MySQL高级篇——索引失效案例
Posted 张起灵-小哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL高级篇——索引失效案例相关的知识,希望对你有一定的参考价值。
文章目录:
1.7 is null可以使用索引,is not null无法使用索引
1.案例分析
1.1 数据准备
这里主要用到的是 class、student 这两张表。
CREATE DATABASE atguigudb2;
USE atguigudb2;
#建表
CREATE TABLE `class` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`className` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
`monitor` INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`stuno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`classId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_class_id` FOREIGN KEY (`classId`) REFERENCES `t_class` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
SET GLOBAL log_bin_trust_function_creators=1;
#随机产生字符串
DELIMITER //
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER ;
#用于随机产生多少到多少的编号
DELIMITER //
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num - from_num+1)) ;
RETURN i;
END //
DELIMITER ;
#创建往stu表中插入数据的存储过程
DELIMITER //
CREATE PROCEDURE insert_stu( START INT , max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0; #设置手动提交事务
REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, NAME ,age ,classId ) VALUES ((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE insert_class( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES (rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
SELECT COUNT(*) FROM class;
SELECT COUNT(*) FROM student;#首先确保student表中只有一个主键对应的索引
SHOW INDEX FROM student;
1.2 全值匹配
我们先对age字段单独建一个索引,执行下面这三条sql,它们都会走这个索引。
CREATE INDEX idx_age ON student(age);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
CREATE INDEX idx_age_classid ON student(age,classId);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
CREATE INDEX idx_age_classid_name ON student(age,classId,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
1.3 最左前缀法则
这里肯定会用到我们上面创建的age单列索引。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd' ;
下面这个,必然用不上我们上面创建的那三个索引的,因为联合索引中是先依赖 age、classId、NAME 建立的B+树。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student.name = 'abcd';
这里的三个字段对应了联合索引中的三个字段,这里是可以交换位置的。
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE classid=4 AND student.age=30 AND student.name = 'abcd'; 
接下来,我们删除两个索引,留下三个字段的那个联合索引,看看效果。
由于先走age,age相同再走classId,这里没有classId了话,那么就直接去走NAME了,所以可以用上这个联合索引的。但是后面的key_len为5,表示只用上了联合索引中的age这部分(INT类型4个字节 + 非空NULL1个字节 = 5个字节),并没有用到NAME。
DROP INDEX idx_age ON student;
DROP INDEX idx_age_classid ON student;
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.name = 'abcd'; 

1.4 计算、函数、类型转换(自动或手动)导致索引失效
先针对NAME字段建一个单列索引,以便下面测试。
CREATE INDEX idx_name ON student(NAME);#此语句比下一条要好!(能够使用上索引)
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%';
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc'; 这里不会走索引,其实是因为用了LEFT函数之后,我又不知道name在经过LEFT函数之后是什么样的,还怎么走B+树呢?

下面,我们再针对stuno建一个索引。 (计算也会导致索引失效)
CREATE INDEX idx_sno ON student(stuno);EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;
下面演示一下 类型转换 导致索引失效的问题。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = 123; 
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = '123'; 
1.5 范围条件右边的列索引失效
首先将多余的索引删除,只保留主键对应的那个索引。
DROP INDEX idx_sno ON student;
DROP INDEX idx_name ON student;
DROP INDEX idx_age_classid_name ON student;
SHOW INDEX FROM student;
CREATE INDEX idx_age_classId_name ON student(age,classId,NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId>20 AND student.name = 'abc' ; 这里的确是可以用到上面创建好的这个索引,但是它的key_len=10,原因就是:age(INT 4个字节 + 非空 1个字节)=5个字节,classId和age一样,此时就是 5 + 5 = 10个字节,那么前两个都用到了,为什么联合索引的第三个NAME没有用到呢?这是因为classId这里是一个范围条件,在它右侧的那些字段将不会使用索引。

那么如果还是上面这个问题,我们想用到联合索引的所有字段,应该怎么优化呢?👇👇👇
我们将可以进行等值判断的字段放在联合索引的最左侧、最前面,就可以了。
下面测试的key_len为73表示就是全用上了(两个INT:4 + 1 + 4 + 1 = 10,一个VARCHAR20:20*3 + 1 + 2 = 63),最终10 + 63 = 73。
这里如果颠倒WHERE子句中的筛选条件也是可以的,因为查询优化器会在这里进行自动交换,尽量满足联合索引的情况。(在联合索引中,尽量把与范围查询相关的字段放在后面)
CREATE INDEX idx_age_name_cid ON student(age,NAME,classId);
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.name = 'abc' AND student.classId > 20;
EXPLAIN SELECT SQL_NO_CACHE * FROM student
WHERE student.age=30 AND student.classId > 20 AND student.name = 'abc'; 
1.6 不等于(!= 或者<>)索引失效
CREATE INDEX idx_name ON student(NAME);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> 'abc' ;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != 'abc' ;
1.7 is null可以使用索引,is not null无法使用索引
SHOW INDEX FROM student;
首先可以看到,student表中是存在针对 age 字段的索引的,下面测试:👇👇👇
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL; 
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;

1.8 like以通配符%开头索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE 'ab%'; 
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE '%ab%';这个其实好理解,你以%开头进行模糊查询,上来都不知道具体是什么?那你到B+树中怎么查找啊?


1.9 OR前后存在非索引的列,索引失效
DROP INDEX idx_age_name_cid ON student;
DROP INDEX idx_name ON student;
DROP INDEX idx_age_classid_name ON student;
SHOW INDEX FROM student;
CREATE INDEX idx_age ON student(age);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
CREATE INDEX idx_cid ON student(classid);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;
1.10 数据库和表的字符集统一使用utf8mb4
统一使用 utf8mb4( 5.5.3 版本以上支持 ) 兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。不同的 字符集 进行比较前需要进行 转换 会造成索引失效。
2.结束语
假设我们创建了一个联合索引 all_index(a, b, c)。
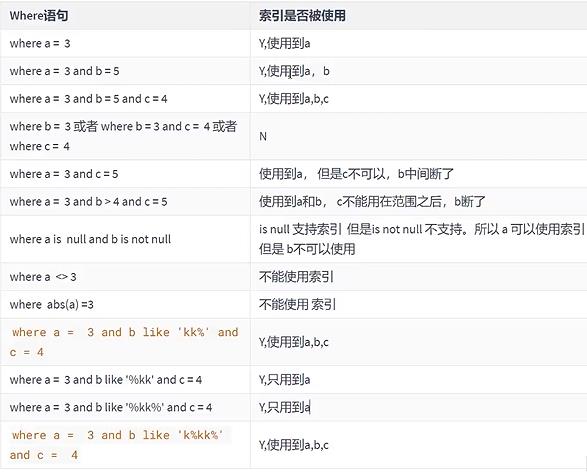

以上是关于MySQL高级篇——索引失效案例的主要内容,如果未能解决你的问题,请参考以下文章
MySQL从入门到精通高级篇(二十六)建了索引就能用么?我看未必。来看看几种索引失效的情况吧