Java高级知识点:并行计算(外部排序) 及 死锁分析
Posted 鸽一门
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java高级知识点:并行计算(外部排序) 及 死锁分析相关的知识,希望对你有一定的参考价值。
一. 并行计算(外部排序)
通常单机运算时将数据放入内存中进行计算,但随着数据量的增大,最好是使用并行计算的方法。
1. 如何设计并行排序算法?
在并行计算的工作中,将每一个参与的电脑当作一个节点,节点通常是比较廉价的,可通过增加节点来提高效率。分为以下三个步骤及待解决问题:
- 将数据拆分到每个节点上(如何拆分,禁止拆分数据依赖)
- 每个节点并行计算得出结果(每个节点要算出什么结果?)
- 将结果汇总(如何汇总?)
接下来以一个典型例子——外部排序,如何排序10G个元素?
熟悉算法的肯定知道排序算法中效率较优的快速排序、归并排序,它们时间复杂度为O(n*logn)。使用这些高效算法来对10g个元素排序,也只需要几分钟的时间,但是问题在于内存大小限制,无法一次性将所有元素放入一个大数组中!只能一部分放在放在内存数组中,另一部分放在内存之外(硬盘或网络其它节点),这就是所谓的外部排序。
2. 归并排序算法
其中外部排序会使用到扩展的归并排序,来简单回顾归并排序核心:将数据分为左右两部分,分别排序,再把两个有序子数组进行归并。此算法重点就是归并过程,就是两个已排序好的数组来比较头部的元素,取最小值放入最终数组中。查看以下动画理解:

3. 外部排序算法
(1)三个步骤
其实扩展后的归并排序算法思想可用于外部排序中,核心算法分为以下三个步骤:

- 第一步:将数据进行切分,例如以100m或1g元素为1一组,将每一段数据分配到节点进行排序,切分的大小符合节点内存大小限制。
- 第二步:这样每个节点各自对分配数据进行排序,采用归并排序或快速排序皆可。
- 第三步:将每个排序好的节点按照归并算法整合到一个节点。
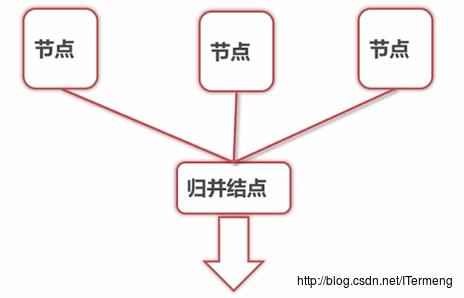
(2)k路归并算法实现 —– 堆(PriorityQueue)
其中第一、二步实现较容易,重点在于如何将多个节点归并到一个节点,也就是 k路归并。如下图所示,归并算法为不断比较各个节点的头元素,取最小值放入最终节点中,可是如何比较k个头结点(下图中的2,1,3,4)?

逐个比较则效率较低,熟悉数据结构的朋友此时应该想到一个数据结构——堆!堆是一棵二叉树,具有以下特点:
- 在二叉树上任何一个子节点都不大(或小于)于其父节点。
- 必须是一棵完全的二叉树,即除了最后一层外,以上层数的节点都必须存在并且要集中在左侧。
所以依据堆的特点,我们可以构造一棵最小二叉堆,使得头结点一定是最小值,于是构造一个大小为k的堆,先将k个节点的头元素插入到堆中,然后每次取出头结点,取出来的元素属于哪个子数组,再添加这个子数组的下一个元素进入堆中,来维护这个堆。
一般在编码实现中无需重新构造堆结构,可直接使用库中对应的 PriorityQueue优先队列,将k个头结点push进队列,然后pop出头结点,同时push进该头结点对应子数组的一个元素。以上就是算法核心,其中push、pop操作都是O(logk)。
(3)缓冲区
但是,仍然存在一个问题:每个节点的内存可以分别容纳数据,可是将所有节点归并到一个节点时,又回到了10G,不可能全放入内存,到底在内存中放入多少?
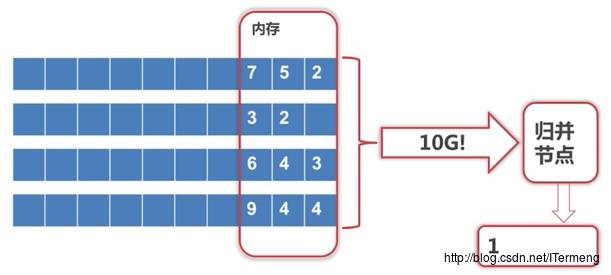
其实只需将每个节点的最小值放入内存即可,例如上图中2,1,3,4放入内存,但是把最小值1拿掉之后需要补充一个元素,将外部内存的2拿到内存里来,可是外部内存可能在硬盘或网络,此过程相比内存操作会很慢,不断读取外部内存效率很低,所以采用缓存区,每次读取k个节点前部分数据到缓存区(几k或几M)。
4. 思考编码实现
以上思想理解后,考虑发现其代码实现并不容易,首先要实现归并算法,还要维护PriorityQueue的数据结构,获取数据的数据源有内存、外部内存(硬盘)。
所以归并通过Iterable接口实现,可实现以下功能:
- 可以不断获取下一个元素的能力;
- 元素存储/获取方式被抽象,与归并节点无关;
- Iterable merge(List< Iterable> soretedData);
- Iterable是架与内存和文件层次上;

为了展示Iterable接口的功能强大,举个例子Iterable.next()作用如下:
归并数据源来自 Iterable.next(),首先从每个节点调用Iterable<T>.next()获取它们最小的元素,然后push到PriorityQueue中,完毕后不断pop元素,同时补充上对应数据源的后续元素。具体查看Iterable<T>.next()操作:
- 如果缓存区空,读取下一批元素放入缓存区;
- 给出缓存区第一个元素;
- 可配置项:缓存区大小,如何读取下一批元素;
优点:首先归并节点的时候不需要考虑缓冲区的问题,只需要调用其next()方法,在可配置项中设定如何读取,这样归并函数只需写一次,可用在文件上或网络上,主要实现被抽象出来。
5. 总结
将归并排序扩展到外部排序的场景中,实现上有两大重点:采用堆的数据结构(库中的PriorityQueue)来实现归并过程;使用Iterable接口实现数据源的缓冲区。
二. 死锁分析
多线程中最值得关注的是线程安全性,同一个数据在不同线程中被同时读写会出现问题,需要保证数据的安全性对其线程进行加锁操作,但是锁太多效率会降低,因此将锁的范围缩小,可是又会产生死锁的问题。以一个常见的银行取钱例子来分析防止死锁。
void transfer(Account from, Account to, int amount)
from.setAmount(from.getAmount() - amount);
from.setAmount(to.getAmount() + amount);
一个很简单的transfer函数,模拟银行转账需求,此函数在单线程上绝对安全,但是在多线程下会出现问题,例如两个人同时在这个账号转钱,可是此账号只扣了一次钱,必然是不合理的,所说对其进行加锁,如下代码:
void transfer(Account from, Account to, int amount)
synchronized(from)
synchronized(to)
from.setAmount(from.getAmount() - amount);
from.setAmount(to.getAmount() + amount);
将from、to加锁,这样第一个在操作账户转钱结束之前,第二个人是无法操作的。synchronized是针对对象的,同一个账户不可多线程操作。但是以上代码是会产生死锁的:
- 在任何地方都可以线程切换,甚至在一句语句中间。
例如from.setAmount(from.getAmount() - amount);这样一行代码,在from.getAmount() 地方或减号之后会断掉,但是在上锁之后即使断掉,别的用户也进不来。
- 尽力设想最坏的情况
当from对象被别人锁住的,我们无法上锁,这种情况是有利的,只需等待别的线程做完即可。但是我们刚锁完from对象,别的线程就在等待,这才是不利的情况。那to对象同理吗?不是!如果to对象被我们上锁,这样我们同时拥有两个对象的锁,可以进行操作了;而to对象的锁被别的线程锁了,我们需要等待,这才是不利的!
死锁出现的场景
根据以上分析总结一下最坏的情况:
- synchronized(from):别的线程在等待from对象;
- synchronized(to):别的线程已经锁住了to对象;
因此,可能出现死锁的情况就是: transfer(a,b,100) 和 transfer(b,a,100)同时进行,这是对双方都很不利的情况:左边的抢走了a的锁,右边的抢走了b的锁。
形成死锁的条件
- 互斥等待:说白了也就是要在有锁的情况。
- hold and wait:拿到一个锁去等待另一个锁的状态,其实锁是很珍贵的资源,最好得到锁后尽快处理完毕将其释放。
- 循环等待:更槽糕的情况:例如线程1获得锁A在等待锁B,而线程2获取锁B在等待锁A。
- 无法剥夺的等待:在出现循环等待情况后,有的锁会出现超时后自动释放,但是若是一直等待,则必定死锁。
防止死锁的办法
若要避免死锁,根据以上四个产生死锁的原因,逐一破解即可:
破除互斥等待:不可!锁是保证线程安全的基本方法,无法实现。
破除hold and wait:可以!最关键的一步,就是一次性获取所有资源。例子中的from、to对象是分成两步获取的,从而会形成hold and wait情况,但是通常不允许同时锁两个对象,因此需要对代码做比较大的修改:
- 暴露一个锁名为getAmountLock,它是针对Amount的,from、to对象都可以getAmountLock,锁的时候可以带上一个短的超时,先锁住from再锁住to,当to锁不住的时候,把from锁放掉,过段时间再尝试。
- 或者在这两行的外面加一个全局的锁,保证可以同时拿到这两个锁,拿到这两个锁之后再将全局的锁释放掉。但是需要结合实际,银行系统中Amount的量很大,全局锁未必好,第一个方案较好。
破除循环等待:可以!按顺序获取资源。
- 让例子中的Amount之间有序,不要先synchronized对象from,再synchronized对象to,银行中AmountID肯定是惟一值,所以定制一个规则先处理较小值,这样即使同时互相转账,也不会出现死锁情况。
破除无法剥夺的等待:可以!加入超时。
- 设置超时时间5秒或者其它,但此方法并不理想,因为超时需要时间等待,耗时长,用户体验差。
总结
根据以上的分析,也许你认为第四种加入超时措施相对简单实现,但是如此一来不能使用synchronized,还要暴露一个锁;第二种 from.getAmountLock()方法实现较复杂。
因此,第二种解决方法较好,即破除循环等待—–按顺序获取资源,出现并发时根据AmountID值先处理值较小的用户,但是这并不是最好的解决方法,因为此解决方法重点为按顺序获取资源,而银行账户中的ID顺序性是我假设出来的,并非实际。
所以,最理想的解决方法还是破除hold and wait,就是一次性获取所有资源!但是通常不允许同时锁两个对象,所以还是先锁住A再锁住B,当B锁不住的时候,把A锁放掉,过段时间再尝试。
完美的解决办法不存在!所以只能根据实际问题具体分析,选择一个折中的办法实现。
若有错误,虚心指教~
以上是关于Java高级知识点:并行计算(外部排序) 及 死锁分析的主要内容,如果未能解决你的问题,请参考以下文章