这也意味着需要更多的数据,而且对于数据稀疏的交叉域来说,非常容易过拟合。另外,研究表明在2个域中都不是很活跃的用户对于mapping函数的学习是不利的。针对这些问题,作者提出了EMCDR模型。
- 隐向量建模
- 隐空间的mapping
- 交叉域推荐
2.EMCDP模型
2.1 概述
假设我们有2个域,它们共享用户或者物品,只在一个域中出现的用户或者物品可以被认为是另外一个域中即将来的用户或者物品。这两个域都可以为源域或者目标域。
该模型包含三部分:
- 隐向量建模
- 隐空间的mapping
- 交叉域推荐
其模型结构为:
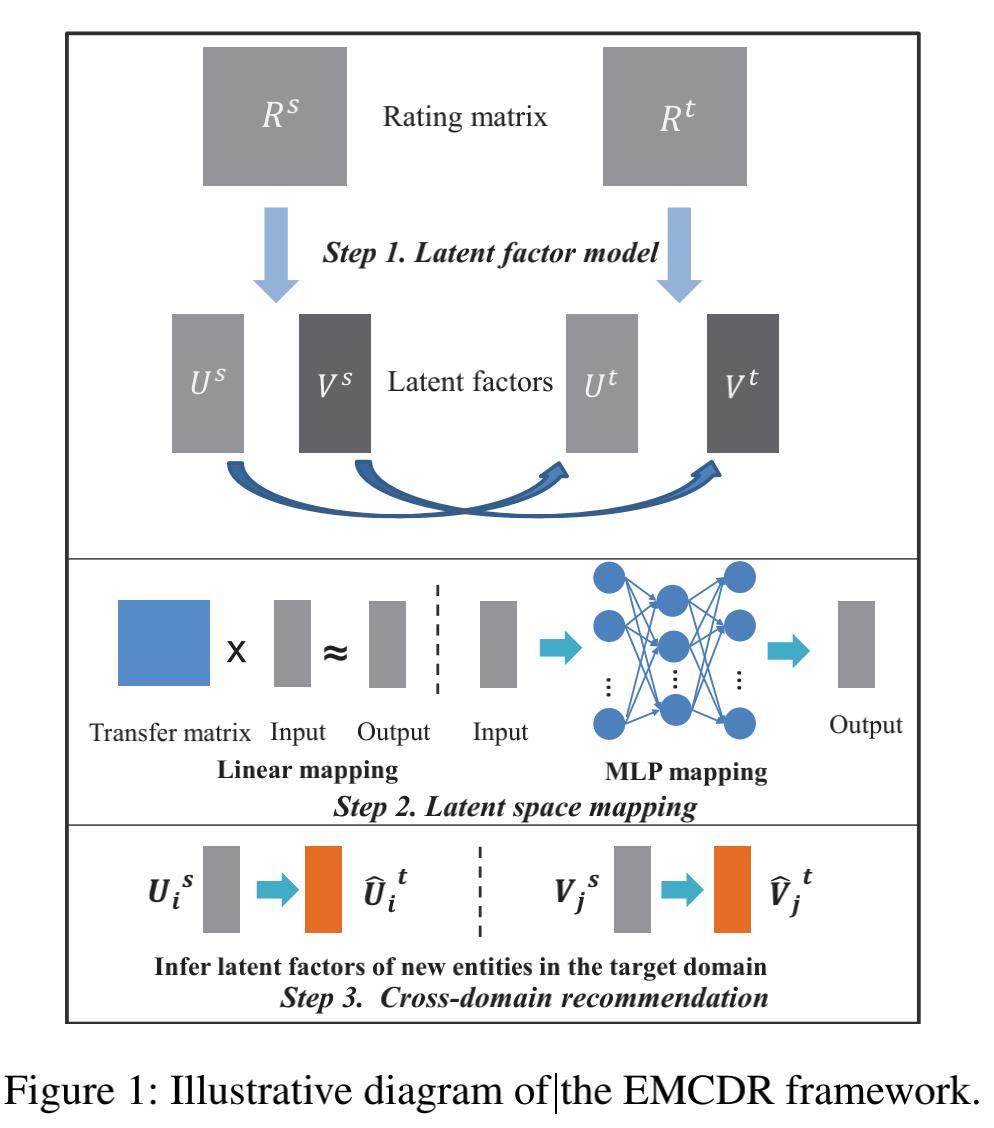
其推荐算法流程为:

2.2 隐向量模型
模型的第一步是学习user、item的向量,论文中采用了两种方式来构建隐向量:MF、BRP
2.2.1 MF
把打分矩阵分解成2个低维矩阵的乘积,假设打分是服从高斯分布的,给定一对user和item,它们的得分概率建模如下:
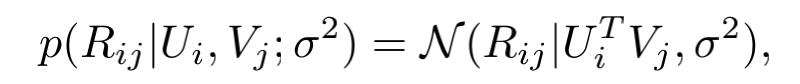
MF的优化目标是:
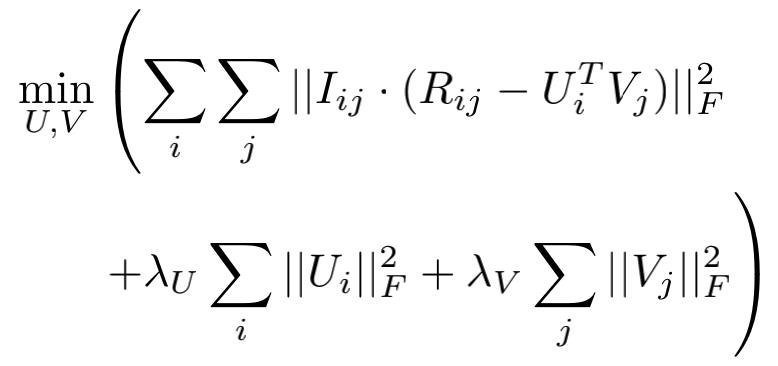
优化函数使用的是:随机梯度下降(stochastic gradient descent,SGD),MF对应的更新函数为:
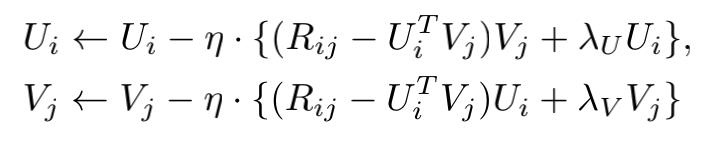
2.2.2 BRP
不同于MF优化基于目标函数的打分,BPR优化基于目标函数的rank,BPR的数据集重新构建为:
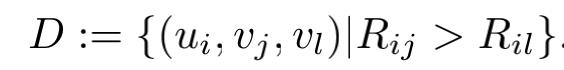
对于给定的一对数据,BRP的建模方式为:
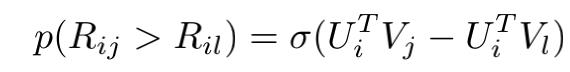
BRP的优化目标为:
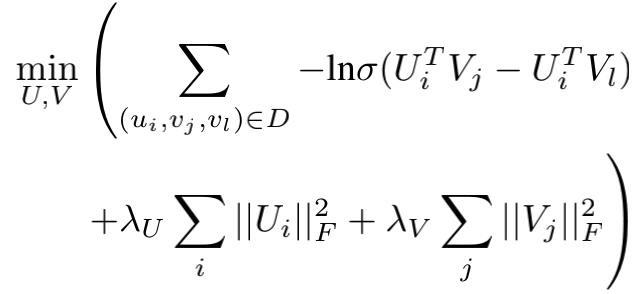
BRP使用的也是SGD优化函数,其参数对应的更新函数为:
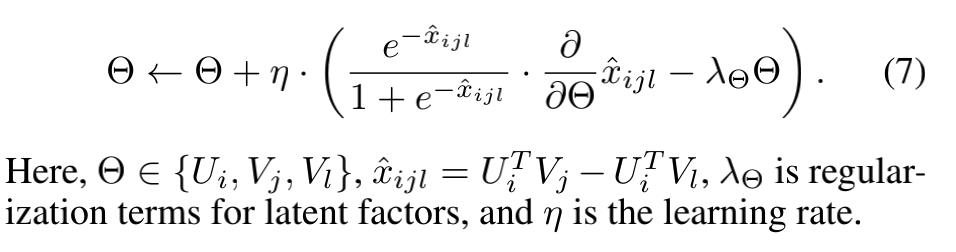
2.3 隐空间mapping
EMCDP算法假设不同域之间是存在映射的,最上边提到这种映射函数包括线性的非线性的,同样论文中也提到了两种不同的mapping函数,假设用户侧和item侧的映射函数表达式为:
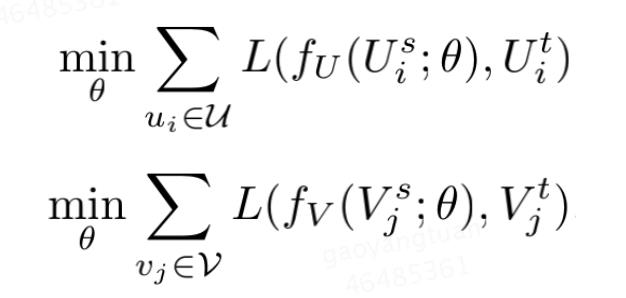
2.3.1 Linear Mapping
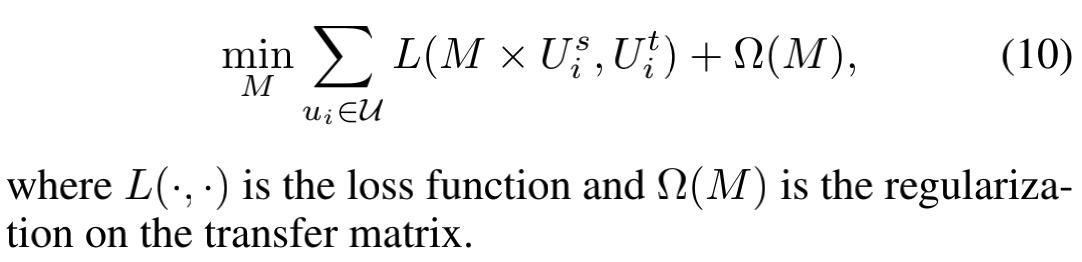
其中 M M M 为迁移矩阵
2.3.2 MLP-based Nonlinear Mapping
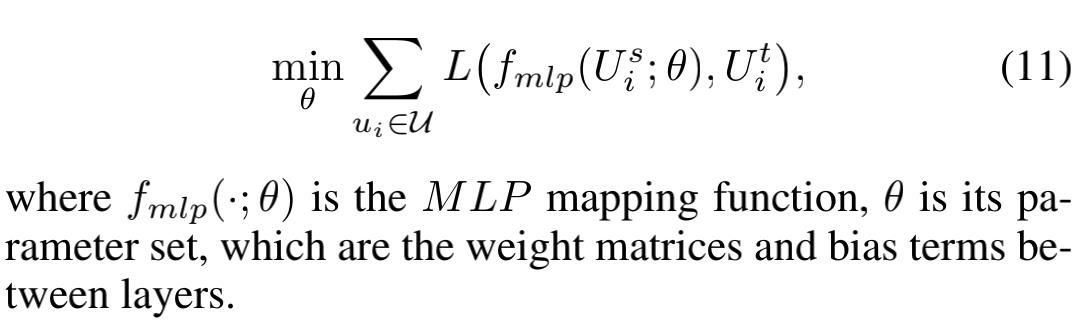
2.4 交叉域推荐
对于目标域中信息很少的用户和物品,直接使用MF或者BPR建模出的隐向量是不准确的,有很大偏差,这时可以使用源域建模出的隐向量以及mapping函数来建模。
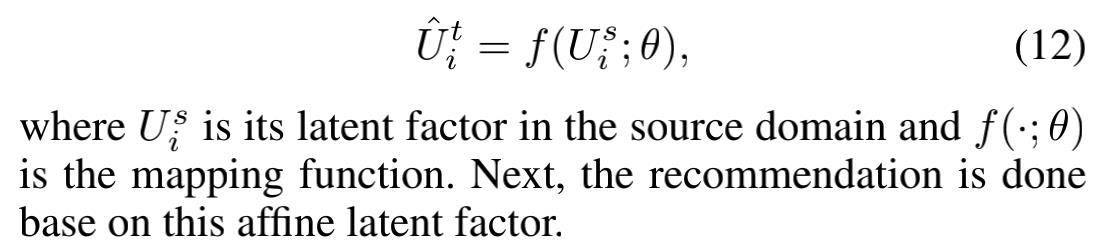
3.实验
使用采用的数据集是MovieLens-Netflix和豆瓣books-movies,其中Netflix数据集和MovieLens数据集中有5000多电影是共享的,但是用户有很大区别,所以是item-based交叉域。作者把MovieLens当作源域,Netflix当作目标域。
Douban上可以提取出基于user的交叉域。user都对books和movies打分,作者把movies当作源域,books当作目标域。

实验预处理:作者随机删除了目标域中的一部分实体(item或者user)的打分信息,并把这些删除的实体作为目标域推荐的冷启动实体。
论文中提出了四种模型(上文提到的两种lfm和两种mapping):
- MF_EMCDR_LIN
- MF_EMCDR_MLP
- BRP_EMCDR_LIN
- BRP_EMCDR_MLP
对比了几种模型
- AVE:对于目标域中的冷启动实体,用目标域中所有实体的平均打分来代替
- CMF:源域和目标域中实体的隐向量是共享的
- CST:把源域中学到的隐向量映射到目标域中
- LFM:每个实体在交叉域中有个全局的共享隐向量,每个实体在每个域中的隐向量是全局共享隐向量乘以每个域的转化矩阵得到
实验结果(其中K表示的是隐向量的长度)
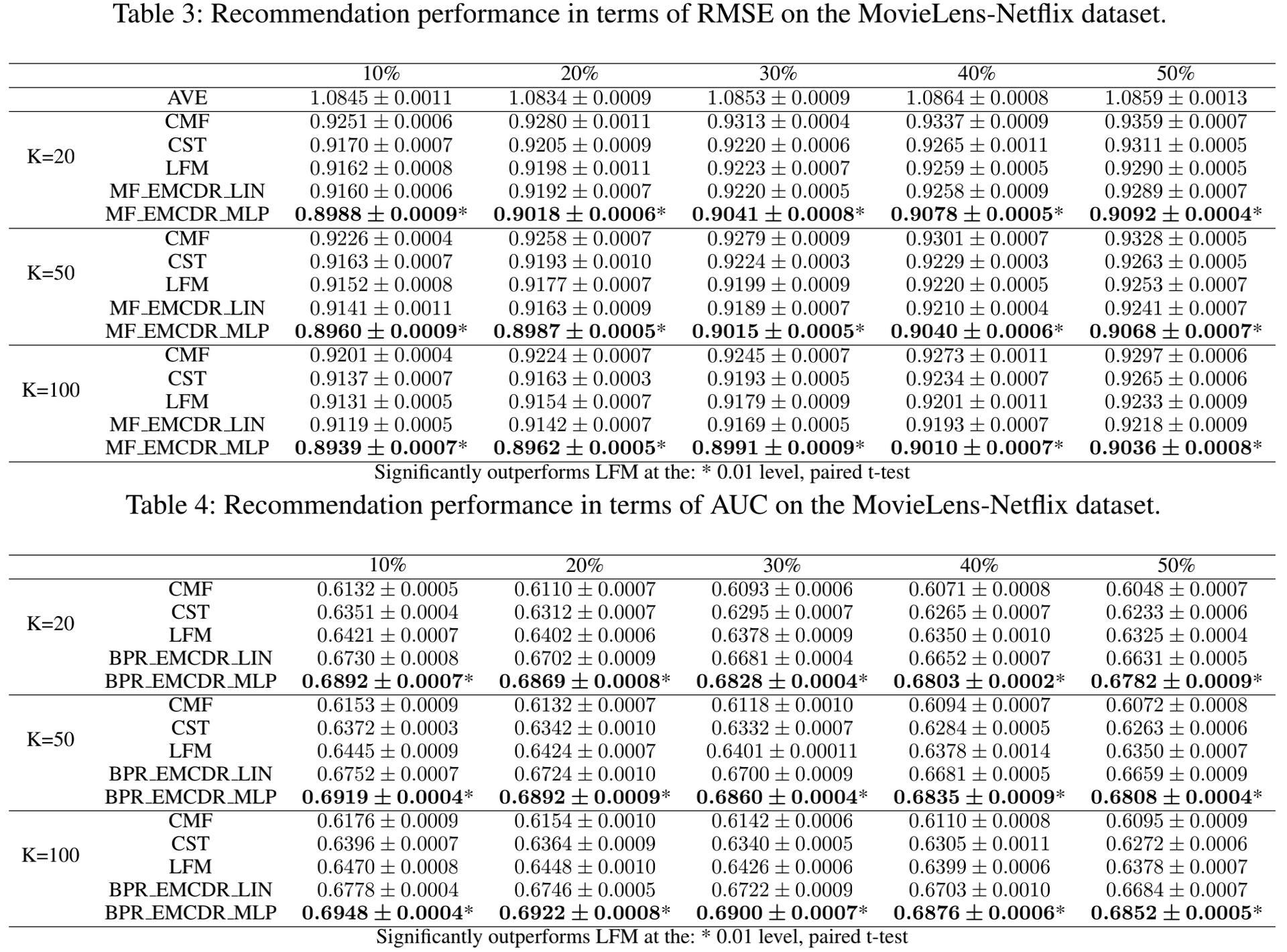
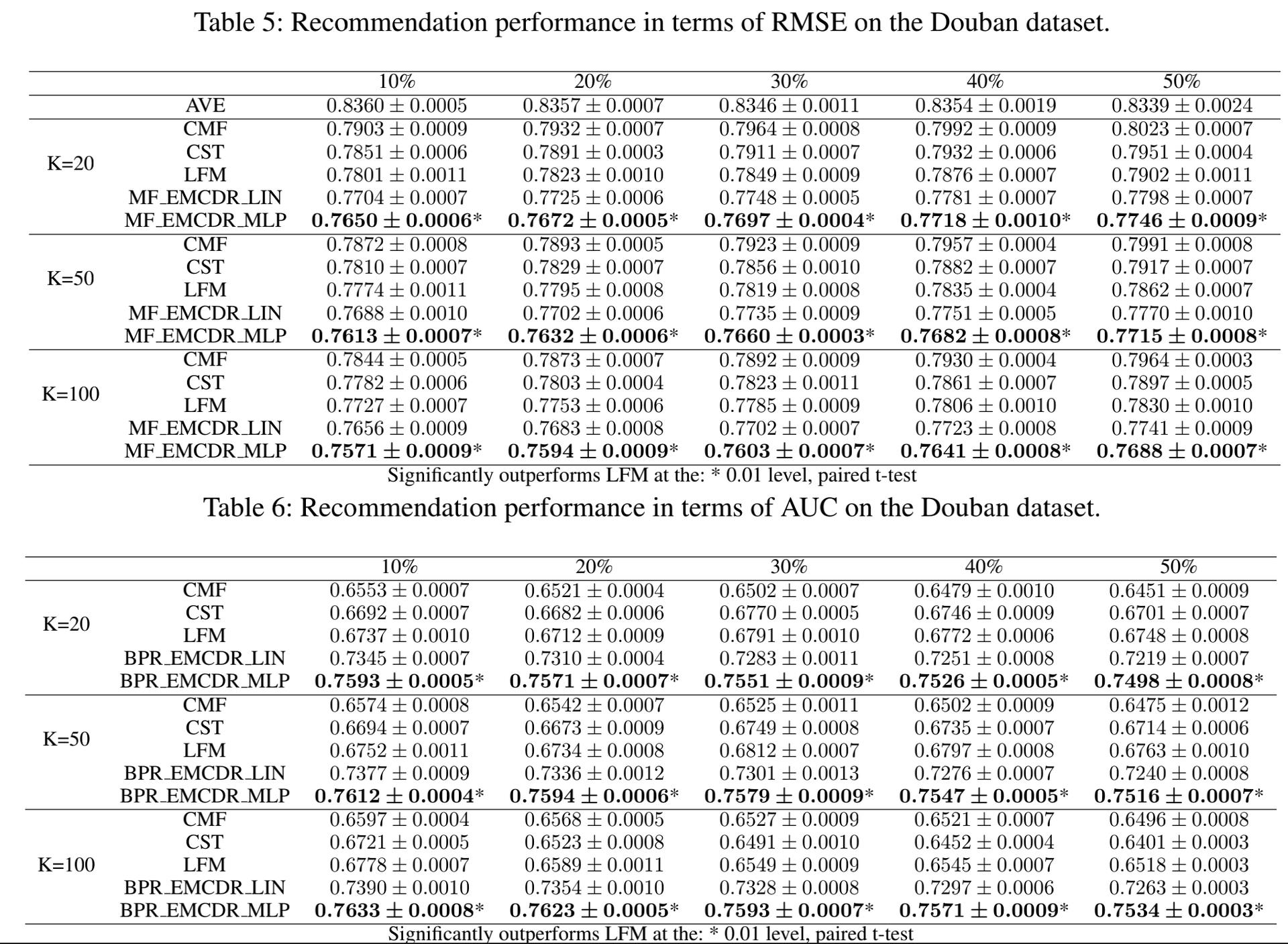
mapping的对比:
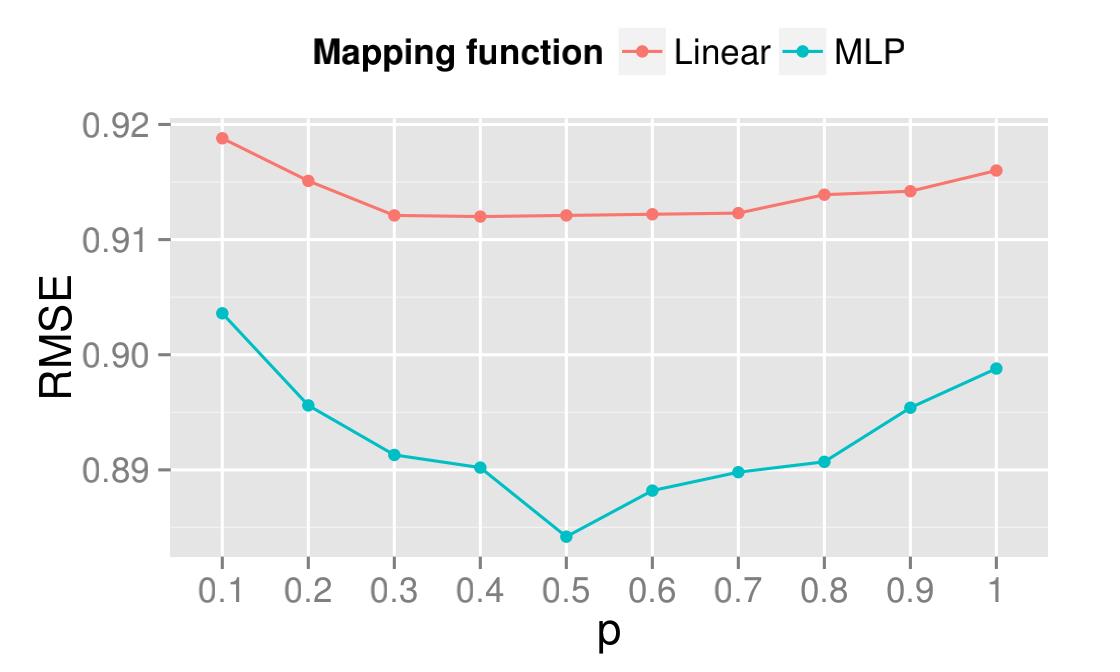
p=0.1表示选取前10%的活跃实体学习mapping函数,可以看到数据太少和太多的话学到的mapping函数都不是很好,说明不太活跃的实体不利于mapping函数的学习,而太少的数据不能有效的捕获到交叉域间的信息。非线性的mapping函数更有利于捕获交叉域间的关系。
4.总结
作者利用mapping函数来解决交叉域推荐问题,主要是对冷启动物品或者用户用交叉域信息作为一种附加信息,而非冷启动用户和物品仍然用原来的域信息。和之前研究中目标域中所有的用户和物品都通过mapping从源域映射到目标域不同,因为这种映射还是有一定偏差的,所以只对冷启动物品和用户采用mapping比较合理,实验也表明这种效果会更好一些。
扫一扫关注「搜索与推荐Wiki」!号主「专注于搜索和推荐系统,以系列分享为主,持续打造精品内容!」
以上是关于论文|一种基于Embedding和Mapping的跨域推荐方法的主要内容,如果未能解决你的问题,请参考以下文章
每日一读Community preserving mapping for network hyperbolic embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
论文笔记之: Deep Metric Learning via Lifted Structured Feature Embedding